

В этой статье разбираются различия между DeepSeek-V3.2 и DeepSeek-V3.2-Speciale в архитектуре, производительности, эффективности инференса и требованиях к развертыванию. Представляя конкретные спецификации, пороги квантованной VRAM, результаты бенчмарков и способы доступа, материал служит целенаправленным руководством для выбора наиболее подходящего API DeepSeek-V3.2 для реальных задач работы с кодом.
Внимание! Novita AI запускает кампанию «Месяц разработки», предлагая разработчикам эксклюзивную скидку до 20% на все основные продукты!
Войдите в свой Месяц разработки!
DeepSeek V3.2 для разработчиков
Краткое техническое руководство, помогающее разработчикам оценить, подходит ли им API DeepSeek-V3.2 для реальных рабочих нагрузок, связанных с кодом.
Обзор архитектуры Deepseek V3.2
| Компонент | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | Примечания |
|---|---|---|---|
| Всего параметров | 671B MoE | 671B MoE | Полный размер модели не изменился |
| Активных параметров на токен | 37B | 37B | |
| Контекстное окно | 128K токенов | 128K токенов | Достаточно для целых кодовых баз |
| Механизм внимания | DeepSeek Sparse Attention (DSA) | DSA (улучшенная настройка) | Существенное ускорение для длинных последовательностей |
| Точность | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | Int8/Int4 рекомендуется для развертывания |
Улучшения DeepSeek V3.2, важные для работы с кодом
- DeepSeek Sparse Attention (DSA)
Снижает сложность механизма внимания для длинных последовательностей кода; повышает эффективность использования VRAM. - Стабильность при длинном контексте (>100K токенов)
Сохраняет согласованность ссылок — это важно для навигации по многофайловым кодовым базам, отслеживания зависимостей и рефакторинга. - Гибридное обучение CoT + использованию инструментов
V3.2 специально настроен для паттернов «сначала подумай, потом действуй». - Версия Speciale
Дополнительная оптимизация для задач алгоритмического рассуждения. В ней представлен DSA — эффективный механизм внимания, который значительно снижает вычислительную сложность при сохранении производительности модели, специально оптимизированный для сценариев с длинным контекстом.
Производительность DeepSeek V3.2 в бенчмарках
Производительность DeepSeek-V3.2 сопоставима с GPT-5. Примечательно, что наш вариант с высокой вычислительной мощностью, DeepSeek-V3.2-Speciale, превосходит GPT-5 и демонстрирует уровень рассуждений, не уступающий Gemini-3.0-Pro.
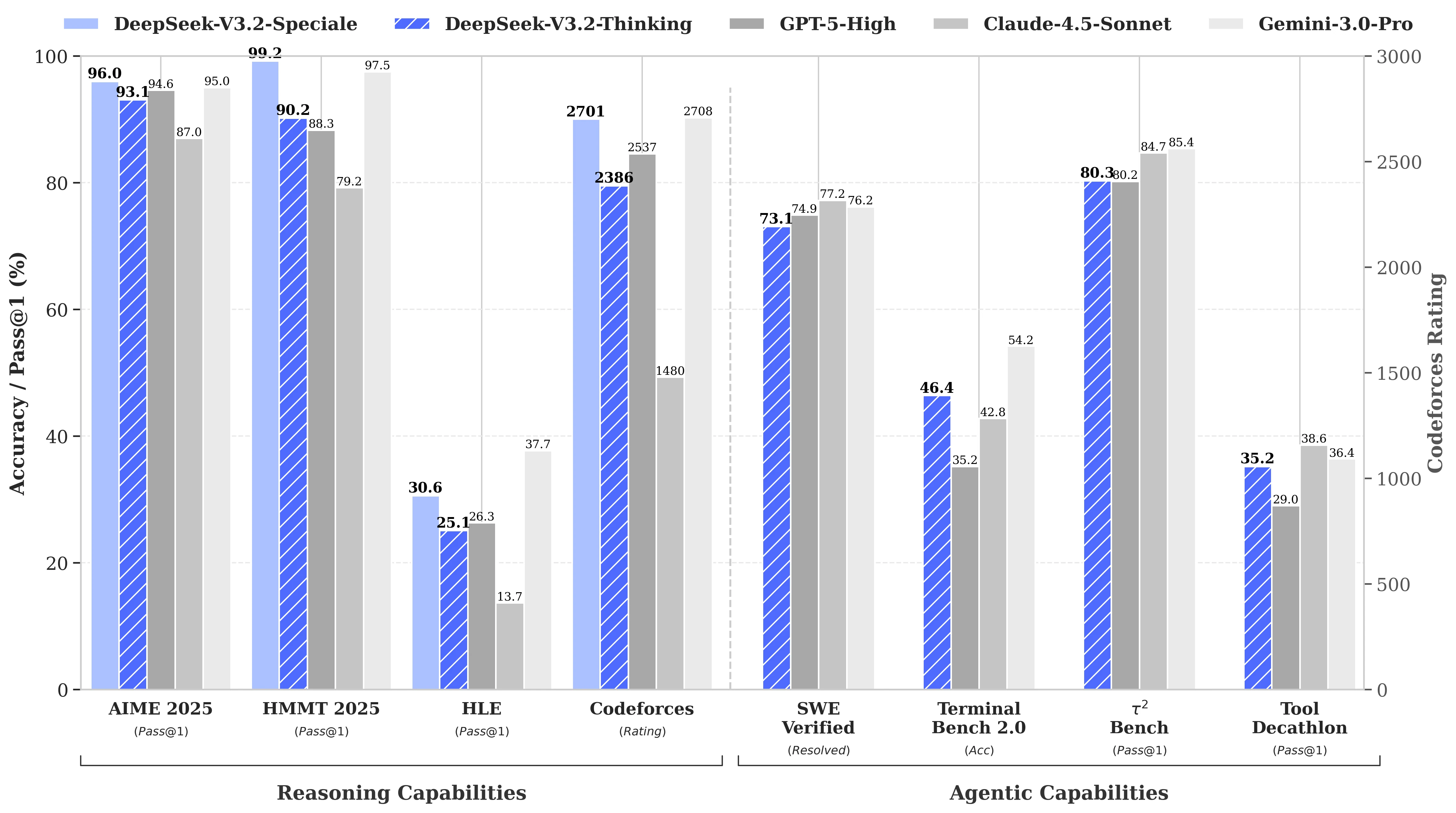
Из Hugging Face
Попробуйте DeepSeek V3.2 со скидкой 20%!
Требования к оборудованию для DeepSeek V3.2
