

Novita AI 的 LLM 專用端點 是一項全新推出的服務,讓您能夠輕鬆部署自己的自訂或微調 Hugging Face 模型。
專用 H100 GPU 每小時僅需 $1.86 起,H200 每小時 $2.99 起,Novita AI 提供極具競爭力的價格——通常比 Together AI、Fireworks AI 和 Friendli AI 等替代方案更划算。
享受彈性的 LoRA 支援、99.5% 的 SLA 以及可擴展的 GPU 選項。數分鐘內即可建立好可投入生產的 LLM 端點,並以透明、可預測的定價自信地管理資源。
什麼是 LLM 專用端點?
LLM 專用端點 提供一個私有的雲端 API,用於在完全專屬於您使用的基礎設施上執行大型語言模型。這種配置能確保您的模型具有穩定的效能、高可靠性以及完全的資源隔離——這與共享或無伺服器替代方案不同。
使用專用端點,您可以部署 Hugging Face 上的開源與私有模型,包括您的自訂或微調變體。敏感資料與智慧財產權都能獲得保護,因為您的模型與流量絕不會暴露給其他使用者。
為什麼選擇 LLM 專用端點?
透過 Novita AI 的 LLM 專用端點,您可以在一個強大且彈性的環境中運行 AI 工作負載:
- 自訂模型部署: 輕鬆提供任何 Hugging Face 模型(包括私有與微調版本),且位於隔離的專用環境中。
- 彈性的 LoRA 適配器管理: 在單一端點上附加並切換多個 LoRA 適配器。無需重新部署基礎模型即可進行實驗、迭代並支援多樣任務。
- 可預測的效能: 專用資源確保穩定的吞吐量與低延遲,不受其他使用者影響。沒有硬性的速率限制;端點容量由您選擇的硬體與設定決定。
- 可擴展的硬體: 從閒置(0 個副本)擴展到每個端點最多 10 個副本,並選擇符合作業需求的 GPU 類型。每位使用者最多可使用 8 個 GPU,並可擴展至企業方案。
- 透明的定價: H100 每小時 $1.86 起,H200 每小時 $2.99 起——只需為使用量付費。專用端點在高用量或持續使用下通常比無伺服器解決方案更具成本效益。
