

이 글은 DeepSeek-V3.2와 DeepSeek-V3.2-Speciale의 아키텍처, 성능, 추론 효율성, 배포 요구 사항의 차이를 명확히 설명합니다. 구체적인 사양, 양자화된 VRAM 임계값, 벤치마크 영향, 접근 경로를 제시하여 실제 코딩 작업에 가장 적합한 DeepSeek-V3.2 API를 선택하기 위한 실용적인 의사 결정 가이드를 제공합니다.
주목하세요! Novita AI가 ‘빌드 월(Build Month)’ 캠페인을 시작하며, 개발자에게 모든 주요 제품에 대해 최대 20% 할인 혜택을 제공합니다!
개발자를 위한 DeepSeek V3.2
실제 코딩 워크로드에 DeepSeek-V3.2가 적합한 API인지 평가하는 데 도움을 주는 간결한 기술 가이드입니다.
DeepSeek V3.2 아키텍처 개요
| 구성 요소 | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | 비고 |
|---|---|---|---|
| 전체 파라미터 수 | 671B MoE | 671B MoE | 전체 모델 크기 동일 |
| 토큰당 활성 파라미터 수 | 37B | 37B | |
| 컨텍스트 윈도우 | 128K 토큰 | 128K 토큰 | 전체 코드베이스를 다루기에 충분히 긴 길이 |
| 어텐션 | DeepSeek Sparse Attention (DSA) | DSA (향상된 튜닝) | 긴 시퀀스에서 큰 가속 효과 |
| 정밀도 | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | 배포 시 Int8/Int4 권장 |
DeepSeek V3.2의 코딩 관련 개선 사항
- DeepSeek Sparse Attention (DSA)
긴 코드 시퀀스에 대한 어텐션 복잡도를 줄여 VRAM 효율성을 개선합니다. - 장문맥 안정성 (>100K 토큰)
참조 일관성을 유지합니다. 여러 파일을 탐색하거나 의존성을 추적하거나 리팩토링할 때 중요합니다. - 하이브리드 CoT + 도구 사용 학습
V3.2는 ‘생각한 후 행동’ 패턴에 맞게 명시적으로 튜닝되었습니다. - Speciale 변형
알고리즘 추론 작업에 대한 추가 최적화를 제공합니다. DSA는 계산 복잡성을 크게 줄이면서 모델 성능을 유지하는 효율적인 어텐션 메커니즘으로, 장문맥 시나리오에 특화되어 있습니다.
DeepSeek V3.2 벤치마크 성능
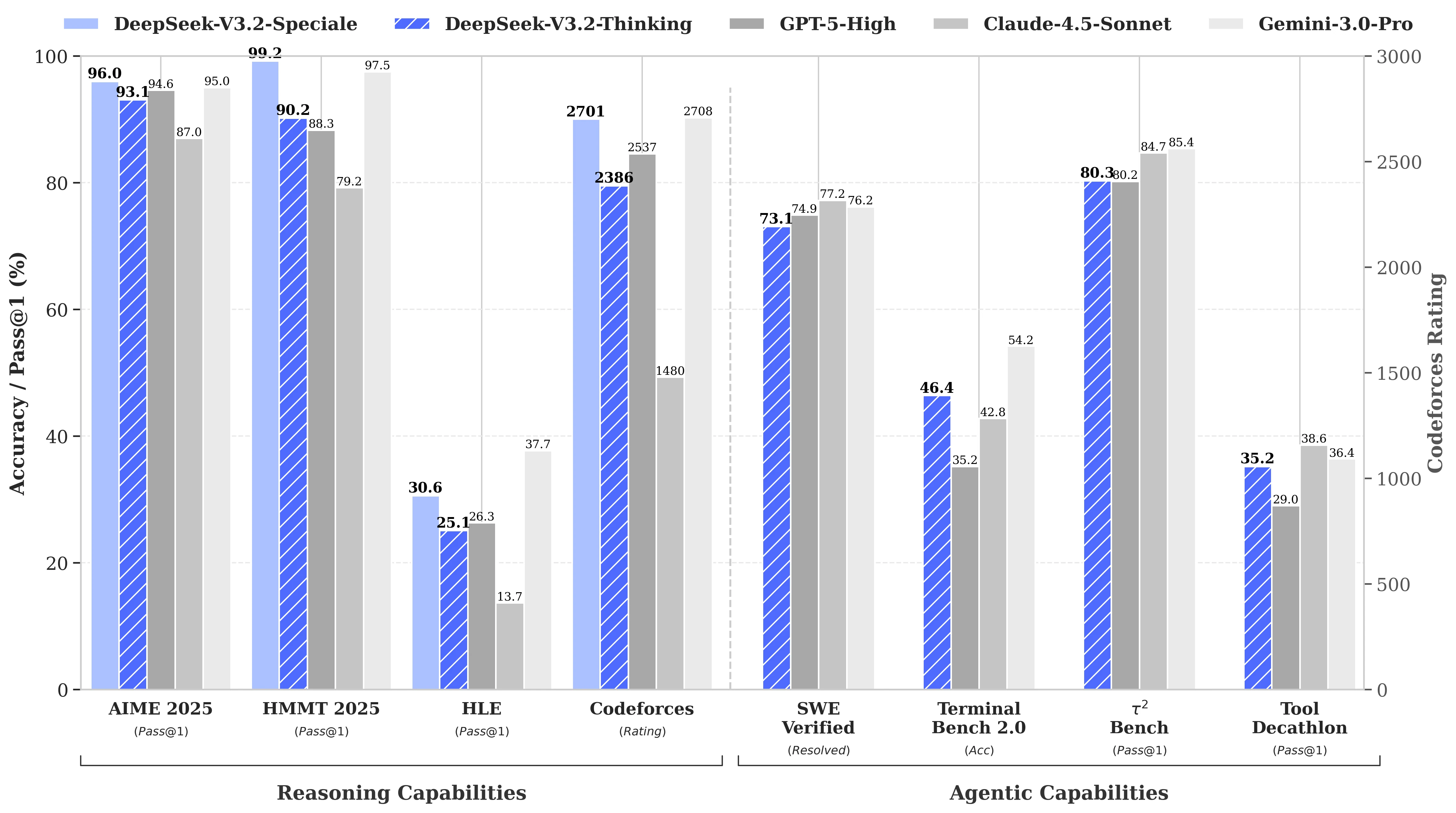
DeepSeek-V3.2는 GPT-5와 유사한 성능을 보입니다. 특히 고연산 변형인 DeepSeek-V3.2-Speciale은 GPT-5를 능가하며 Gemini-3.0-Pro 수준의 추론 능력을 보여줍니다.
출처: Hugging Face
