

يوضح هذا المقال الفروقات بين DeepSeek-V3.2 و DeepSeek-V3.2-Speciale من حيث البنية، الأداء، كفاءة الاستدلال، ومتطلبات النشر. من خلال تقديم مواصفات ملموسة، عتبات ذاكرة الوصول العشوائي المكممة (VRAM)، تداعيات معايير الأداء، ومسارات الوصول، يقدم هذا الدليل قرارًا مركزًا لاختيار واجهة برمجة التطبيقات (API) الأكثر ملاءمة من DeepSeek-V3.2 لمهام البرمجة في العالم الحقيقي.
تنبيه هام! تطلق Novita AI حملة “شهر البناء” الخاصة بها، والتي تقدم للمطورين حافزًا حصريًا يصل إلى خصم 20% على جميع المنتجات الرئيسية!
DeepSeek V3.2 للمطورين
دليل تقني مدمج يساعد المطورين على تقييم ما إذا كان DeepSeek-V3.2 هو واجهة برمجة التطبيقات (API) المناسبة لأحمال عمل البرمجة في العالم الحقيقي.
نظرة عامة على بنية Deepseek V3.2
| المكون | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | ملاحظات |
|---|---|---|---|
| إجمالي المعلمات | 671B MoE | 671B MoE | حجم النموذج الكامل دون تغيير |
| المعلمات النشطة لكل رمز (Token) | 37B | 37B | |
| نافذة السياق | 128K رمز (Token) | 128K رمز (Token) | طويلة بما يكفي لقواعد الكود بالكامل |
| آلية الانتباه | DeepSeek Sparse Attention (DSA) | DSA (ضبط محسّن) | تسريع كبير للتسلسلات الطويلة |
| الدقة | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | يوصى باستخدام Int8/Int4 للنشر |
التحسينات المتعلقة بالبرمجة في Deepseek V3.2
- DeepSeek Sparse Attention (DSA)
يقلل من تعقيد آلية الانتباه في تسلسلات الكود الطويلة؛ يحسن كفاءة ذاكرة الوصول العشوائي (VRAM). - استقرار السياق الطويل (>100K رمز)
يحافظ على تناسق المراجع - وهو أمر مهم للتنقل بين ملفات الكود المتعددة، وتتبع التبعيات، وإعادة هيكلة الكود. - تدريب هجين من سلسلة التفكير (CoT) + استخدام الأدوات
تم ضبط V3.2 بشكل صريح لأنماط “فكر ثم تصرف”. - النسخة Speciale