- 易於管理的介面: 直觀的 Web 控制台用於部署與管理,並提供即時 Playground 測試以快速驗證。
- 可投入生產的可靠性: 99.5% 正常運作時間保證,由 Novita AI 完全託管,讓您安心。
如何選擇:專用端點 vs. 無伺服器端點
選擇正確類型的 LLM 推理端點取決於您的使用案例、工作負載與營運需求。以下快速指南幫助您做出決定:
如果符合以下條件,請選擇 LLM 無伺服器端點:
- 您希望快速、靈活地存取公開 LLM,無需管理基礎設施。
- 您的使用量低、變動大或僅用於原型開發。
- 您希望採用簡單的按用量付費定價。
如果符合以下條件,請選擇 LLM 專用端點:
- 您想要部署任何 Hugging Face 模型(包括私有、微調或受限制的模型)。
- 您需要靈活配置 LoRA 適配器與參數。
- 您需要專用硬體、穩定的高吞吐量以及生產級可靠性。
- 您希望以業界最低的 GPU 成本進行最佳化。
- 您需要每個使用者最多 8 個 GPU,或更多。
如果您需要更多資源,請聯絡我們的 銷售團隊 以取得客製企業方案。
| 方面 | LLM 無伺服器端點 | LLM 專用端點(DE) |
| 計費模式 | 按用量付費(按 token) | 按 GPU 每小時付費 |
| 資源類型 | 共享、無伺服器(多租戶) | 專用、使用者控制(單一租戶) |
| 效能一致性 | 可能波動(共享負載) | 可預測,不受其他使用者影響 |
| 速率限制 | 有(依使用者層級限制 TPM、RPM) | 無硬性速率限制;受限於使用者 GPU 配額 |
| 模型選擇 | 僅限公開模型 | 從 Hugging Face 倉庫(公開、私有或受限制)載入自訂基礎模型;支援 LoRA 參數配置 |
| 硬體選擇 | 不可選擇 | 彈性:H100、H200、4090 等 |
| 部署區域 | 使用者不可選擇 | 使用者可選擇區域 |
| SLA | 無正式保證 | 99.5% SLA |
| 高利用率成本 | 規模擴大時更昂貴 | 高利用率時更便宜 |
