

O LLM Dedicated Endpoint da Novita AI é um serviço recém-lançado que permite que você implemente seus próprios modelos Hugging Face personalizados ou ajustados com facilidade.
Com GPUs H100 dedicadas a partir de US$ 1,86/h e H200 a partir de US$ 2,99/h, a Novita AI oferece preços altamente competitivos — muitas vezes mais econômicos que alternativas como Together AI, Fireworks AI e Friendli AI.
Desfrute de suporte flexível para LoRA, um SLA de 99,5% e opções escaláveis de GPU. Configure endpoints LLM prontos para produção em minutos e gerencie seus recursos com tranquilidade, com preços transparentes e previsíveis.
O que é o LLM Dedicated Endpoint?
Um LLM Dedicated Endpoint fornece uma API privada baseada em nuvem para executar grandes modelos de linguagem em uma infraestrutura reservada exclusivamente para seu uso. Essa configuração garante que seus modelos operem com desempenho consistente, alta confiabilidade e isolamento total de recursos — ao contrário de alternativas compartilhadas ou serverless.
Com um endpoint dedicado, você pode implantar modelos de código aberto e privados no Hugging Face, incluindo suas variantes personalizadas ou ajustadas. Dados confidenciais e propriedade intelectual permanecem protegidos, pois seus modelos e tráfego nunca são expostos a outros usuários.
Por que escolher o LLM Dedicated Endpoint?
Com o LLM Dedicated Endpoint da Novita AI, você obtém um ambiente robusto e flexível para suas cargas de trabalho de IA:
- Implantação de modelos personalizados: Sirva facilmente qualquer modelo do Hugging Face, incluindo versões privadas e ajustadas, em um ambiente isolado e dedicado.
- Gerenciamento flexível de adaptadores LoRA: Anexe e alterne entre vários adaptadores LoRA em um único endpoint. Experimente, itere e suporte tarefas diversas sem reimplantar seu modelo base.
- Desempenho previsível: Recursos dedicados garantem throughput consistente e baixa latência, sem serem afetados por outros usuários. Não há limites rígidos de taxa; a capacidade do seu endpoint é determinada pelo hardware e configuração escolhidos.
- Hardware escalável: Escale de ocioso (0 réplicas) até 10 réplicas por endpoint e escolha o tipo de GPU que atende às suas necessidades. Cada usuário pode acessar até 8 GPUs, com expansão empresarial disponível.
- Preços transparentes: H100 a partir de US$ 1,86/h, H200 a partir de US$ 2,99/h — pague apenas pelo que usar. Endpoints dedicados costumam ser mais econômicos que soluções serverless em uso alto ou sustentado.
- Gerenciamento amigável: Console web intuitivo para implantação e gerenciamento, além de testes instantâneos no Playground para validação rápida.
- Confiabilidade pronta para produção: Garantia de uptime de 99,5%, totalmente gerenciada pela Novita AI para sua tranquilidade.
Como escolher: Endpoint Dedicado vs. Endpoint Serverless
Selecionar o tipo certo de endpoint de inferência LLM depende do seu caso de uso, carga de trabalho e requisitos operacionais. Aqui está um guia rápido para ajudar na decisão:
Escolha o LLM Serverless Endpoint se:
- Você deseja acesso rápido e flexível a LLMs públicos sem gerenciamento de infraestrutura.
- Seu uso é baixo, variável ou para prototipagem.
- Você prefere um preço simples de pagamento por uso.
Escolha o LLM Dedicated Endpoint se:
- Você deseja implantar qualquer modelo do Hugging Face (incluindo privados, ajustados ou com acesso restrito).
- Você precisa configurar adaptadores e parâmetros LoRA de forma flexível.
- Você exige hardware dedicado, throughput alto estável e confiabilidade de nível de produção.
- Você deseja otimizar para o menor custo de GPU do setor.
- Você precisa de até 8 GPUs por usuário, ou mais.