تحسين إضافي لمهام الاستدلال الخوارزمي. تقدم هذه النسخة آلية الانتباه DSA الفعالة، التي تقلل بشكل كبير من التعقيد الحسابي مع الحفاظ على أداء النموذج، ومحسّنة خصيصًا للسيناريوهات ذات السياق الطويل.
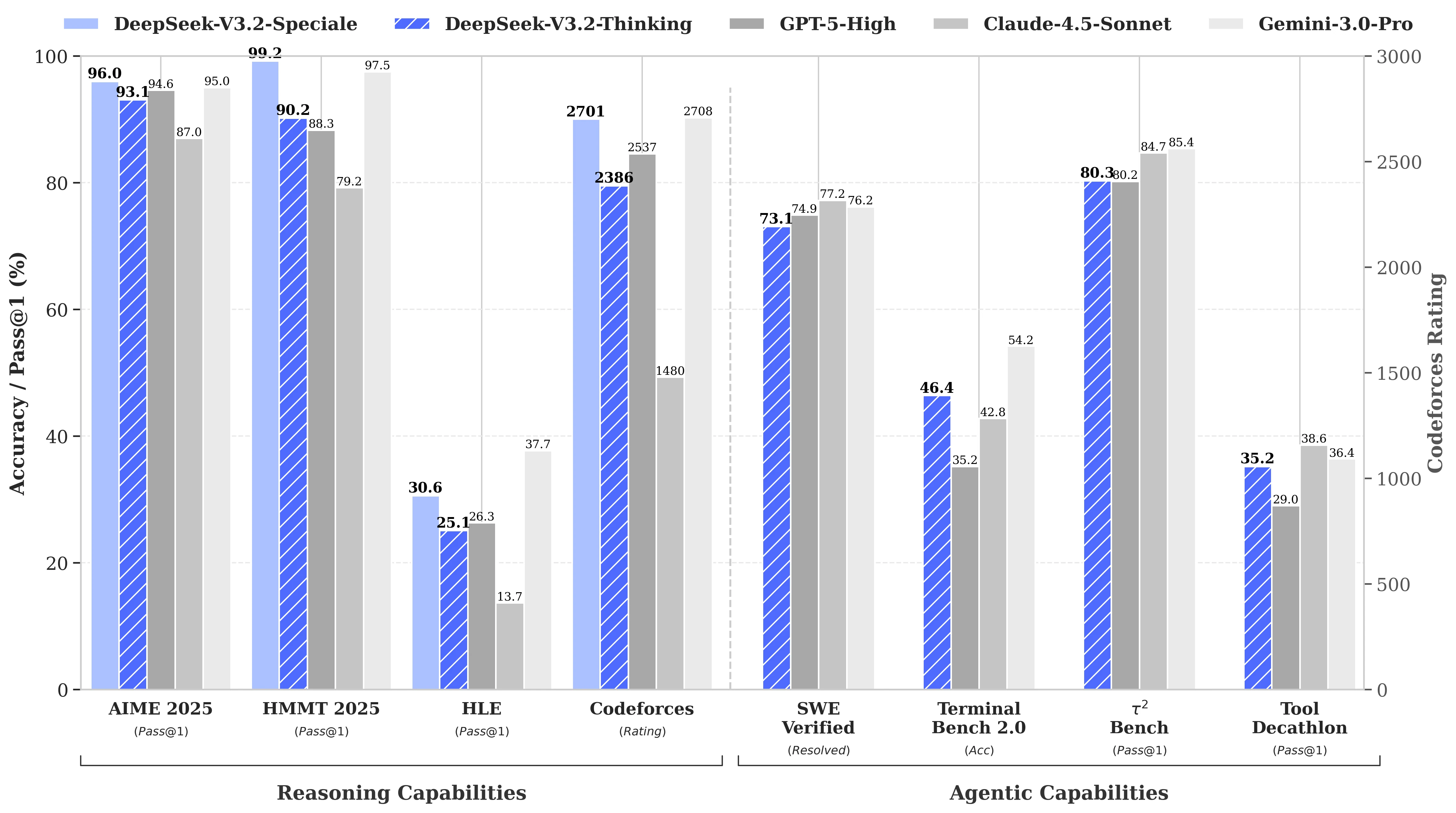
أداء معايير الاختبار لـ Deepseek V3.2
أداء DeepSeek-V3.2 قابل للمقارنة مع GPT-5. من الجدير بالذكر أن نسختنا عالية الحساب، DeepSeek-V3.2-Speciale، تتفوق على GPT-5 وتظهر كفاءة في الاستدلال مماثلة لـ Gemini-3.0-Pro.
من Hugging Face
احصل على خصم 20% على Deepseek V3.2!
متطلبات الأجهزة لـ Deepseek V3.2
نصائح عملية لتحسين السرعة
- يمنح التكميم باستخدام Int8 أو Int4 أفضل توازن بين زمن الاستجابة وذاكرة الوصول العشوائي (VRAM)
- استخدم واجهات خلفية من vLLM أو TensorRT-LLM لأقصى إنتاجية
- تجنب عمليات النشر التي تعتمد فقط على FP16 ما لم تكن لديك ذاكرة VRAM تزيد عن 1 تيرابايت
| الدقة | عدد وحدات المعالجة الرسومية (GPUs) المطلوبة | إجمالي ذاكرة الوصول العشوائي (VRAM) | ملاحظات النشر |
|---|---|---|---|
| FP16 (كامل) | 8–16× H100/A100 80GB | 1.3–1.4 تيرابايت | لمجموعات المؤسسات فقط |
| FP8 | 6–8× H100/A100 | 800–900 جيجابايت | إعدادات الإنتاجية العالية |
| Int8 | 4–8× وحدات معالجة رسومية 80GB | 670 جيجابايت | يوصى به لنشر الخوادم القياسية |
| Int4 | 2–4× وحدات معالجة رسومية 80GB | 330 جيجابايت | الخيار الأكثر واقعية للمختبرات والشركات |
| بدون وحدة معالجة رسومية (CPU فقط) | غير قابل للتطبيق | غير متاح | لا تحاول تنفيذ ذلك |
تفسير للمطورين
- للاستدلال المخصص على الموقع المحلي (on-prem) → Int4 أو Int8
- لمهام البرمجة التي تتطلب أعلى دقة → مجموعات وحدات معالجة رسومية متعددة تعمل بـ FP8
- لخطوط أنابيب المؤسسات → يمكنك اختيار Novita AI
تقدم Novita أدنى أسعار لوحدات H100 عند الطلب بسعر 1.80 دولار للساعة، أي أرخص بنسبة تصل إلى 30% من مقدمي الخدمة الآخرين الذين يقدمون أداءً مكافئًا لوحدات المعالجة الرسومية.