| 安全性與資料隔離 | 共享環境 | 完全租戶隔離,私有端點 |
| 最適合 | 新創公司、原型開發、用量波動 | 企業、生產環境、穩定高吞吐量、自訂基礎模型 |
專用端點 GPU 價格比較
在選擇提供商時,成本效益至關重要——尤其是對於生產規模的部署。Novita AI 在專用 H100 與 H200 GPU 上提供了領先提供商中最低的每小時費率:
| 提供商 | H100(每張卡/小時) | H200(每張卡/小時) |
| Novita AI | $1.86 | $2.99 |
| Fireworks AI | $5.80 | $9.99 |
| Friendli AI | $4.90 | $5.90 |
| Together AI | $3.36 | $4.99 |
| Deepinfra | $2.40 | $3.00 |
如上所示,Novita AI 在 H100 與 H200 GPU 上均持續提供極具競爭力的定價——比其他熱門提供商低出最多 60%。
這表示透過選擇 Novita AI,您可以大幅降低高吞吐量或長期運行的 LLM 部署的基礎設施成本。
如何開始使用 Novita AI LLM 專用端點
1. 存取控制台
- 登入您的 Novita AI 控制台。
- 在左側邊欄中,按一下 LLM 專用端點。
2. 建立新端點
- 按一下右上角的 + 新端點 按鈕。
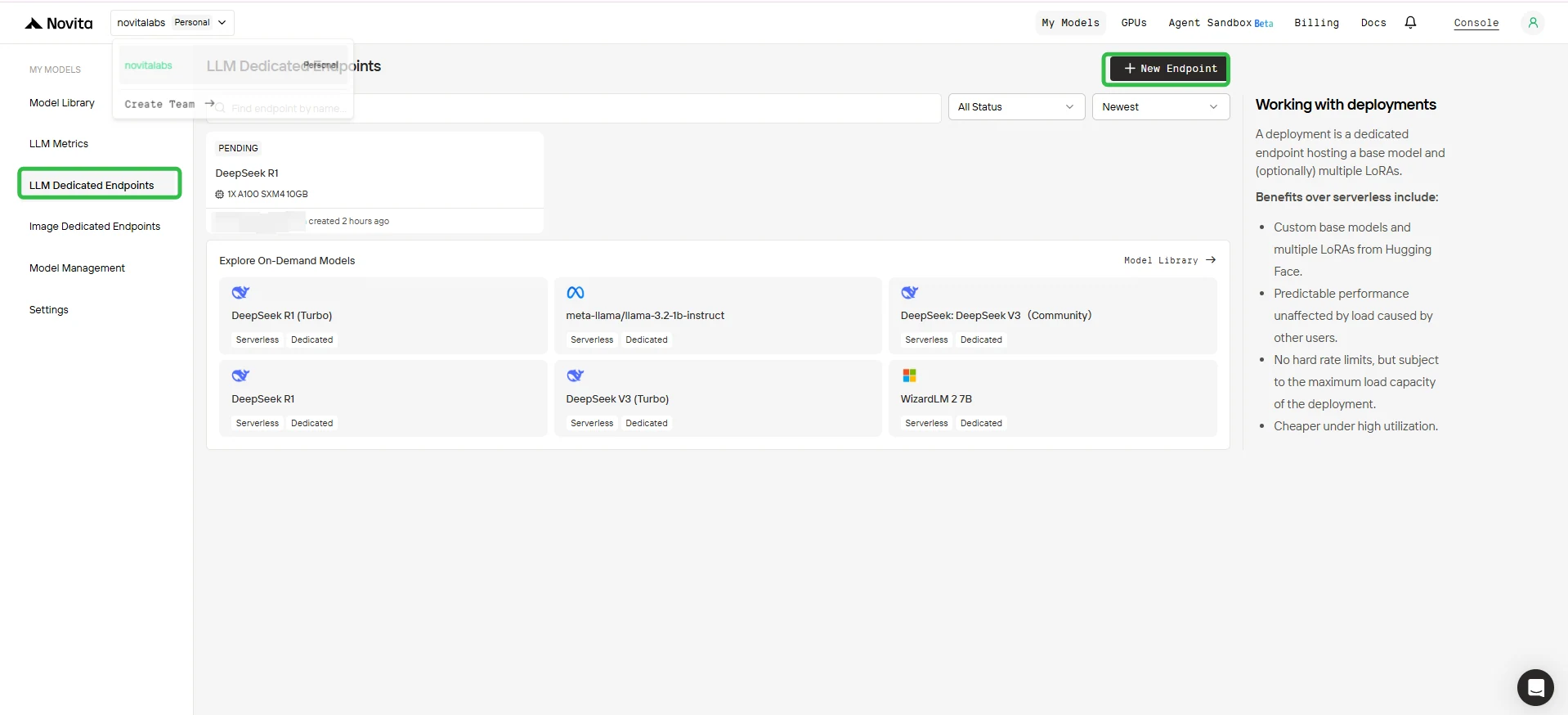
3. 配置端點
填寫配置表單,包含以下選項:
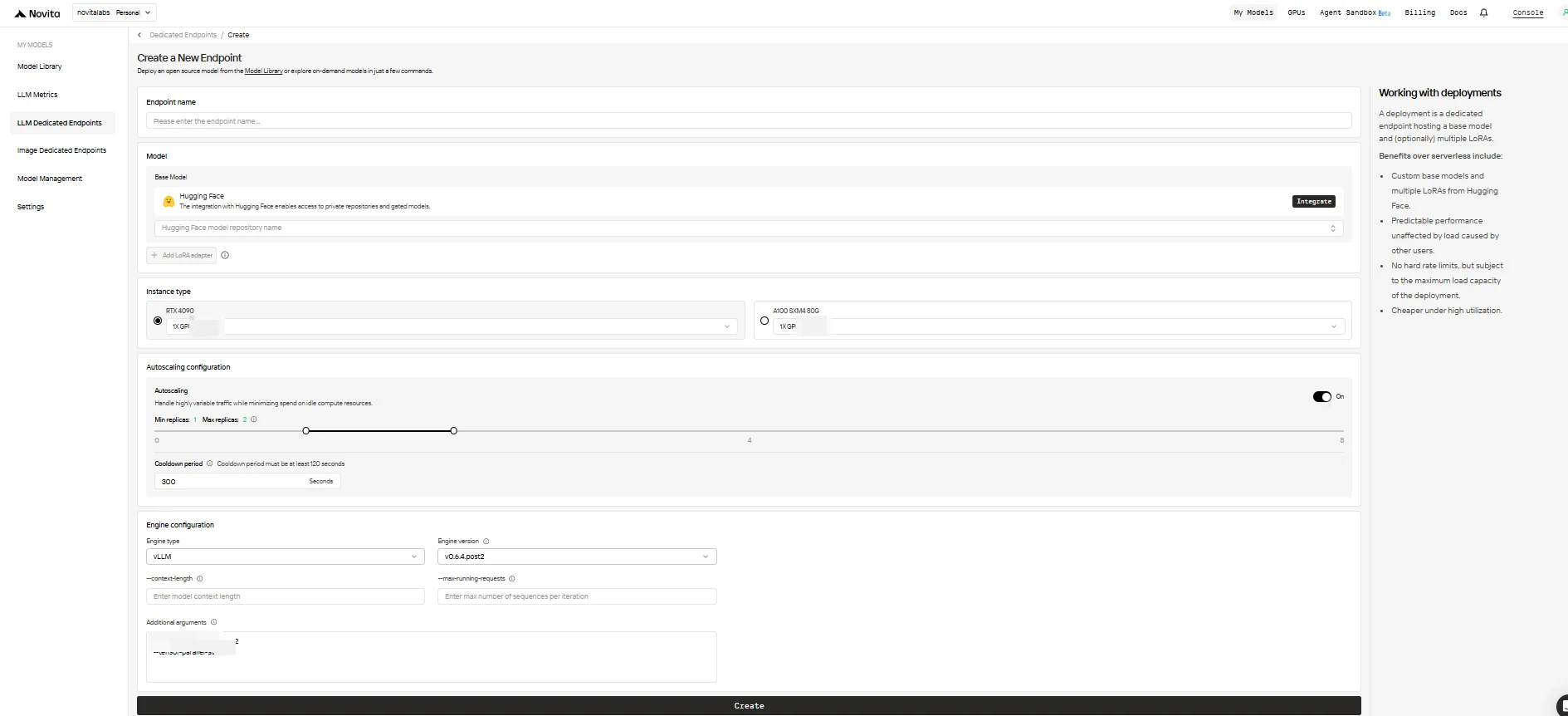
- 端點名稱: 為您的部署命名一個獨特且具有描述性的名稱。
- 基礎模型: 輸入基礎模型的 Hugging Face 倉庫名稱(僅支援 Hugging Face 模型,包括公開、私有或受限制的模型)。
- LoRA 適配器(選填): 新增一個或多個 Hugging Face 模型 ID,將 LoRA 適配器附加到基礎模型上。
- 執行個體類型: 選擇 GPU 硬體(例如 H100、H200、RTX4090)。每位使用者在所有端點上總共最多可使用 8 個 GPU。