Se precisar de mais recursos, entre em contato com nossa equipe de vendas para uma solução empresarial personalizada.
| Aspecto | LLM Serverless Endpoint | LLM Dedicated Endpoint (DE) |
| Modelo de cobrança | Pagamento por uso (por token) | Pagamento por GPU por hora |
| Tipo de recurso | Compartilhado, serverless (multilocatário) | Dedicado, controlado pelo usuário (locatário único) |
| Consistência de desempenho | Pode variar (carga compartilhada) | Previsível, não afetado por outros usuários |
| Limites de taxa | Sim (TPM, RPM por nível de usuário) | Sem limites rígidos; limitado pela cota de GPU do usuário |
| Seleção de modelo | Apenas modelos públicos | Carregar modelos base personalizados de repositórios Hugging Face (públicos, privados ou com acesso restrito); suporta configuração de parâmetros LoRA |
| Escolha de hardware | Não selecionável | Flexível: H100, H200, 4090, etc. |
| Região de implantação | Não selecionável pelo usuário | O usuário pode escolher a região |
| SLA | Sem garantia formal | SLA de 99,5% |
| Custo em alta utilização | Mais caro em escala | Mais barato em alta utilização |
| Segurança e isolamento de dados | Ambiente compartilhado | Isolamento total do locatário, endpoints privados |
| Ideal para | Startups, prototipagem, uso variável | Empresas, produção, throughput alto estável, modelos base personalizados |