| نوع وحدة المعالجة الرسومية (GPU) | المواصفات | نموذج التسعير | 1× وحدة معالجة رسومية | 8× وحدات معالجة رسومية |
|---|---|---|---|---|
| H100 SXM 80GB | 80 جيجابايت VRAM | عند الطلب | 1.45 دولار/ساعة | 11.60 دولار/ساعة |
| Spot | 0.73 دولار/ساعة | 5.84 دولار/ساعة | ||
| A100 SXM 80GB | 80 جيجابايت VRAM | عند الطلب | 1.60 دولار/ساعة | 12.80 دولار/ساعة |
| Spot | 0.80 دولار/ساعة | 6.40 دولار/ساعة |
وضع Spot mode في Novita AI هو خيار استئجار وحدات معالجة رسومية مُحسّن للتكلفة، يستخدم سعة وحدات المعالجة الرسومية غير المستخدمة أو الخاملة على المنصة. على عكس الحالات عند الطلب، التي تحجز أجهزة مخصصة لاستخدام مستمر مضمون، فإن حالات Spot mode هي قابلة للقطع - معروضة بأسعار أقل بكثير، عادةً أرخص بنسبة 40–60%.
يعمل نموذج التسعير هذا لأن Novita تعيد تخصيص وحدات المعالجة الرسومية الخاملة ديناميكيًا للمستخدمين على المدى القصير بدلاً من تركها غير مستخدمة. من خلال القيام بذلك، تعزز المنصة كفاءة استخدام البنية التحتية بشكل عام، بينما يستفيد المطورون من تكاليف حسابية أقل بكثير لأحمال العمل المرنة.
كيفية الوصول إلى Deepseek V3.2؟
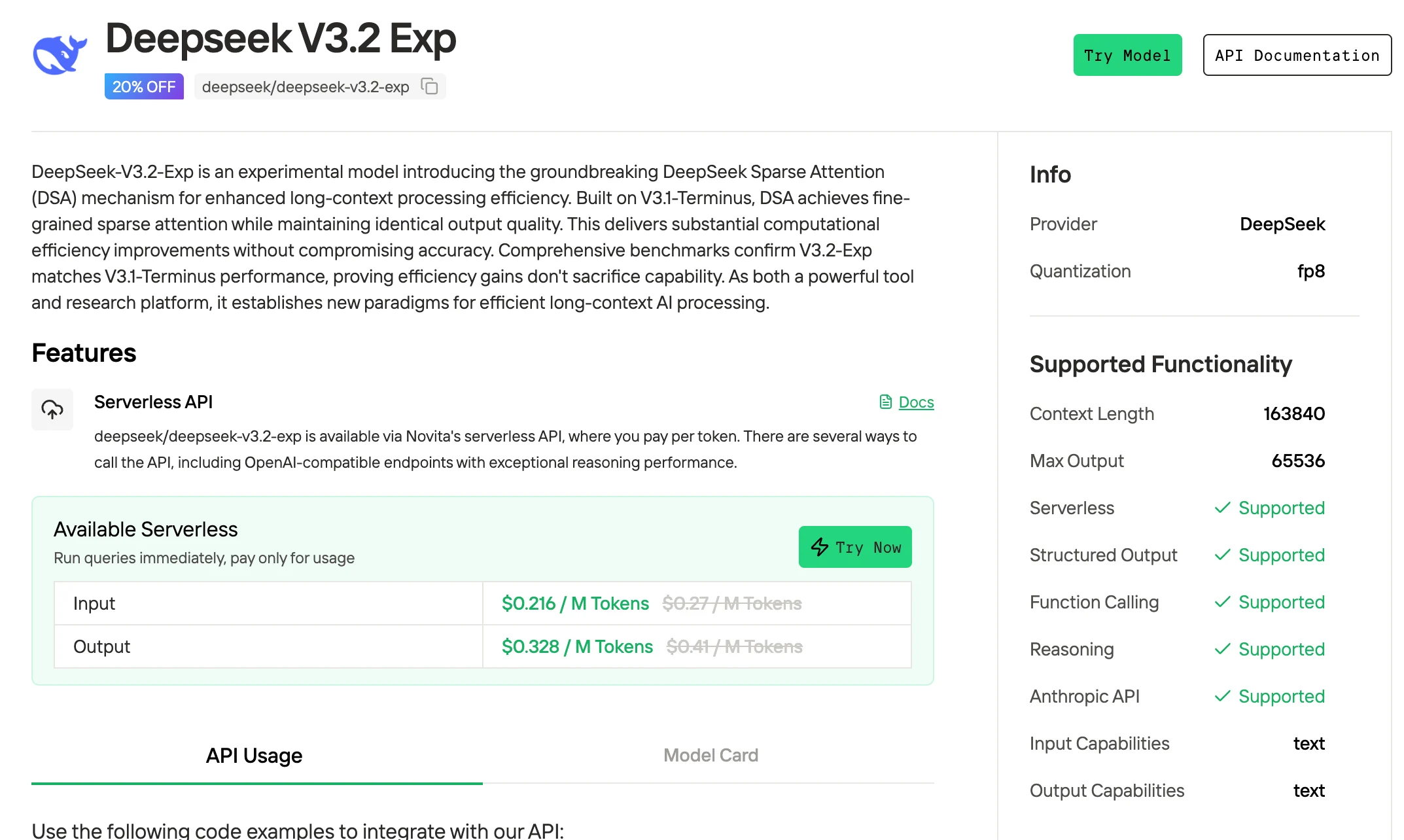
تقدم Novita AI واجهات برمجة تطبيقات (APIs) Deepseek V3.2 Exp ذات نافذة سياق تبلغ 163K رمزًا بسعر 0.216 دولار لكل مدخل و 0.318 دولار لكل مخرج، مع دعم المخرجات المنظمة واستدعاء الوظائف.
تنبيه هام! تطلق Novita AI حملة “شهر البناء” الخاصة بها، والتي تقدم للمطورين حافزًا حصريًا يصل إلى خصم 20% على جميع المنتجات الرئيسية!
1. الوصول إلى Deepseek V3.2 عبر الواجهة الويب (الأسهل للمبتدئين)