- 自動擴展配置:
- 最少副本數: 設為
0可讓端點在閒置時休眠(節省成本),或設為更高值以始終保持最少數量的作用中副本。 - 最多副本數: 設定擴展時的最大副本數量(最多 10 個)。
- 冷卻時間: 設定縮減副本之前的延遲時間(秒),以避免在短暫流量下降時過早縮減。
- 最少副本數: 設為
- 引擎配置:
- 引擎類型: 選擇推理引擎(
vLLM或SGLang)。 - 引擎版本: 使用預設(最新)或指定版本。
- 上下文長度: 可選設定最大 token 上下文長度;如果省略,將從模型配置推導。
- 最大執行中請求數: 設定每次迭代處理的最大序列數量。
- 額外引數: 新增任何額外的引擎參數以進行進階自訂。
- 引擎類型: 選擇推理引擎(
完成後,按一下 建立 以部署端點。
4. 端點部署狀態
建立後,端點將經歷多個狀態:
- 休眠中: 端點閒置,不消耗計算資源(如果最少副本數設為 0)。
- 待處理: 部署正在初始化。
- 滾動中: 正在設定模型與基礎設施。
- 運行中: 端點已啟用並準備好服務請求。
您可以在控制台的端點頁面上監控此狀態。
5. 在 Playground 中測試端點
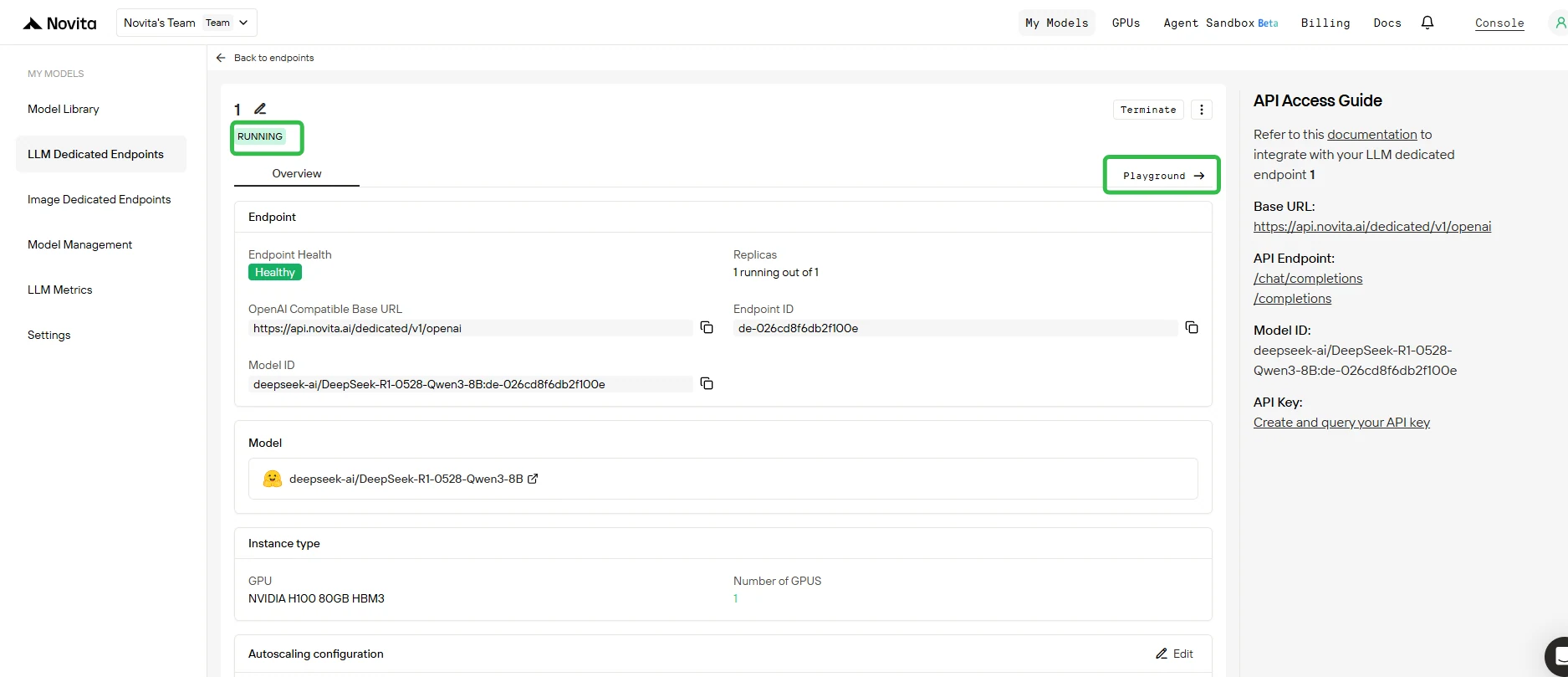
- 部署完成且狀態變為 **運行中 ** 後,按一下端點並開啟 Playground 標籤。
- 在 Playground 中,您可以:
- 向基礎模型以及任何附加的 LoRA 適配器發送測試提示。
- 即時比較不同適配器與基礎模型的輸出。
6. 後續步驟
- 多 LoRA 端點: 在單一端點上部署多個 LoRA 適配器,實現靈活的模型切換。
- API 整合: 使用提供的 API 端點發送請求,並將模型整合到您自己的應用程式中。
- 最佳化與擴展: 根據需求調整自動擴展、引擎配置與 GPU 配額。
- 需要更多資源? 如果您需要超過 8 個 GPU 或需要企業級功能,請聯絡我們的 銷售團隊 以取得企業解決方案。
