

本文闡明 DeepSeek-V3.2 與 DeepSeek-V3.2-Speciale 在架構、效能、推論效率與部署需求上的差異。透過具體規格、量化 VRAM 門檻、基準測試影響與存取途徑,為真實世界編碼任務選擇最適合的 DeepSeek-V3.2 API 提供聚焦的決策指南。
請注意!Novita AI 正在推出「Build Month」活動,為開發者提供所有主要產品最高 20% 的獨家優惠!
開發者專用的 DeepSeek V3.2
一個緊湊的技術指南,協助開發者評估 DeepSeek-V3.2 是否適合真實世界的編碼工作負載。
DeepSeek V3.2 架構概覽
| 元件 | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | 備註 |
|---|---|---|---|
| 總參數 | 671B MoE | 671B MoE | 完整模型尺寸不變 |
| 每 Token 有效參數 | 37B | 37B | |
| 上下文視窗 | 128K tokens | 128K tokens | 足以容納完整程式碼庫 |
| 注意力機制 | DeepSeek Sparse Attention (DSA) | DSA(增強調優) | 長序列的主要加速方案 |
| 精度 | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | 部署推薦使用 Int8/Int4 |
DeepSeek V3.2 與編碼相關的強化功能
- DeepSeek 稀疏注意力機制(DSA)
降低長程式碼序列的注意力計算複雜度;提升 VRAM 使用效率。 - 長上下文穩定性(>100K tokens)
維持參考一致性——對於多檔案程式碼導航、相依性追蹤與重構至關重要。 - 混合 CoT + 工具使用訓練
V3.2 特別針對「思考後行動」模式進行調優。 - Speciale 變體
針對演算法推理任務的額外優化。引入了 DSA 這款高效的注意力機制,能在保留模型效能的同時大幅降低計算複雜度,特別針對長上下文場景進行優化。
DeepSeek V3.2 的基準測試效能
DeepSeek-V3.2 的表現與 GPT-5 相當。值得注意的是,我們的高運算變體 DeepSeek-V3.2-Speciale 超越了 GPT-5,且推理能力與 Gemini-3.0-Pro 不相上下。
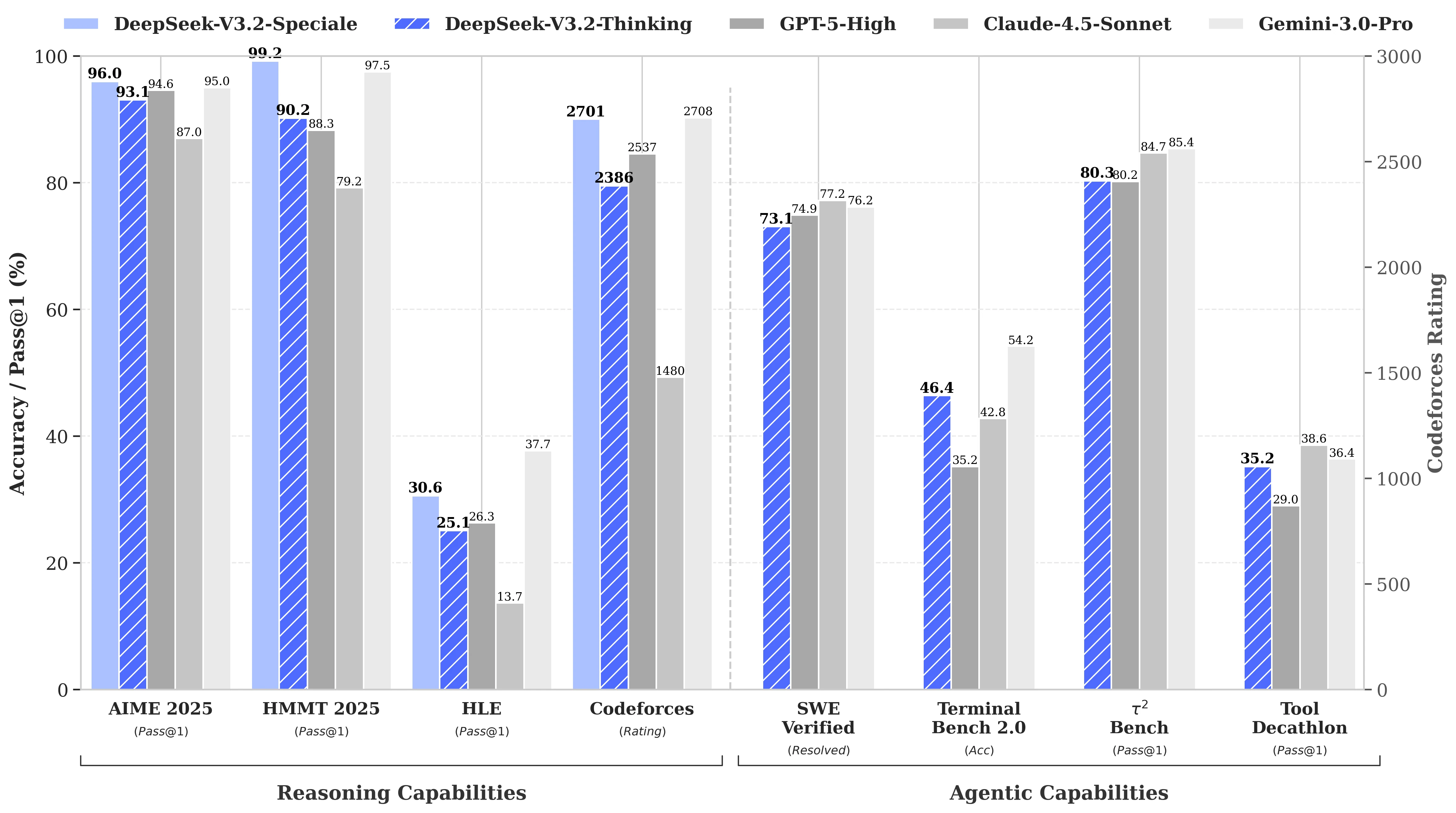