احصل على خصم 20% على Deepseek V3.2!
**2. **الوصول إلى Deepseek V3.2****عبر API (للمطورين)
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات (API)، سنقدم لك مفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات (API)
قم بتثبيت واجهة برمجة التطبيقات (API) باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات (API) باستخدام مفتاح API الخاص بك لبدء التفاعل مع نموذج اللغة الكبير (LLM) من Novita AI. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال الدردشة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
**3. **الوصول إلى Deepseek V3.2****على النشر المحلي (للمستخدمين المتقدمين)
| الدقة | عدد وحدات المعالجة الرسومية (GPUs) المطلوبة |
|---|---|
| FP16 (كامل) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× وحدات معالجة رسومية 80GB |
| Int4 | 2–4× وحدات معالجة رسومية 80GB |
| بدون وحدة معالجة رسومية (CPU فقط) | غير قابل للتطبيق |
خطوات التثبيت:
- تنزيل أوزان النموذج من HuggingFace أو ModelScope
- اختر إطار عمل الاستدلال: مدعوم من vLLM أو SGLang
- اتبع دليل النشر في مستودع GitHub الرسمي
**4. **الوصول إلى Deepseek V3.2****عبر تكامل الكود مثل Claude Code
استخدام واجهة سطر الأوامر (CLI) مثل Trae و Claude Code و Qwen Code
إذا كنت ترغب في استخدام النماذج الرائدة من Novita AI (مثل Qwen3-Coder و Kimi K2 و DeepSeek R1) للحصول على مساعدة في البرمجة بالذكاء الاصطناعي في بيئتك المحلية أو بيئة التطوير المتكاملة (IDE)، فإن العملية بسيطة: احصل على مفتاح API الخاص بك، قم بتثبيت الأداة، قم بتكوين متغيرات البيئة، وابدأ البرمجة.