Практические советы по скорости
- Квантование Int8 или Int4 обеспечивает наилучший баланс задержки и VRAM
- Используйте бэкенды vLLM или TensorRT-LLM для максимальной пропускной способности
- Избегайте развертывания только в FP16, если у вас нет более 1 ТБ VRAM
| Точность | Необходимые GPU | Общий объем VRAM | Примечания по развертыванию |
|---|---|---|---|
| FP16 (полная) | 8–16× H100/A100 80GB | 1.3–1.4 ТБ | Только корпоративные кластеры |
| FP8 | 6–8× H100/A100 | 800–900 ГБ | Сценарии с высокой пропускной способностью |
| Int8 | 4–8× 80GB GPU | 670 ГБ | Рекомендуется для стандартного серверного развертывания |
| Int4 | 2–4× 80GB GPU | 330 ГБ | Наиболее реалистичный вариант для лабораторий и компаний |
| Только CPU | Нецелесообразно | N/A | Не пытайтесь |
Интерпретация для разработчиков
- Для кастомного инференса на собственных серверах → Int4 или Int8
- Для задач работы с кодом с максимальной точностью → Многопроцессорные кластеры FP8
- Для корпоративных конвейеров → Вы можете выбрать Novita AI
Novita предлагает самые низкие цены на аренду H100 по требованию — от $1.80 в час, что на 30% дешевле, чем у других провайдеров с идентичной производительностью GPU.
| Тип GPU | Спецификация | Модель тарификации | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 ГБ VRAM | По требованию | $1.45/час | $11.60/час |
| Spot | $0.73/час | $5.84/час | ||
| A100 SXM 80GB | 80 ГБ VRAM | По требованию | $1.60/час | $12.80/час |
| Spot | $0.80/час | $6.40/час |
Spot-режим Novita AI — это оптимизированная по стоимости опция аренды GPU, которая использует неиспользуемую или простаивающую мощность GPU платформы. В отличие от инстансов по требованию, которые резервируют выделенное оборудование для гарантированного непрерывного использования, Spot-инстансы являются прерываемыми — они предлагаются по значительно более низким ценам, обычно на 40–60% дешевле.
Эта модель тарификации работает, потому что Novita динамически перераспределяет простаивающие GPU краткосрочным пользователям вместо того, чтобы оставлять их неиспользуемыми. Благодаря этому платформа повышает общую эффективность использования инфраструктуры, а разработчики получают значительно более низкие затраты на вычисления для гибких рабочих нагрузок.
Как получить доступ к DeepSeek V3.2?
Novita AI предлагает API DeepSeek V3.2 Exp с контекстным окном в 163K токенов по цене $0.216 за вход и $0.318 за выход, с поддержкой структурированных выводов и вызова функций.
Внимание! Novita AI запускает кампанию «Месяц разработки», предлагая разработчикам эксклюзивную скидку до 20% на все основные продукты!
