

Cet article clarifie les différences entre DeepSeek-V3.2 et DeepSeek-V3.2-Speciale en termes d’architecture, de performance, d’efficacité d’inférence et d’exigences de déploiement. En présentant des spécifications concrètes, des seuils de VRAM quantifiés, les implications des benchmarks et les voies d’accès, il fournit un guide décisionnel ciblé pour choisir l’API DeepSeek-V3.2 la plus adaptée aux tâches de codage réelles.
Attention s’il vous plaît ! Novita AI lance sa campagne « Mois de la construction », offrant aux développeurs une incitation exclusive allant jusqu’à 20% de réduction sur tous les produits principaux !
Participez au Mois de la construction !
DeepSeek V3.2 pour les développeurs
Un guide technique compact aidant les développeurs à évaluer si DeepSeek-V3.2 est l’API adaptée aux charges de travail de codage réelles.
Aperçu de l’architecture de DeepSeek V3.2
| Composant | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | Notes |
|---|---|---|---|
| Paramètres totaux | 671B MoE | 671B MoE | Taille complète du modèle inchangée |
| Paramètres actifs par token | 37B | 37B | |
| Fenêtre de contexte | 128K tokens | 128K tokens | Suffisamment long pour des bases de code entières |
| Attention | DeepSeek Sparse Attention (DSA) | DSA (réglage amélioré) | Accélération majeure pour les longues séquences |
| Précision | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | Int8/Int4 recommandé pour le déploiement |
Améliorations de DeepSeek V3.2 pertinentes pour le codage
- DeepSeek Sparse Attention (DSA)
Réduit la complexité de l’attention sur les longues séquences de code ; améliore l’efficacité de la VRAM. - Stabilité du long contexte (>100K tokens)
Maintient la cohérence des références, ce qui est important pour la navigation dans du code multi-fichiers, le traçage des dépendances et le refactoring. - Entraînement hybride CoT + utilisation d’outils
V3.2 est explicitement réglé pour les schémas « réfléchir puis agir ». - Variante Speciale
Optimisation supplémentaire pour les tâches de raisonnement algorithmique. Elle introduit le DSA, un mécanisme d’attention efficace qui réduit considérablement la complexité computationnelle tout en préservant les performances du modèle, spécifiquement optimisé pour les scénarios de long contexte.
Performance aux benchmarks de DeepSeek V3.2
DeepSeek-V3.2 offre des performances comparables à GPT-5. Notamment, notre variante à haute puissance de calcul, DeepSeek-V3.2-Speciale, surpasse GPT-5 et présente des compétences de raisonnement équivalentes à Gemini-3.0-Pro.