Comparação de preços de GPU para Endpoint Dedicado
Ao escolher um provedor, a eficiência de custo é crucial — especialmente para implantações em escala de produção. A Novita AI oferece as taxas horárias mais baixas para GPUs H100 e H200 dedicadas entre os principais provedores:
| Provedor | H100 (1 cartão/H) | H200 (1 cartão/H) |
| Novita AI | US$ 1,86 | US$ 2,99 |
| Fireworks AI | US$ 5,80 | US$ 9,99 |
| Friendli AI | US$ 4,90 | US$ 5,90 |
| Together AI | US$ 3,36 | US$ 4,99 |
| Deepinfra | US$ 2,40 | US$ 3,00 |
Como mostrado acima, a Novita AI oferece consistentemente os preços mais competitivos para GPUs H100 e H200 — até 60% mais baixos que outros provedores populares.
Isso significa que você pode reduzir significativamente os custos de infraestrutura para implantações de LLM de alto throughput ou longa duração escolhendo a Novita AI.
Como começar com os LLM Dedicated Endpoints da Novita AI
1. Acesse o Console
- Faça login no seu Console Novita AI.
- Na barra lateral esquerda, clique em LLM Dedicated Endpoints.
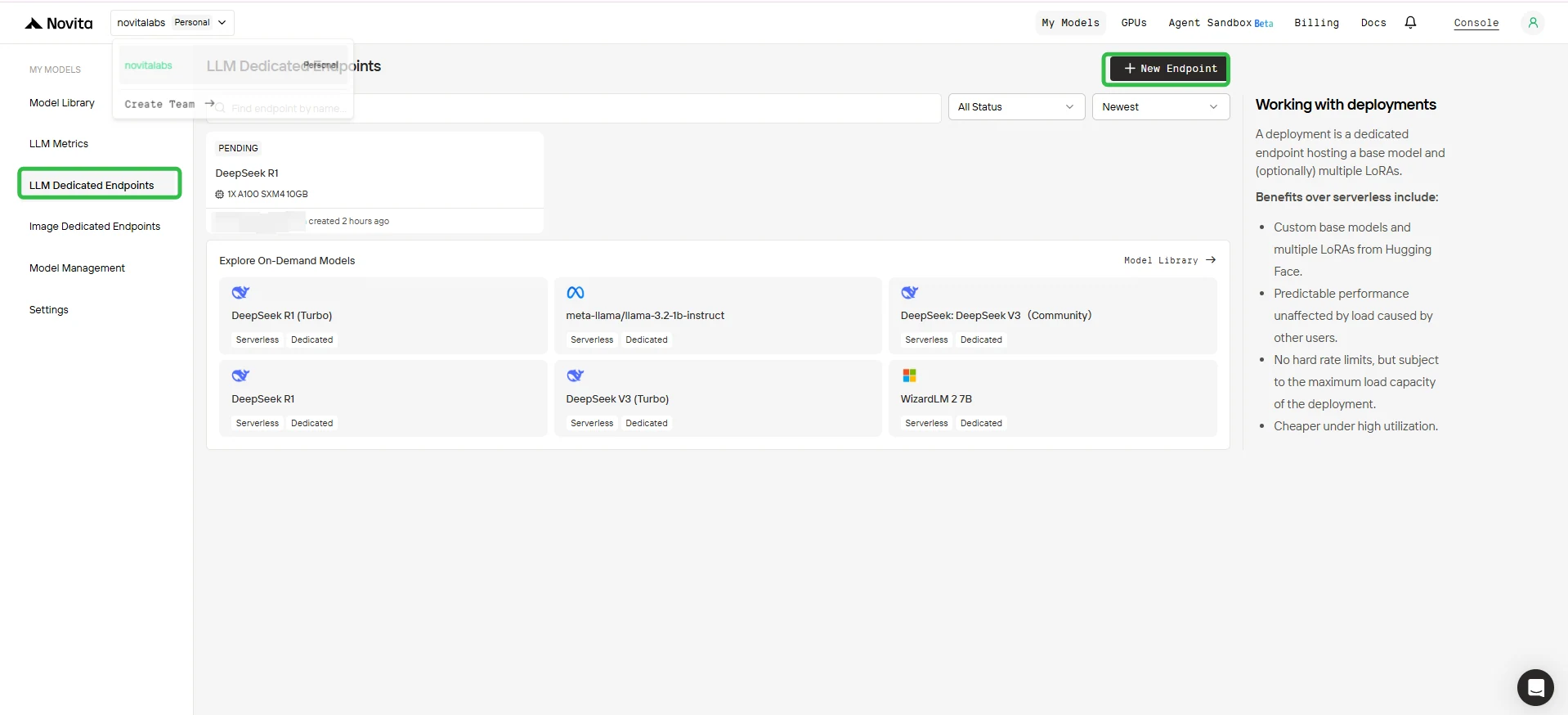
2. Crie um Novo Endpoint
- Clique no botão + Novo Endpoint no canto superior direito.
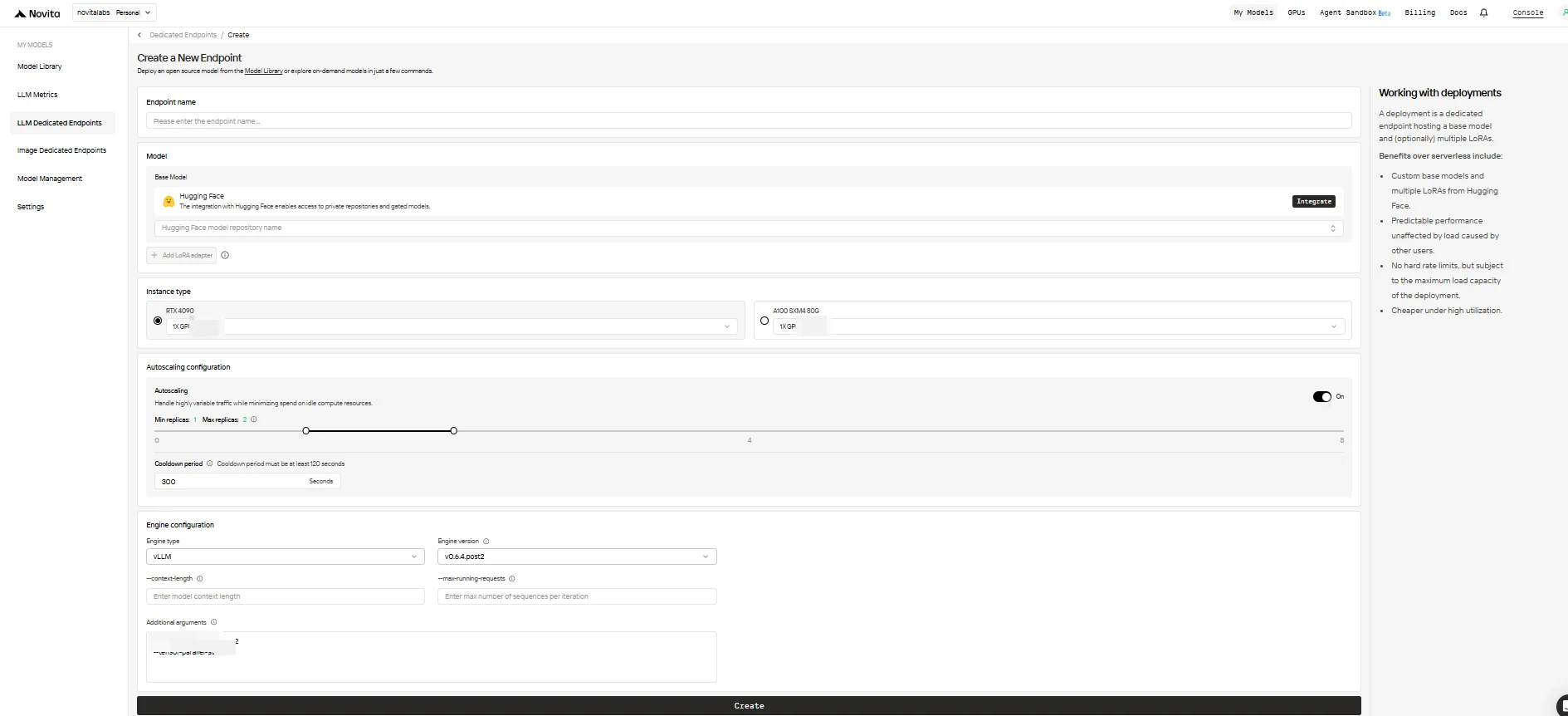
3. Configure Seu Endpoint
Preencha o formulário de configuração com as seguintes opções:
-
Nome do Endpoint: Dê ao seu deployment um nome único e descritivo.
