

El LLM Dedicated Endpoint de Novita AI es un servicio recién lanzado que te permite desplegar tus propios modelos personalizados o ajustados de Hugging Face con facilidad.
Con GPUs H100 dedicadas desde $1.86/hora y H200 desde $2.99/hora, Novita AI ofrece precios altamente competitivos, a menudo más rentables que alternativas como Together AI, Fireworks AI y Friendli AI.
Disfruta de soporte flexible para LoRA, un SLA del 99.5 % y opciones escalables de GPU. Configura endpoints LLM listos para producción en minutos y gestiona tus recursos con confianza gracias a precios transparentes y predecibles.
¿Qué es LLM Dedicated Endpoint?
Un LLM Dedicated Endpoint proporciona una API privada basada en la nube para ejecutar modelos de lenguaje grandes en infraestructura reservada exclusivamente para tu uso. Esta configuración garantiza que tus modelos funcionen con un rendimiento consistente, alta confiabilidad y un completo aislamiento de recursos, a diferencia de alternativas compartidas o serverless.
Con un endpoint dedicado, puedes desplegar tanto modelos open-source como privados en Hugging Face, incluyendo tus variantes personalizadas o ajustadas. Los datos sensibles y la propiedad intelectual permanecen protegidos, ya que tus modelos y tráfico nunca están expuestos a otros usuarios.
¿Por qué elegir LLM Dedicated Endpoint?
Con LLM Dedicated Endpoint de Novita AI, obtienes un entorno robusto y flexible para tus cargas de trabajo de IA:
- Despliegue de modelos personalizados: Sirve fácilmente cualquier modelo de Hugging Face, incluyendo versiones privadas y ajustadas, dentro de un entorno aislado y dedicado.
- Gestión flexible de adaptadores LoRA: Adjunta y cambia entre múltiples adaptadores LoRA en un solo endpoint. Experimenta, itera y soporta diversas tareas sin necesidad de redesplegar tu modelo base.
- Rendimiento predecible: Los recursos dedicados aseguran un rendimiento constante y baja latencia, sin verse afectados por otros usuarios. No hay límites de tasa estrictos; la capacidad de tu endpoint está determinada por el hardware y la configuración que elijas.
- Hardware escalable: Escala desde inactivo (0 réplicas) hasta 10 réplicas por endpoint, y elige el tipo de GPU que se ajuste a tus necesidades. Cada usuario puede acceder hasta 8 GPUs, con expansión empresarial disponible.
- Precios transparentes: H100 desde $1.86/hora, H200 desde $2.99/hora: paga solo por lo que usas. Los endpoints dedicados suelen ser más rentables que las soluciones serverless bajo un uso alto o sostenido.
- Gestión fácil de usar: Consola web intuitiva para el despliegue y la gestión, más pruebas instantáneas en Playground para una validación rápida.
- Confiabilidad lista para producción: Garantía de disponibilidad del 99.5 %, completamente gestionado por Novita AI para tu tranquilidad.
Cómo elegir: Dedicated Endpoint vs. Serverless Endpoint
Seleccionar el tipo correcto de endpoint de inferencia LLM depende de tu caso de uso, carga de trabajo y requisitos operativos. Aquí tienes una guía rápida para ayudarte a decidir:
Elige un LLM Serverless Endpoint si:
- Quieres acceso rápido y flexible a LLMs públicos sin gestionar infraestructura.
- Tu uso es bajo, variable o para prototipos.
- Quieres un precio simple de pago por uso.
Elige un LLM Dedicated Endpoint si:
- Quieres desplegar cualquier modelo de Hugging Face (incluyendo privados, ajustados o con acceso restringido).
- Necesitas configurar adaptadores LoRA y parámetros de manera flexible.
- Requieres hardware dedicado, alto rendimiento estable y confiabilidad de nivel producción.
- Deseas optimizar para el menor costo de GPU en la industria.
- Necesitas hasta 8 GPUs por usuario, o más.
