

Dieser Artikel erläutert die Unterschiede zwischen DeepSeek-V3.2 und DeepSeek-V3.2-Speciale in Bezug auf Architektur, Leistung, Inferenzeffizienz und Bereitstellungsanforderungen. Anhand konkreter Spezifikationen, quantisierter VRAM-Schwellenwerte, Benchmark-Implikationen und Zugriffspfade bietet er eine gezielte Entscheidungshilfe zur Auswahl der am besten geeigneten DeepSeek-V3.2-API für reale Programmieraufgaben.
Achtung! Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
Nehmen Sie am Build Month teil!
DeepSeek V3.2 für Entwickler
Ein kompakter technischer Leitfaden, der Entwicklern hilft zu bewerten, ob DeepSeek-V3.2 die richtige API für reale Programmierworkloads ist.
Architekturübersicht von DeepSeek V3.2
| Komponente | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | Hinweise |
|---|---|---|---|
| Gesamtparameter | 671B MoE | 671B MoE | Volle Modellgröße unverändert |
| Aktive Parameter pro Token | 37B | 37B | |
| Kontextfenster | 128K Token | 128K Token | Lang genug für gesamte Codebasen |
| Aufmerksamkeitsmechanismus | DeepSeek Sparse Attention (DSA) | DSA (verbessertes Tuning) | Deutliche Beschleunigung für lange Sequenzen |
| Präzision | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | Int8/Int4 für die Bereitstellung empfohlen |
Für die Programmierung relevante Verbesserungen von DeepSeek V3.2
- DeepSeek Sparse Attention (DSA)
Reduziert die Aufmerksamkeitskomplexität bei langen Code-Sequenzen; verbessert die VRAM-Effizienz. - Long-Context-Stabilität (>100K Token)
Bewahrt die Referenzkonsistenz – wichtig für die Navigation in mehreren Dateien, Abhängigkeitsverfolgung und Refactoring. - Hybride CoT + Tool-Nutzung-Training
V3.2 ist explizit für „Denken-dann-Handeln“-Muster optimiert. - Speciale-Variante
Zusätzliche Optimierung für algorithmische Denkaufgaben. Sie führt DSA ein, einen effizienten Aufmerksamkeitsmechanismus, der die Rechenkomplexität erheblich reduziert und gleichzeitig die Modellleistung beibehält, speziell optimiert für Long-Context-Szenarien.
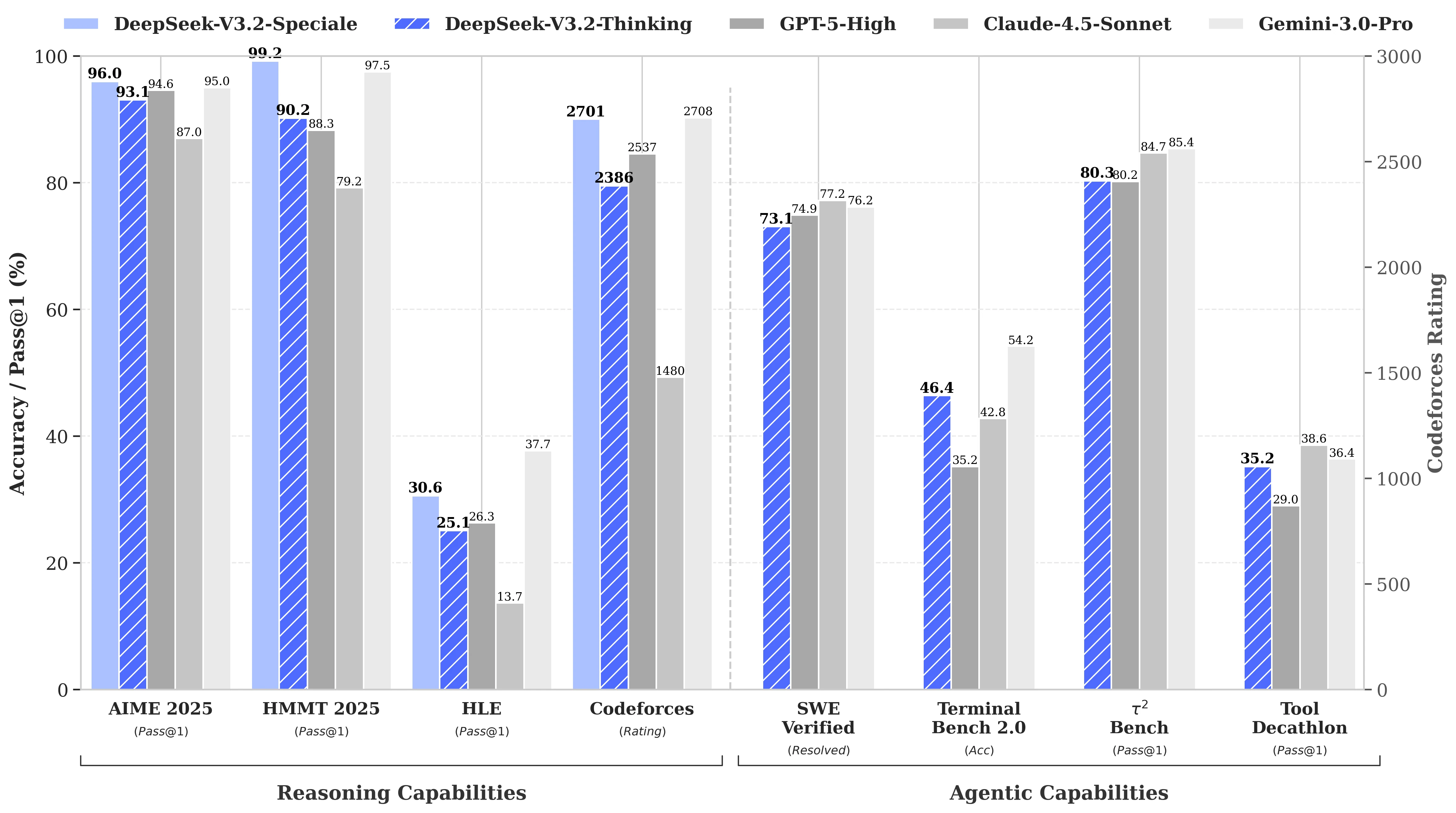