-
Modelo Base: Insira o nome do repositório Hugging Face do seu modelo base (apenas modelos Hugging Face são suportados, incluindo públicos, privados ou com acesso restrito).
-
Adaptadores LoRA (opcional): Adicione um ou mais IDs de modelo do Hugging Face para anexar adaptadores LoRA ao seu modelo base.
-
Tipo de Instância: Selecione o hardware da GPU (ex.: H100, H200, RTX4090). Cada usuário pode usar até 8 GPUs em todos os endpoints.
-
Configuração de Autoscaling:
- Réplicas Mínimas: Defina como
0para permitir que o endpoint entre em modo de espera quando ocioso (economia de custos) ou um valor maior para manter sempre um número mínimo de réplicas ativas. - Réplicas Máximas: Defina o número máximo de réplicas para escalar (até 10).
- Período de Resfriamento: Defina o atraso (em segundos) antes de reduzir as réplicas para evitar redução prematura durante quedas breves de tráfego.
- Réplicas Mínimas: Defina como
-
Configuração do Motor:
- Tipo de Motor: Escolha o motor de inferência (
vLLMouSGLang). - Versão do Motor: Use a padrão (mais recente) ou especifique uma versão.
- Comprimento do Contexto: Opcionalmente, defina o comprimento máximo do contexto em tokens; se omitido, será derivado da configuração do modelo.
- Máximo de Requisições em Execução: Defina o número máximo de sequências processadas por iteração.