Si necesitas más recursos, contacta a nuestro equipo de ventas para una solución empresarial personalizada.
| Aspecto | LLM Serverless Endpoint | LLM Dedicated Endpoint (DE) |
| Modelo de facturación | Pago por uso (por token) | Pago por GPU por hora |
| Tipo de recurso | Compartido, serverless (multi-tenant) | Dedicado, controlado por el usuario (single-tenant) |
| Consistencia de rendimiento | Puede fluctuar (carga compartida) | Predecible, no afectado por otros usuarios |
| Límites de tasa | Sí (TPM, RPM por nivel de usuario) | Sin límites de tasa estrictos; limitado por la cuota de GPU del usuario |
| Selección de modelos | Solo modelos públicos | Cargar modelos base personalizados desde repositorios de Hugging Face (públicos, privados o con acceso restringido); soporta configuración de parámetros LoRA |
| Elección de hardware | No seleccionable | Flexible: H100, H200, 4090, etc. |
| Región de despliegue | No seleccionable por el usuario | El usuario puede elegir la región |
| SLA | Sin garantía formal | SLA del 99.5 % |
| Costo con alta utilización | Más caro a escala | Más barato con alta utilización |
| Seguridad y aislamiento de datos | Entorno compartido | Aislamiento completo de tenant, endpoints privados |
| Mejor para | Startups, prototipos, uso fluctuante | Empresas, producción, alto rendimiento estable, modelos base personalizados |
Comparación de precios de GPU para Dedicated Endpoint
Al elegir un proveedor, la eficiencia de costos es crucial, especialmente para despliegues a escala de producción. Novita AI ofrece las tarifas por hora más bajas para GPUs H100 y H200 dedicadas entre los principales proveedores:
| Proveedor | H100 (1 tarjeta/hora) | H200 (1 tarjeta/hora) |
| Novita AI | $1.86 | $2.99 |
| Fireworks AI | $5.80 | $9.99 |
| Friendli AI | $4.90 | $5.90 |
| Together AI | $3.36 | $4.99 |
| Deepinfra | $2.40 | $3.00 |
Como se muestra arriba, Novita AI ofrece constantemente los precios más competitivos tanto para GPUs H100 como H200, hasta un 60 % más bajos que otros proveedores populares.