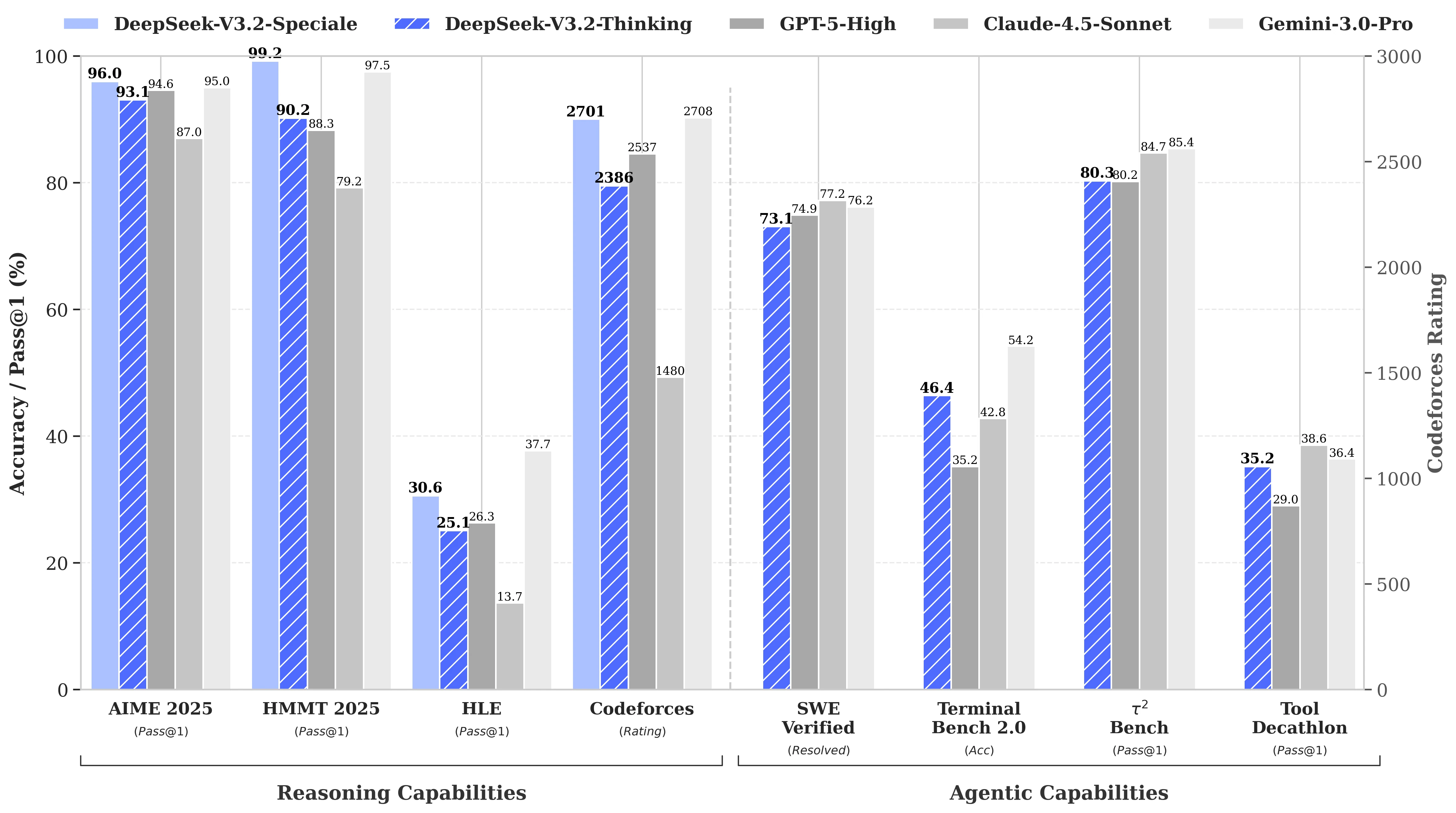
Source : Hugging Face
Essayez DeepSeek V3.2 avec 20% de réduction !
Exigences matérielles de DeepSeek V3.2
Conseils pratiques de vitesse
- La quantification Int8 ou Int4 offre le meilleur équilibre latence/VRAM
- Utilisez les backends vLLM ou TensorRT-LLM pour un débit maximal
- Évitez les déploiements en FP16 uniquement sauf si vous disposez de plus de 1 To de VRAM
| Précision | GPUs nécessaires | VRAM totale | Notes de déploiement |
|---|---|---|---|
| FP16 (complet) | 8 à 16× H100/A100 80Go | 1,3 à 1,4 To | Uniquement pour les clusters d’entreprise |
| FP8 | 6 à 8× H100/A100 | 800 à 900 Go | Paramètre de haut débit |
| Int8 | 4 à 8× GPUs 80Go | 670 Go | Recommandé pour le déploiement sur serveur standard |
| Int4 | 2 à 4× GPUs 80Go | 330 Go | Option la plus réaliste pour les laboratoires/entreprises |
| CPU uniquement | Non faisable | N/A | À ne pas tenter |
Interprétation pour les développeurs
- Pour une inférence sur site personnalisée → Int4 ou Int8
- Pour les tâches de codage nécessitant la plus grande précision → Clusters multi-GPU FP8
- Pour les pipelines d’entreprise → Vous pouvez choisir Novita AI
Novita propose les tarifs à la demande les plus bas pour les H100 à 1,80 $/h, soit jusqu’à 30% moins cher que les autres fournisseurs avec des performances de GPU identiques.
| Type de GPU | Spécification | Modèle de tarification | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80Go | 80 Go de VRAM | À la demande | 1,45 $/h | 11,60 $/h |
| Spot | 0,73 $/h | 5,84 $/h | ||
| A100 SXM 80Go | 80 Go de VRAM | À la demande | 1,60 $/h | 12,80 $/h |
| Spot | 0,80 $/h | 6,40 $/h |
Le mode Spot de Novita AI est une option de location de GPU optimisée pour les coûts, qui exploite la capacité de GPU inutilisée ou inactive de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue garantie, les instances Spot sont interruptibles — proposées à des prix significativement plus bas, généralement 40 à 60% moins chères.
Ce modèle de tarification fonctionne car Novita réaffecte dynamiquement les GPU inactifs aux utilisateurs à court terme au lieu de les laisser inutilisés. Ce faisant, la plateforme améliore l’efficacité d’utilisation globale de l’infrastructure, tandis que les développeurs bénéficient de coûts de calcul beaucoup plus bas pour des charges de travail flexibles.