來源:Hugging Face
DeepSeek V3.2 的硬體需求
實用速度技巧
- Int8 或 Int4 量化能提供最佳的延遲/VRAM 平衡
- 使用 vLLM 或 TensorRT-LLM 後端以達到最大吞吐量
- 除非您擁有超過 1TB 的 VRAM,否則避免僅使用 FP16 部署
| 精度 | 所需 GPU 數量 | 總 VRAM | 部署備註 |
|---|---|---|---|
| FP16(完整) | 8–16× H100/A100 80GB | 1.3–1.4 TB | 僅適用於企業級叢集 |
| FP8 | 6–8× H100/A100 | 800–900 GB | 高吞吐量場景 |
| Int8 | 4–8× 80GB GPU | 670 GB | 推薦用於標準伺服器部署 |
| Int4 | 2–4× 80GB GPU | 330 GB | 實驗室/企業最實際的選項 |
| 僅 CPU | 不可行 | N/A | 請勿嘗試 |
開發者解讀
- 自訂本地推論 → 選擇 Int4 或 Int8
- 最高準確度的編碼任務 → 使用 FP8 多 GPU 叢集
- 企業級流程 → 可選擇 Novita AI
Novita 提供業界最低的 H100 隨需定價,每小時 1.80 美元起,比同效能的其他供應商便宜高達 30%。
| GPU 類型 | 規格 | 定價模式 | 1 張 GPU | 8 張 GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | 隨需 | $1.45/小時 | $11.60/小時 |
| Spot | $0.73/小時 | $5.84/小時 | ||
| A100 SXM 80GB | 80 GB VRAM | 隨需 | $1.60/小時 | $12.80/小時 |
| Spot | $0.80/小時 | $6.40/小時 |
Novita AI 的 Spot 模式是一種成本優化的 GPU 租賃選項,利用平台未使用或閒置的 GPU 容量。與預留專用硬體、保證持續使用的隨需實例不同,Spot 實例是可中斷的——價格顯著更低,通常比隨需實例便宜 40–60%。
這種定價模式能運作,是因為 Novita 會動態將閒置 GPU 分配給短期用戶,而非讓其閒置。如此一來,平台提升了整體基礎設施使用效率,開發者則能為彈性工作負載爭取到更低的運算成本。
如何存取 DeepSeek V3.2?