Benchmark-Leistung von DeepSeek V3.2
DeepSeek-V3.2 erreicht eine vergleichbare Leistung wie GPT-5. Insbesondere unsere High-Compute-Variante, DeepSeek-V3.2-Speciale, übertrifft GPT-5 und weist eine Denkleistung auf, die mit Gemini-3.0-Pro mithalten kann.
Von Hugging Face
Testen Sie DeepSeek V3.2 mit 20 % Rabatt!
Hardware-Anforderungen von DeepSeek V3.2
Praktische Geschwindigkeitstipps
- Int8- oder Int4-Quantisierung bietet das beste Verhältnis von Latenz zu VRAM
- Nutzen Sie vLLM- oder TensorRT-LLM-Backends für maximalen Durchsatz
- Vermeiden Sie reine FP16-Bereitstellungen, es sei denn, Sie haben über 1 TB VRAM
| Präzision | Benötigte GPUs | Gesamt-VRAM | Bereitstellungshinweise |
|---|---|---|---|
| FP16 (voll) | 8–16× H100/A100 80GB | 1,3–1,4 TB | Nur für Unternehmenscluster |
| FP8 | 6–8× H100/A100 | 800–900 GB | Einstellung für hohen Durchsatz |
| Int8 | 4–8× 80-GB-GPUs | 670 GB | Empfohlen für Standard-Serverbereitstellung |
| Int4 | 2–4× 80-GB-GPUs | 330 GB | Realistischste Option für Labore/Unternehmen |
| Nur CPU | Nicht durchführbar | N/V | Nicht versuchen |
Entwicklerhinweis
- Für benutzerdefinierte On-Premise-Inferenz → Int4 oder Int8
- Für Programmieraufgaben mit höchster Genauigkeit → FP8-Multi-GPU-Cluster
- Für Unternehmenspipelines → Sie können Novita AI wählen
Novita bietet die niedrigsten On-Demand-H100-Preise von 1,80 $/Stunde, bis zu 30 % günstiger als andere Anbieter mit identischer GPU-Leistung.
| GPU-Typ | Spezifikation | Preismodell | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | On-Demand | 1,45 $/Stunde | 11,60 $/Stunde |
| Spot | 0,73 $/Stunde | 5,84 $/Stunde | ||
| A100 SXM 80GB | 80 GB VRAM | On-Demand | 1,60 $/Stunde | 12,80 $/Stunde |
| Spot | 0,80 $/Stunde | 6,40 $/Stunde |
Der Spot-Modus von Novita AI ist eine kostengünstige GPU-Mietoption, die die ungenutzte oder Leerlauf-GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für garantierte kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – sie werden zu deutlich niedrigeren Preisen angeboten, typischerweise 40–60 % günstiger.