Esto significa que puedes reducir significativamente los costos de infraestructura para despliegues de LLM de alto rendimiento o de larga duración al elegir Novita AI.
Cómo comenzar con LLM Dedicated Endpoints de Novita AI
1. Accede a la consola
- Inicia sesión en tu Consola de Novita AI.
- En la barra lateral izquierda, haz clic en LLM Dedicated Endpoints.
2. Crea un nuevo endpoint
- Haz clic en el botón + Nuevo Endpoint en la esquina superior derecha.
3. Configura tu endpoint
Completa el formulario de configuración con las siguientes opciones:
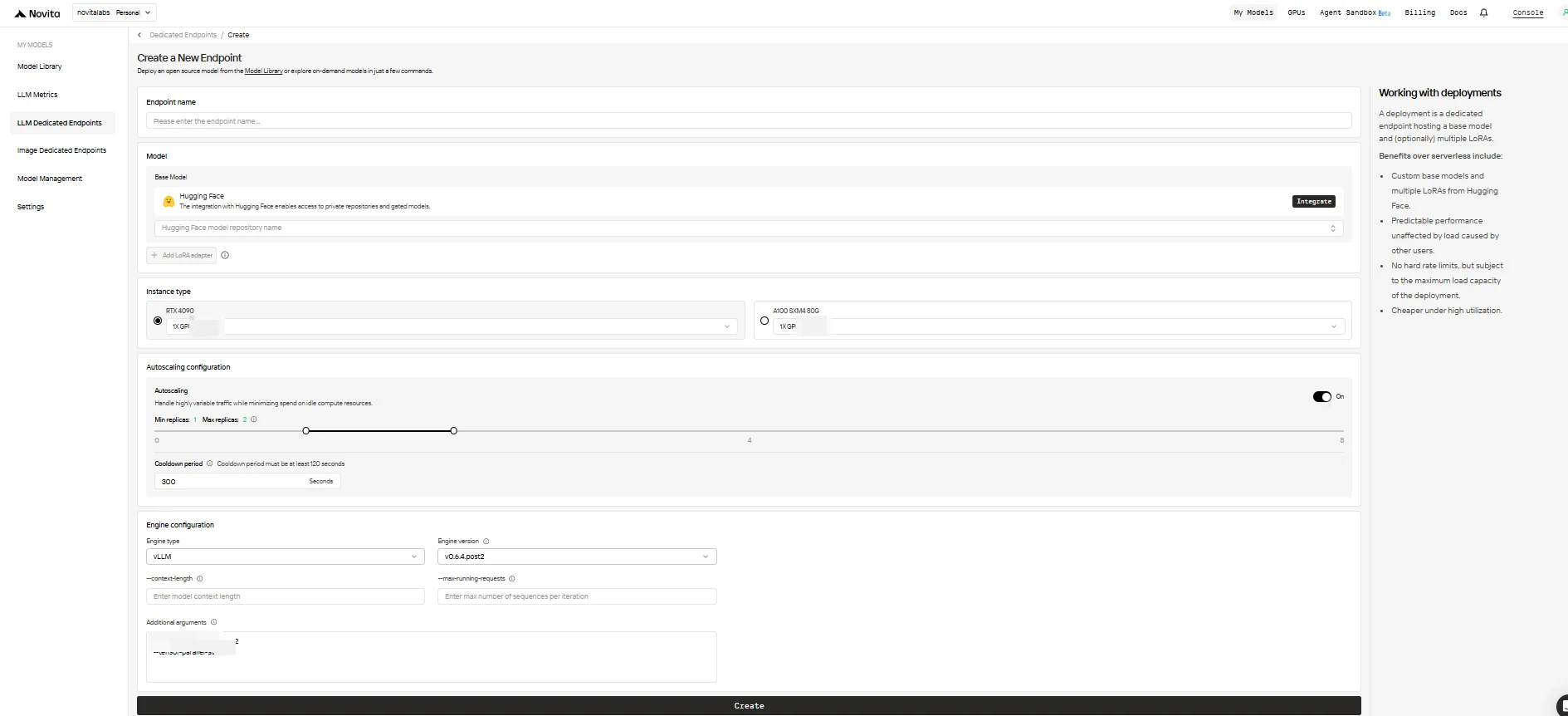
-
Nombre del endpoint: Dale a tu despliegue un nombre único y descriptivo.
-
Modelo base: Ingresa el nombre del repositorio de Hugging Face para tu modelo base (solo se admiten modelos de Hugging Face, incluidos públicos, privados o con acceso restringido).
-
Adaptadores LoRA (opcional): Agrega uno o más ID de modelo de Hugging Face para adjuntar adaptadores LoRA a tu modelo base.
-
Tipo de instancia: Selecciona el hardware de GPU (por ejemplo, H100, H200, RTX4090). Cada usuario puede usar hasta 8 GPUs en todos los endpoints.
-
Configuración de autoescalado:
- Réplicas mínimas: Establece en
0para permitir que el endpoint se duerma cuando esté inactivo (ahorro de costos), o un valor más alto para mantener siempre un número mínimo de réplicas activas. - Réplicas máximas: Establece el número máximo de réplicas para escalar (hasta 10).
- Período de inactividad: Establece el retraso (en segundos) antes de reducir las réplicas para evitar una reducción prematura durante caídas breves de tráfico.
- Réplicas mínimas: Establece en
-
Configuración del motor:
- Tipo de motor: Elige el motor de inferencia (
vLLMoSGLang). - Versión del motor: Usa la versión predeterminada (la más reciente) o especifica una versión.
- Longitud de contexto: Opcionalmente, establece la longitud máxima del contexto en tokens; si se omite, se derivará de la configuración del modelo.