Novita AI 提供 DeepSeek V3.2 Exp API,上下文視窗達 163K,輸入每 token 0.216 美元,輸出每 token 0.318 美元,支援結構化輸出與函數呼叫。
請注意!Novita AI 正在推出「Build Month」活動,為開發者提供所有主要產品最高 20% 的獨家優惠!
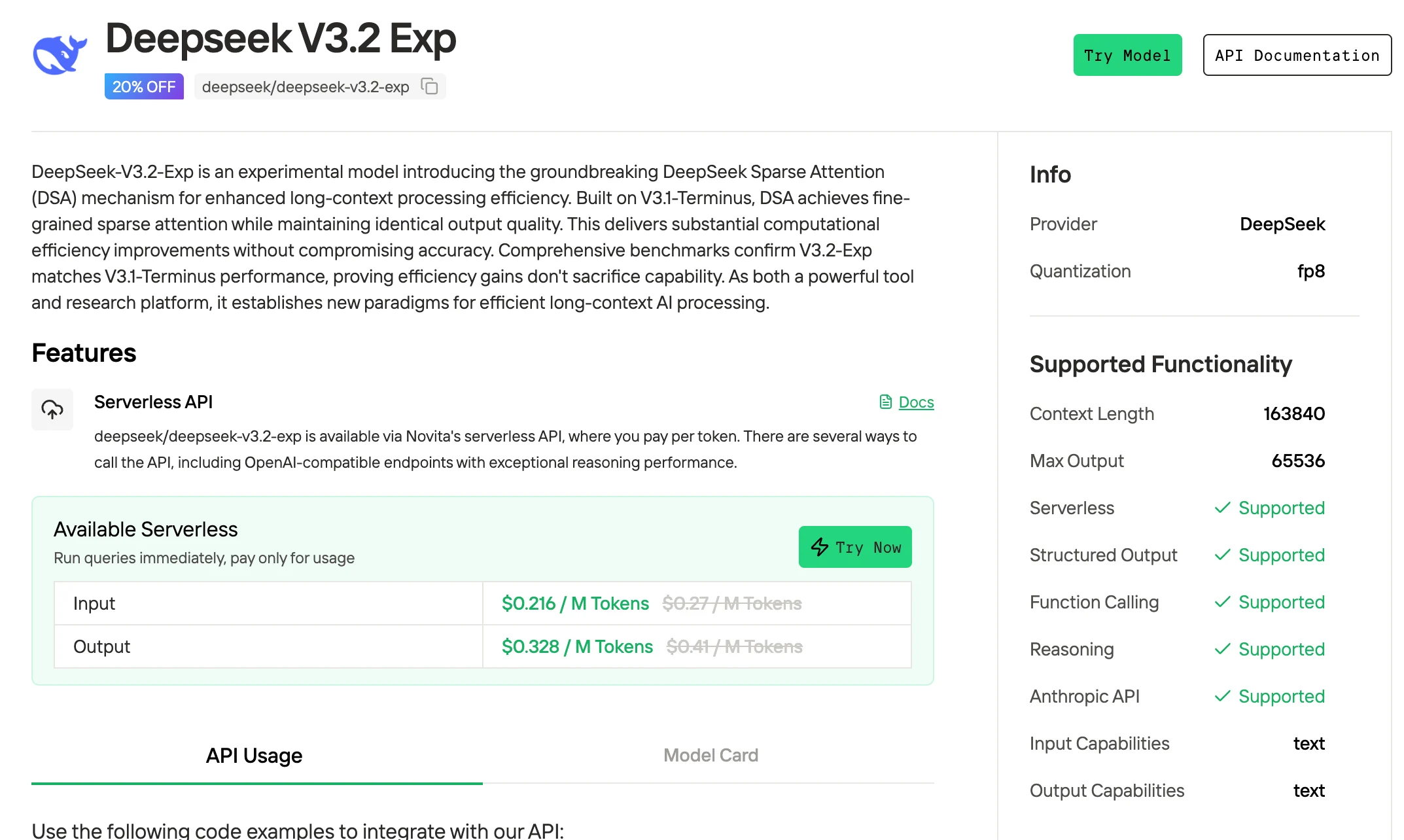
1. 透過網頁介面存取 DeepSeek V3.2(最適合初學者)
2. 透過 API 存取 DeepSeek V3.2(適合開發者)
步驟 1:登入並存取模型庫 登入您的帳號,點擊 模型庫 按鈕。

步驟 2:選擇您的模型 瀏覽可用選項,選擇符合您需求的模型。

步驟 3:開始免費試用 開始免費試用,探索所選模型的能力。
步驟 4:取得 API 金鑰 要使用 API 進行驗證,我們會提供新的 API 金鑰。進入「設定」頁面,即可按照圖中指示複製 API 金鑰。

步驟 5:安裝 API 使用對應程式語言的套件管理器安裝 API。 安裝完成後,將必要的程式庫匯入您的開發環境。使用 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下為 Python 使用者使用聊天補全 API 的範例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. 本地部署存取 DeepSeek V3.2(適合進階使用者)
| 精度 | 所需 GPU 數量 |
|---|---|
| FP16(完整) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× 80GB GPU |
| Int4 | 2–4× 80GB GPU |
| 僅 CPU | 不可行 |
安裝步驟:
- 從 HuggingFace 或 ModelScope 下載模型權重
- 選擇推論框架:支援 vLLM 或 SGLang
- 遵循官方 GitHub 儲存庫中的部署指南
4. 透過 Claude Code 等程式碼整合方式存取 DeepSeek V3.2
使用 Trae、Claude Code、Qwen Code 等 CLI 工具
如果您想在本地環境或 IDE 中使用 Novita AI 的頂級模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1)進行 AI 編碼輔助,流程非常簡單:取得 API 金鑰、安裝工具、設定環境變數,即可開始編碼。 詳細的設定指令與範例,請參考官方教學:
- Trae:在 IDE 中存取 AI 模型的逐步指南