Dieses Preismodell funktioniert, weil Novita ungenutzte GPUs dynamisch an Kurzzeitnutzer neu zuweist, anstatt sie ungenutzt zu lassen. Dadurch verbessert die Plattform die gesamte Infrastrukturauslastungseffizienz, während Entwickler von deutlich niedrigeren Rechenkosten für flexible Workloads profitieren.
Wie greife ich auf DeepSeek V3.2 zu?
Novita AI bietet DeepSeek V3.2 Exp-APIs mit einem 163K-Kontextfenster für 0,216 $ pro Eingabe und 0,318 $ pro Ausgabe an, die strukturierte Ausgaben und Funktionsaufrufe unterstützen.
Achtung! Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
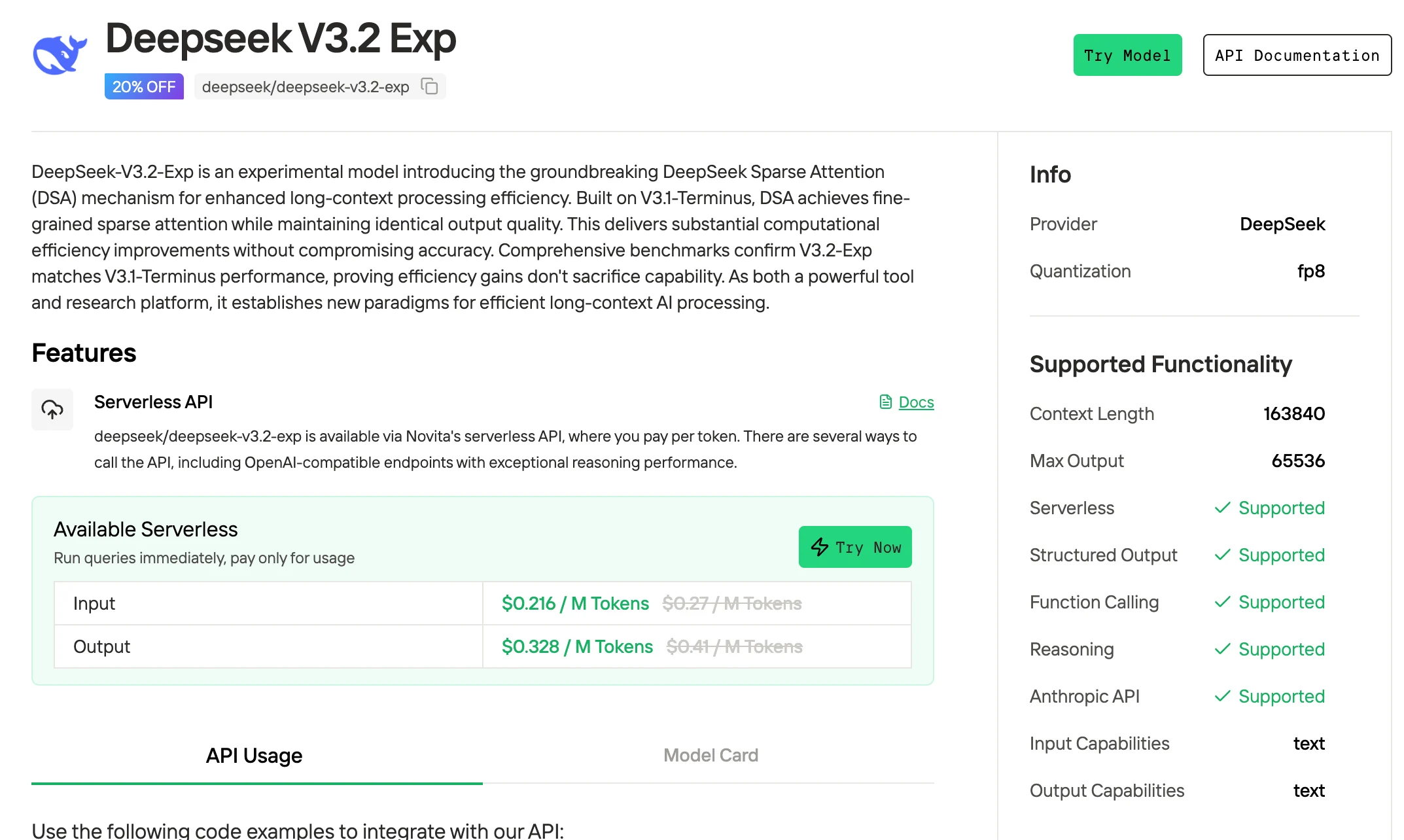
1. Zugriff auf DeepSeek V3.2 über die Weboberfläche (am einfachsten für Einsteiger)
Testen Sie DeepSeek V3.2 mit 20 % Rabatt!