DeepSeek V3.2 하드웨어 요구 사항
실용적인 속도 팁
- Int8 또는 Int4 양자화가 지연 시간과 VRAM 균형에 가장 좋습니다.
- 최대 처리량을 위해 vLLM 또는 TensorRT-LLM 백엔드를 사용하세요.
- 1TB 이상의 VRAM이 없다면 FP16 전용 배포는 피하세요.
| 정밀도 | 필요 GPU 수 | 총 VRAM | 배포 참고 사항 |
|---|---|---|---|
| FP16 (전체) | 8–16× H100/A100 80GB | 1.3–1.4 TB | 엔터프라이즈 클러스터 전용 |
| FP8 | 6–8× H100/A100 | 800–900 GB | 고처리량 환경 |
| Int8 | 4–8× 80GB GPU | 670 GB | 표준 서버 배포에 권장 |
| Int4 | 2–4× 80GB GPU | 330 GB | 연구소/회사에 가장 현실적인 옵션 |
| CPU 전용 | 불가 | N/A | 시도하지 마세요 |
개발자 해석
- 자체 온프레미스 추론 → Int4 또는 Int8
- 최고 정확도 코딩 작업 → FP8 멀티 GPU 클러스터
- 엔터프라이즈 파이프라인 → Novita AI를 선택하세요
Novita는 동일 GPU 성능 대비 다른 제공업체보다 최대 30% 저렴한 주문형 H100 가격을 시간당 $1.80에 제공합니다.
| GPU 유형 | 사양 | 요금제 | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | 주문형(On-Demand) | $1.45/시간 | $11.60/시간 |
| 스팟(Spot) | $0.73/시간 | $5.84/시간 | ||
| A100 SXM 80GB | 80 GB VRAM | 주문형(On-Demand) | $1.60/시간 | $12.80/시간 |
| 스팟(Spot) | $0.80/시간 | $6.40/시간 |
Novita AI의 스팟 모드는 플랫폼의 사용되지 않거나 유휴 GPU 용량을 활용하는 비용 최적화된 GPU 임대 옵션입니다. 전용 하드웨어를 예약하여 지속적인 사용을 보장하는 주문형 인스턴스와 달리, 스팟 인스턴스는 중단될 수 있습니다(interruptible) — 일반적으로 40–60% 더 저렴한 가격으로 제공됩니다.
이 요금제는 Novita가 유휴 GPU를 사용하지 않고 단기 사용자에게 동적으로 재할당하기 때문에 가능합니다. 이를 통해 플랫폼은 전체 인프라 활용 효율성을 개선하고, 개발자는 유연한 워크로드에 대해 훨씬 낮은 컴퓨팅 비용의 혜택을 누릴 수 있습니다.
DeepSeek V3.2에 접근하는 방법은?
Novita AI는 163K 컨텍스트 윈도우, 입력 $0.216, 출력 $0.318의 가격으로 구조화된 출력과 함수 호출을 지원하는 DeepSeek V3.2 Exp API를 제공합니다.