- Claude Code:如何在 Windows、Mac 和 Linux 的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 相容 API(60 秒完成設定!)
使用 OpenAI Agents SDK 構建多代理工作流程
透過將 Novita AI 與 OpenAI Agents SDK 整合,構建進階多代理系統:
- 即插即用:在任何 OpenAI Agents 工作流程中使用 Novita AI 的 LLM。
- 支援交接、路由與工具使用:設計能委派、分流或執行函數的代理,所有功能都由 Novita AI 的模型驅動。
- Python 整合:只需將 SDK 端點設定為
https://api.novita.ai/v3/openai並使用您的 API 金鑰即可。
在第三方平台上連接 API
OpenAI 相容 API:享受無縫遷移與整合,支援 Cline 和 Cursor 等符合 OpenAI API 標準的工具。
Hugging Face:透過 Novita AI 端點,在 Spaces、管線或使用 Transformers 程式庫時使用模型。
代理與編排框架:透過官方連接器與逐步整合指南,輕鬆將 Novita AI 與合作夥伴平台如 Continue、AnythingLLM、LangChain、Dify 和 Langflow 連接。
如果您的編碼工作負載涉及複雜邏輯、長上下文、多檔案分析或代理行為,DeepSeek-V3.2(或 Speciale)是現有最強大且成本效益最高的開源選項之一。如果您的需求較輕(短腳本、簡單除錯),較小的模型更合適。
常見問題
DeepSeek-V3.2 與 DeepSeek-V3.2-Speciale 有什麼不同? DeepSeek-V3.2 針對一般編碼、長上下文推理與工具使用工作流程進行優化,而 DeepSeek-V3.2-Speciale 包含增強的演算法推理能力,適合進階除錯、複雜邏輯與競賽級任務。
在本地運行 DeepSeek-V3.2 需要多少 VRAM? DeepSeek-V3.2 的 FP16 版本需要約 1.3–1.4 TB VRAM,FP8 版本約 800–900 GB,Int8 版本約 670 GB,Int4 版本約 330 GB。DeepSeek-V3.2 無法在僅有 CPU 的環境中運行。
DeepSeek-V3.2 是否適合長程式碼庫與多檔案分析? 是的。DeepSeek-V3.2 提供 128K token 的上下文視窗與 DeepSeek 稀疏注意力機制,能在大型儲存庫中維持穩定性和參考一致性。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供可負擔且可靠的 GPU 雲端服務,用於構建和擴展 AI 應用。