- Máximo de solicitudes en ejecución: Establece el número máximo de secuencias procesadas por iteración.
- Argumentos adicionales: Agrega cualquier parámetro adicional del motor para personalización avanzada.
- Tipo de motor: Elige el motor de inferencia (
Cuando hayas terminado, haz clic en Crear para desplegar tu endpoint.
4. Estado del despliegue del endpoint
Después de la creación, tu endpoint pasará por varios estados:
- Durmiendo: El endpoint está inactivo, sin consumir recursos de cómputo (si las réplicas mínimas están en 0).
- Pendiente: El despliegue se está iniciando.
- Rodando: El modelo y la infraestructura se están configurando.
- Ejecutándose: El endpoint está activo y listo para atender solicitudes.
Puedes monitorear este estado en la página de Endpoints de la consola.
5. Prueba tu endpoint en Playground
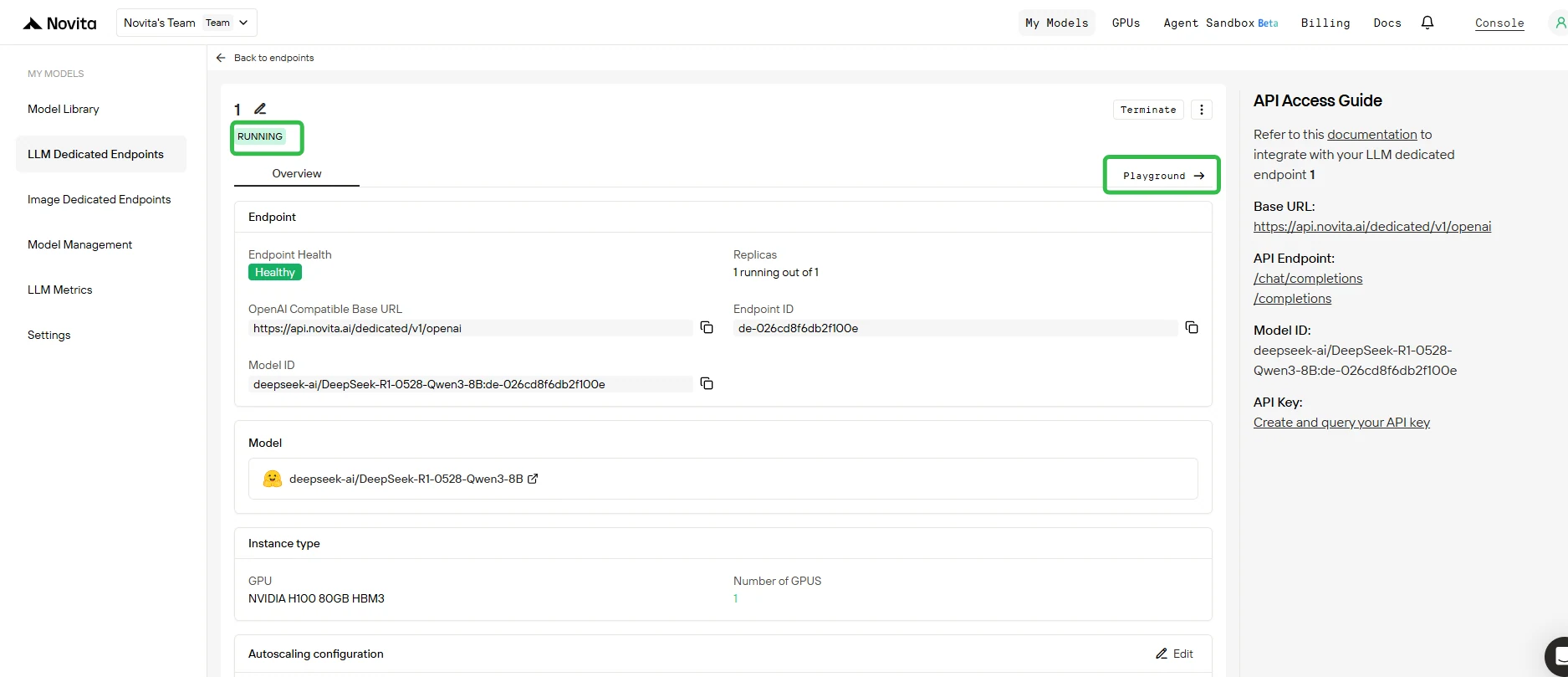
- Una vez que el despliegue esté completo y el estado sea Ejecutándose, haz clic en tu endpoint y abre la pestaña Playground.