- Argumentos Adicionais: Adicione parâmetros extras do motor para personalização avançada.
- Tipo de Motor: Escolha o motor de inferência (
Quando terminar, clique em Criar para implantar seu endpoint.
4. Status da Implantação do Endpoint
Após a criação, seu endpoint passará por vários status:
- Em Espera: O endpoint está ocioso, sem consumir recursos computacionais (se as réplicas mínimas estiverem definidas como 0).
- Pendente: A implantação está inicializando.
- Em Andamento: O modelo e a infraestrutura estão sendo configurados.
- Em Execução: O endpoint está ativo e pronto para atender requisições.
Você pode monitorar esse status na página de Endpoints do console.
5. Teste Seu Endpoint no Playground
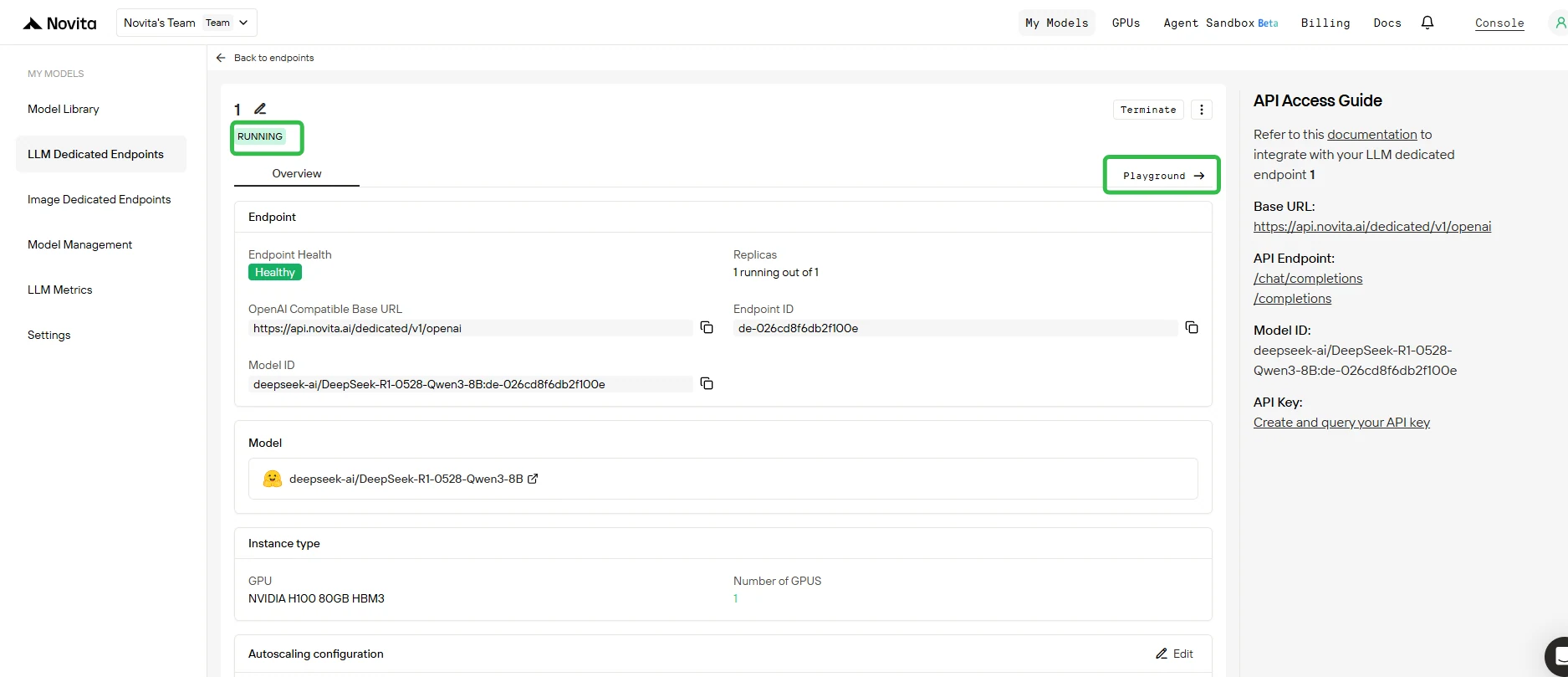
- Quando a implantação for concluída e o status estiver Em Execução, clique no seu endpoint e abra a guia Playground.