2. Zugriff auf DeepSeek V3.2 über die API (für Entwickler)
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. Zugriff auf DeepSeek V3.2 über lokale Bereitstellung (für fortgeschrittene Benutzer)
| Präzision | Benötigte GPUs |
|---|---|
| FP16 (voll) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× 80-GB-GPUs |
| Int4 | 2–4× 80-GB-GPUs |
| Nur CPU | Nicht durchführbar |
Installationsschritte:
- Laden Sie die Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie ein Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie den Bereitstellungsleitfaden im offiziellen GitHub-Repository
4. Zugriff auf DeepSeek V3.2 über Code-Integration wie Claude Code
Nutzung von CLIs wie Trae, Claude Code, Qwen Code
Wenn Sie die Top-Modelle von Novita AI (wie Qwen3-Coder, Kimi K2, DeepSeek R1) für KI-gestützte Programmierhilfe in Ihrer lokalen Umgebung oder IDE nutzen möchten, ist der Prozess einfach: Holen Sie sich Ihren API-Schlüssel, installieren Sie das Tool, konfigurieren Sie Umgebungsvariablen und beginnen Sie mit dem Programmieren.
Ausführliche Einrichtungsbefehle und Beispiele finden Sie in den offiziellen Tutorials:
- Trae: Schritt-für-Schritt-Anleitung zum Zugriff auf KI-Modelle in Ihrer IDE
- Claude Code: So verwenden Sie Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code: So verwenden Sie die OpenAI-kompatible API in Qwen Code (60-Sekunden-Einrichtung!)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme durch Integration von Novita AI mit dem OpenAI Agents SDK:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Setzen Sie einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwenden Sie Ihren API-Schlüssel.
API auf Drittanbieterplattformen verbinden
OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Hugging Face: Nutzen Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsleitfäden.
Wenn Ihr Programmierworkload komplexe Logik, langen Kontext, Multi-Datei-Analysen oder Agentenverhalten umfasst, ist DeepSeek-V3.2 (oder Speciale) eine der stärksten und kosteneffizientesten Open-Source-Optionen, die verfügbar sind. Wenn Ihre Anforderungen gering sind (kurze Skripte, einfaches Debugging), ist ein kleineres Modell besser geeignet.
Häufig gestellte Fragen
Was unterscheidet DeepSeek-V3.2 von DeepSeek-V3.2-Speciale?
DeepSeek-V3.2 ist für allgemeine Programmieraufgaben, Long-Context-Denken und Tool-Nutzung-Workflows optimiert, während DeepSeek-V3.2-Speciale eine verbesserte algorithmische Denkleistung für fortgeschrittenes Debugging, komplexe Logik und wettbewerbsorientierte Aufgaben bietet.
Wie viel VRAM benötige ich, um DeepSeek-V3.2 lokal auszuführen?
DeepSeek-V3.2 benötigt ~1,3–1,4 TB VRAM für FP16, ~800–900 GB für FP8, ~670 GB für Int8 und ~330 GB für Int4. DeepSeek-V3.2 kann nicht auf reinen CPU-Systemen ausgeführt werden.
Ist DeepSeek-V3.2 für lange Codebasen und Multi-Datei-Analysen geeignet?
Ja. DeepSeek-V3.2 bietet ein 128K-Token-Kontextfenster und DeepSeek Sparse Attention, die Stabilität und Referenzkonsistenz in großen Repositories gewährleisten.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.