- En Playground, puedes:
- Enviar indicaciones de prueba a tu modelo base y a cualquier adaptador LoRA adjunto.
- Comparar instantáneamente la salida de diferentes adaptadores frente al modelo base.
6. Próximos pasos
- Endpoints multi-LoRA: Despliega múltiples adaptadores LoRA en un solo endpoint para un cambio flexible de modelo.
- Integración de API: Usa los endpoints de API proporcionados para enviar solicitudes e integrar tu modelo en tus propias aplicaciones.
- Optimiza y escala: Ajusta el autoescalado, la configuración del motor y la cuota de GPU a medida que tus necesidades crezcan.
- ¿Necesitas más recursos? Contacta a nuestro equipo de ventas para una solución empresarial si necesitas más de 8 GPUs o requieres funciones de nivel empresarial.
Ejemplos de código (para usuarios de Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Tu clave API>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # o False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "eres un asistente de IA profesional.",
},
{
"role": "user",
"content": "¿Dónde se puede adaptar el ejemplo de GPU proporcionado por novita ai?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusión
El nuevo LLM Dedicated Endpoint de Novita AI te permite desplegar y escalar modelos personalizados de Hugging Face con confianza. Disfruta de la integración flexible de adaptadores LoRA, un autoescalado sencillo, precios transparentes y competitivos, y la garantía de un SLA del 99.5 %. Ya sea que estés lanzando tu primer modelo ajustado o gestionando cargas de trabajo de producción, Novita AI facilita pasar del prototipo a la producción de manera rápida, segura y eficiente.
¿Listo para experimentar un despliegue fluido de LLM? Regístrate ahora o contacta a nuestro equipo de ventas para una demostración empresarial y un plan a medida.
Preguntas frecuentes
¿Qué modelos puedo desplegar en un Dedicated Endpoint?
Puedes desplegar cualquier modelo de Hugging Face, incluidos modelos públicos, privados, ajustados o propietarios. Se admiten tanto modelos base como modelos con adaptadores personalizados o LoRA.
¿En qué se diferencia un Dedicated Endpoint de un Serverless Endpoint?
Un Dedicated Endpoint te proporciona hardware reservado y aislado para un rendimiento consistente, personalización avanzada y mayor rendimiento. En cambio, los Serverless Endpoints se ejecutan en infraestructura compartida, son mejores para un uso bajo o variable e ideales para prototipos rápidos sin gestión de hardware.
¿Puedo escalar mi Dedicated Endpoint a medida que crece mi carga de trabajo?
Sí. Los Dedicated Endpoints soportan autoescalado basado en la demanda en tiempo real. Puedes comenzar con una GPU y escalar hasta 8 GPUs por usuario (con opciones empresariales para más), asegurando que tus aplicaciones sigan siendo receptivas incluso durante picos de tráfico.
¿Cómo monitoreo y gestiono mi Dedicated Endpoint?
Cada Dedicated Endpoint viene con métricas y registros detallados. Puedes rastrear el rendimiento, monitorear el uso y solucionar problemas a través de la consola web o la API, lo que facilita la gestión y la optimización.
¿Cuáles son las opciones de precios y cómo controlo los costos?
Los precios son transparentes y basados en el uso, desde $1.86/hora para GPUs H100 y $3.00/hora para GPUs H200. Solo pagas por lo que usas. El autoescalado y la gestión flexible te ayudan a optimizar la utilización y mantener los costos predecibles, especialmente para cargas de trabajo de producción.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