程式碼範例(適用於 Python 使用者)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
結論
Novita AI 的全新 LLM 專用端點讓您能夠自信地部署與擴展自訂的 Hugging Face 模型。享受彈性的 LoRA 適配器整合、直觀的自動擴展、具競爭力的透明定價以及 99.5% SLA 的保證。無論您是推出第一個微調模型還是管理生產工作負載,Novita AI 都能讓您快速、安全且高效地從原型進入生產階段。
準備好體驗無縫的 LLM 部署了嗎? 立即註冊 ** 或 ** 聯絡我們的銷售團隊 ** 以取得企業示範與量身訂做的方案。**
常見問題
我可以在專用端點上部署哪些模型?
您可以部署任何來自 Hugging Face 的模型,包括公開、私有、微調或專有模型。支援基礎模型以及帶有自訂或 LoRA 適配器的模型。
專用端點與無伺服器端點有何不同?
專用端點為您提供保留的隔離硬體,以實現穩定的效能、進階自訂與更高的吞吐量。相反地,無伺服器端點運行在共享基礎設施上,最適合低用量或變動用量,並非常適合無需硬體管理的快速原型開發。
我可以隨著工作負載成長而擴展專用端點嗎?
可以。專用端點支援基於即時需求的自動擴展。您可以從一個 GPU 開始,然後擴展到每位使用者最多 8 個 GPU(企業方案可提供更多),確保您的應用程式即使在流量尖峰時也能保持回應。
如何監控與管理我的專用端點?
每個專用端點都附帶詳細的指標與日誌。您可以透過 Web 控制台或 API 追蹤效能、監控使用情況並排查問題,讓管理與最佳化變得簡單。
定價選項有哪些?我如何控制成本?
定價透明且按使用量計費,H100 GPU 每小時 $1.86 起,H200 GPU 每小時 $3.00 起。您只需為使用量付費。自動擴展與彈性管理有助於最佳化利用率,並使成本保持可預測,尤其是對於生產工作負載。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 以便部署 AI 模型,同時提供經濟實惠且可靠的 GPU 雲端用於建置與擴展。