- No Playground, você pode:
- Enviar prompts de teste para seu modelo base e quaisquer adaptadores LoRA anexados.
- Comparar instantaneamente a saída de diferentes adaptadores com o modelo base.
6. Próximos Passos
- Endpoints Multi-LoRA: Implante vários adaptadores LoRA em um único endpoint para alternância flexível de modelos.
- Integração com API: Use os endpoints de API fornecidos para enviar requisições e integrar seu modelo em suas próprias aplicações.
- Otimize e Escale: Ajuste o autoscaling, a configuração do motor e a cota de GPU conforme suas necessidades crescerem.
- Precisa de Mais Recursos? Entre em contato com nossa equipe de vendas para uma solução empresarial se precisar de mais de 8 GPUs ou recursos de nível empresarial.
Exemplos de Código (Para usuários Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Sua Chave de API>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # ou False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "você é um assistente de IA profissional.",
},
{
"role": "user",
"content": "Onde o exemplo de GPU fornecido pela novita ai pode ser adaptado?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusão
O novo LLM Dedicated Endpoint da Novita AI permite que você implante e escale modelos Hugging Face personalizados com confiança. Desfrute de integração flexível com adaptadores LoRA, autoscaling simples, preços competitivos e transparentes, e a garantia de um SLA de 99,5%. Seja lançando seu primeiro modelo ajustado ou gerenciando cargas de trabalho de produção, a Novita AI torna simples ir do protótipo à produção — de forma rápida, segura e eficiente.
Pronto para experimentar uma implantação perfeita de LLM? Cadastre-se agora ou entre em contato com nossa equipe de vendas para uma demonstração empresarial e um plano personalizado.
Perguntas Frequentes
Quais modelos posso implantar em um Endpoint Dedicado?
Você pode implantar qualquer modelo do Hugging Face, incluindo modelos públicos, privados, ajustados ou proprietários. Tanto modelos base quanto modelos com adaptadores LoRA personalizados são suportados.
Como um Endpoint Dedicado é diferente de um Endpoint Serverless?
Um Endpoint Dedicado fornece hardware reservado e isolado para desempenho consistente, personalização avançada e maior throughput. Por outro lado, os Endpoints Serverless operam em infraestrutura compartilhada, são melhores para uso baixo ou variável e ideais para prototipagem rápida sem gerenciamento de hardware.
Posso escalar meu Endpoint Dedicado conforme minha carga de trabalho cresce?
Sim. Os Endpoints Dedicados suportam autoscaling com base na demanda em tempo real. Você pode começar com uma GPU e escalar até 8 GPUs por usuário (com opções empresariais para mais), garantindo que suas aplicações permaneçam responsivas mesmo durante picos de tráfego.
Como monitorar e gerenciar meu Endpoint Dedicado?
Cada Endpoint Dedicado vem com métricas e logs detalhados. Você pode acompanhar o desempenho, monitorar o uso e solucionar problemas através do console web ou da API, tornando o gerenciamento e a otimização simples.
Quais são as opções de preço e como controlo os custos?
O preço é transparente e baseado no uso, a partir de US$ 1,86/h para GPUs H100 e US$ 3,00/h para GPUs H200. Você paga apenas pelo que usa. O autoscaling e o gerenciamento flexível ajudam a otimizar a utilização e manter os custos previsíveis, especialmente para cargas de trabalho de produção.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem de GPU acessível e confiável para construir e escalar.