주목하세요! Novita AI가 ‘빌드 월(Build Month)’ 캠페인을 시작하며, 개발자에게 모든 주요 제품에 대해 최대 20% 할인 혜택을 제공합니다!
1. 웹 인터페이스에서 DeepSeek V3.2 접근하기 (초보자에게 가장 쉬움)
2. API를 통해 DeepSeek V3.2 접근하기 (개발자용)
1단계: 로그인 후 모델 라이브러리 접근
계정에 로그인하고 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 살펴보려면 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공해 드립니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사하세요.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후, 필요한 라이브러리를 개발 환경에 임포트하세요. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. 로컬 배포에서 DeepSeek V3.2 접근하기 (고급 사용자)
| 정밀도 | 필요 GPU 수 |
|---|---|
| FP16 (전체) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× 80GB GPU |
| Int4 | 2–4× 80GB GPU |
| CPU 전용 | 불가 |
설치 단계:
- HuggingFace 또는 ModelScope에서 모델 가중치 다운로드
- 추론 프레임워크 선택: vLLM 또는 SGLang 지원
- 공식 GitHub 저장소의 배포 가이드 참고
4. Claude Code와 같은 코드 통합을 통해 DeepSeek V3.2 접근하기
Trae, Claude Code, Qwen Code 같은 CLI 사용
로컬 환경이나 IDE에서 AI 코딩 지원을 위해 Novita AI의 최고 모델(Qwen3-Coder, Kimi K2, DeepSeek R1 등)을 사용하려면 과정은 간단합니다. API 키를 받고, 도구를 설치하고, 환경 변수를 설정한 후 코딩을 시작하면 됩니다.
자세한 설정 명령어와 예시는 공식 튜토리얼을 참조하세요:
- Trae : IDE에서 AI 모델에 접근하는 단계별 가이드
- Claude Code: Windows, Mac, Linux에서 Claude Code에서 Kimi-K2 사용하는 방법
- Qwen Code: Qwen Code에서 OpenAI 호환 API 사용하는 방법 (60초 설정!)
OpenAI Agents SDK를 사용한 멀티 에이전트 워크플로우
Novita AI와 OpenAI Agents SDK를 통합하여 고급 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: 모든 OpenAI Agents 워크플로우에서 Novita AI의 LLM을 사용하세요.
- 핸드오프, 라우팅, 도구 사용 지원: 위임, 분류 또는 함수 실행이 가능한 에이전트를 설계할 수 있으며, 모두 Novita AI의 모델로 구동됩니다.
- Python 통합: SDK 엔드포인트를
https://api.novita.ai/v3/openai로 설정하고 API 키를 사용하세요.
타사 플랫폼에서 API 연결
OpenAI 호환 API: Cline 및 Cursor와 같은 도구와 번거롭지 않은 마이그레이션 및 통합을 지원합니다. OpenAI API 표준에 맞게 설계되었습니다.
Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 모델을 사용하세요.
에이전트 및 오케스트레이션 프레임워크: Continue, AnythingLLM, LangChain, Dify, Langflow와 같은 파트너 플랫폼을 공식 커넥터와 단계별 통합 가이드를 통해 쉽게 연결할 수 있습니다.
코딩 워크로드에 복잡한 로직, 긴 컨텍스트, 다중 파일 분석 또는 에이전트 동작이 포함된다면 DeepSeek-V3.2(또는 Speciale)는 가장 강력하고 비용 효율적인 오픈 소스 옵션 중 하나입니다. 반면 가벼운 요구 사항(짧은 스크립트, 간단한 디버깅)이라면 더 작은 모델이 더 적합합니다.
자주 묻는 질문
DeepSeek-V3.2와 DeepSeek-V3.2-Speciale의 차이점은 무엇인가요?
DeepSeek-V3.2는 일반 코딩, 장문맥 추론 및 도구 사용 워크플로우에 최적화되어 있는 반면, DeepSeek-V3.2-Speciale는 고급 디버깅, 복잡한 로직 및 대회 수준의 작업에 적합한 향상된 알고리즘 추론 기능을 포함합니다.
DeepSeek-V3.2를 로컬에서 실행하려면 얼마나 많은 VRAM이 필요한가요?
DeepSeek-V3.2는 FP16에 약 1.3–1.4TB VRAM, FP8에 약 800–900GB, Int8에 약 670GB, Int4에 약 330GB의 VRAM이 필요합니다. DeepSeek-V3.2는 CPU 전용 설정에서는 실행할 수 없습니다.
DeepSeek-V3.2는 긴 코드베이스와 다중 파일 분석에 적합한가요?
네. DeepSeek-V3.2는 128K-토큰 컨텍스트 윈도우와 DeepSeek Sparse Attention을 제공하여 대규모 저장소에서 안정성과 참조 일관성을 유지합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.