للحصول على أوامر الإعداد التفصيلية والأمثلة، راجع الدروس الرسمية:
- Trae : دليل خطوة بخطوة للوصول إلى نماذج الذكاء الاصطناعي في بيئة التطوير المتكاملة (IDE) الخاصة بك
- Claude Code:كيفية استخدام Kimi-K2 في Claude Code على أنظمة Windows و Mac و Linux
- Qwen Code:كيفية استخدام واجهة برمجة تطبيقات متوافقة مع OpenAI في Qwen Code (إعداد في 60 ثانية!)
سير عمل متعدد الوكلاء باستخدام حزمة تطوير البرامج (SDK) لوكلاء OpenAI
قم ببناء أنظمة متعددة الوكلاء المتقدمة من خلال دمج Novita AI مع حزمة تطوير البرامج (SDK) لوكلاء OpenAI:
- التوصيل والتشغيل الفوري: استخدم نماذج اللغة الكبيرة (LLMs) من Novita AI في أي سير عمل لوكلاء OpenAI.
- يدعم التسليم، التوجيه، واستخدام الأدوات: صمم وكلاء يمكنهم تفويض المهام، فرزها، أو تشغيل الوظائف، وكلها مدعومة بنماذج Novita AI.
- تكامل مع بايثون: ببساطة اضبط نقطة نهاية SDK على
https://api.novita.ai/v3/openaiواستخدم مفتاح API الخاص بك.
توصيل واجهة برمجة التطبيقات (API) على منصات طرف ثالث
واجهة برمجة تطبيقات متوافقة مع OpenAI: استمتع بالهجرة والتكامل بدون متاعب مع أدوات مثل Cline و Cursor، المصممة لمعيار واجهة برمجة تطبيقات OpenAI.
Hugging Face: استخدم النماذج في Spaces، أو خطوط الأنابيب (pipelines)، أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
أطر عمل الوكلاء والتنسيق: قم بتوصيل Novita AI بسهولة مع المنصات الشريكة مثل Continue، و AnythingLLM,LangChain، و Dify و Langflow عبر موصلات رسمية وأدلة تكامل خطوة بخطوة.
إذا كان حمل عمل البرمجة الخاص بك يتضمن منطقًا معقدًا، سياقًا طويلاً، تحليلًا لملفات متعددة، أو سلوك وكلاء، فإن DeepSeek-V3.2 (أو Speciale) هو أحد أقوى الخيارات مفتوحة المصدر والأكثر كفاءة من حيث التكلفة المتاحة. إذا كانت احتياجاتك خفيفة (نصوص برمجية قصيرة، تصحيح أخطاء بسيط)، فإن نموذجًا أصغر حجمًا هو الأنسب.
الأسئلة الشائعة
ما الذي يجعل DeepSeek-V3.2 مختلفًا عن DeepSeek-V3.2-Speciale؟
تم تحسين DeepSeek-V3.2 للبرمجة العامة، والاستدلال طويل السياق، وسير عمل استخدام الأدوات، بينما يتضمن DeepSeek-V3.2-Speciale استدلالًا خوارزميًا محسّنًا مناسبًا لتصحيح الأخطاء المتقدم، والمنطق المعقد، ومهام مستوى المسابقات.
كم من ذاكرة الوصول العشوائي (VRAM) أحتاج لتشغيل DeepSeek-V3.2 محليًا؟
يتطلب DeepSeek-V3.2 ما يقارب 1.3–1.4 تيرابايت من ذاكرة الوصول العشوائي (VRAM) لـ FP16، وما يقارب 800–900 جيجابايت لـ FP8، وما يقارب 670 جيجابايت لـ Int8، وما يقارب 330 جيجابايت لـ Int4. لا يمكن تشغيل DeepSeek-V3.2 على إعدادات تعمل بوحدة المعالجة المركزية (CPU) فقط.
هل DeepSeek-V3.2 مناسب لقواعد الكود الطويلة والتحليل متعدد الملفات؟
نعم. يوفر DeepSeek-V3.2 نافذة سياق تبلغ 128K رمزًا وآلية الانتباه المتناثر DeepSeek Sparse Attention، التي تحافظ على الاستقرار وتناسق المراجع عبر المستودعات الكبيرة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومية بأسعار معقولة وموثوقة للبناء والتوسع.