Comment accéder à DeepSeek V3.2 ?
Novita AI propose des API DeepSeek V3.2 Exp avec une fenêtre de contexte de 163K à 0,216 $ par entrée et 0,318 $ par sortie, prenant en charge les sorties structurées et l’appel de fonctions.
Attention s’il vous plaît ! Novita AI lance sa campagne « Mois de la construction », offrant aux développeurs une incitation exclusive allant jusqu’à 20% de réduction sur tous les produits principaux !
1. Accéder à DeepSeek V3.2 via l’interface web (le plus simple pour les débutants)
Essayez DeepSeek V3.2 avec 20% de réduction !
2. Accéder à DeepSeek V3.2 via l’API (pour les développeurs)
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. Accéder à DeepSeek V3.2 en déploiement local (utilisateurs avancés)
| Précision | GPUs nécessaires |
|---|---|
| FP16 (complet) | 8 à 16× H100/A100 80Go |
| FP8 | 6 à 8× H100/A100 |
| Int8 | 4 à 8× GPUs 80Go |
| Int4 | 2 à 4× GPUs 80Go |
| CPU uniquement | Non faisable |
Étapes d’installation :
- Téléchargez les poids du modèle depuis HuggingFace ou ModelScope
- Choisissez le framework d’inférence : vLLM ou SGLang sont pris en charge
- Suivez le guide de déploiement dans le dépôt GitHub officiel
4. Accéder à DeepSeek V3.2 via l’intégration de code, comme avec Claude Code
Utilisation d’interface en ligne de commande (CLI) comme Trae, Claude Code, Qwen Code
Si vous souhaitez utiliser les meilleurs modèles de Novita AI (comme Qwen3-Coder, Kimi K2, DeepSeek R1) pour l’assistance au codage par IA dans votre environnement local ou votre IDE, le processus est simple : récupérez votre clé API, installez l’outil, configurez les variables d’environnement et commencez à coder.
Pour des commandes d’installation détaillées et des exemples, consultez les tutoriels officiels :
- Trae : Guide étape par étape pour accéder aux modèles d’IA dans votre IDE
- Claude Code : Comment utiliser Kimi-K2 dans Claude Code sur Windows, Mac et Linux
- Qwen Code : Comment utiliser l’API compatible OpenAI dans Qwen Code (installation en 60s !)
Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans tout flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents qui peuvent déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Définissez simplement le point de terminaison du SDK sur
https://api.novita.ai/v3/openaiet utilisez votre clé API.
Connecter l’API sur des plateformes tierces
API compatible OpenAI : Profitez d’une migration et d’une intégration sans problème avec des outils tels que Cline et Cursor, conçus pour la norme d’API OpenAI.
Hugging Face : Utilisez les modèles dans Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison de Novita AI.
Frameworks d’agents et d’orchestration : Connectez facilement Novita AI avec des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
Si votre charge de travail de codage implique une logique complexe, un long contexte, une analyse multi-fichiers ou un comportement d’agent, DeepSeek-V3.2 (ou Speciale) est l’une des options open source les plus performantes et les plus rentables disponibles. Si vos besoins sont légers (scripts courts, débogage simple), un modèle plus petit est plus adapté.
Questions fréquemment posées
Qu’est-ce qui différencie DeepSeek-V3.2 de DeepSeek-V3.2-Speciale ?
DeepSeek-V3.2 est optimisé pour le codage général, le raisonnement sur long contexte et les flux de travail utilisant des outils, tandis que DeepSeek-V3.2-Speciale intègre un raisonnement algorithmique amélioré adapté au débogage avancé, à la logique complexe et aux tâches de niveau concours.
Combien de VRAM ai-je besoin pour exécuter DeepSeek-V3.2 localement ?
DeepSeek-V3.2 nécessite environ 1,3 à 1,4 To de VRAM pour le FP16, environ 800 à 900 Go pour le FP8, environ 670 Go pour l’Int8 et environ 330 Go pour l’Int4. DeepSeek-V3.2 ne peut pas fonctionner sur des configurations CPU uniquement.
DeepSeek-V3.2 est-il adapté aux bases de code longues et à l’analyse multi-fichiers ?
Oui. DeepSeek-V3.2 dispose d’une fenêtre de contexte de 128K tokens et de l’attention éparse DeepSeek, qui maintiennent la stabilité et la cohérence des références sur de grands dépôts.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