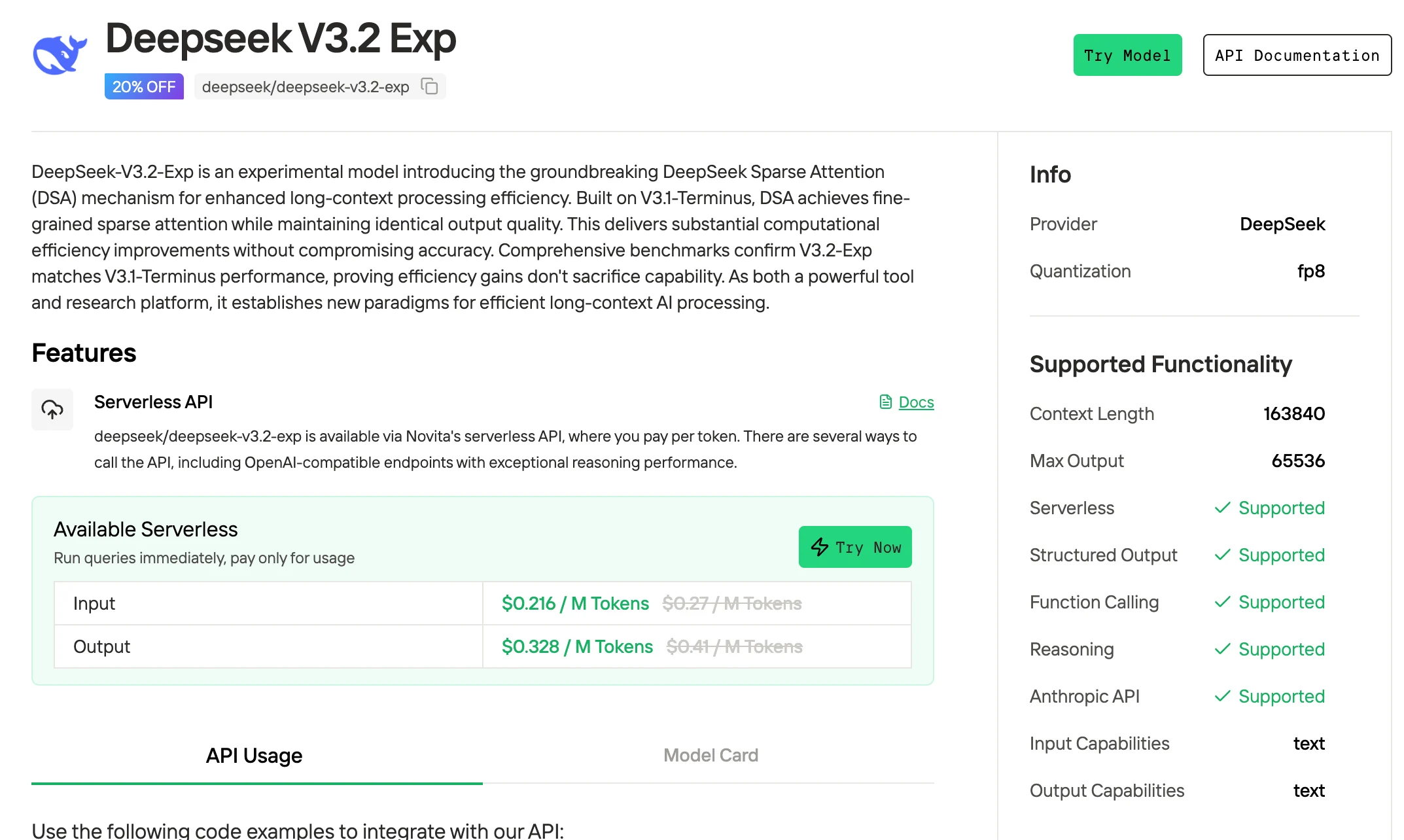
1. Получение доступа к DeepSeek V3.2 через веб-интерфейс (самый простой способ для начинающих)
Попробуйте DeepSeek V3.2 со скидкой 20%!
2. Получение доступа к DeepSeek V3.2 через API (для разработчиков)
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Ниже приведен пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. Получение доступа к DeepSeek V3.2 при локальном развертывании (для продвинутых пользователей)
| Точность | Необходимые GPU |
|---|---|
| FP16 (полная) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× 80GB GPU |
| Int4 | 2–4× 80GB GPU |
| Только CPU | Нецелесообразно |
Шаги установки:
- Скачайте веса модели с HuggingFace или ModelScope
- Выберите фреймворк для инференса: поддерживаются vLLM или SGLang
- Следуйте руководству по развертыванию в официальном репозитории GitHub
4. Получение доступа к DeepSeek V3.2 через интеграцию с кодом, например с Claude Code
Использование CLI, таких как Trae, Claude Code, Qwen Code
Если вы хотите использовать топовые модели Novita AI (такие как Qwen3-Coder, Kimi K2, DeepSeek R1) для помощи в написании кода с ИИ в вашей локальной среде или IDE, процесс прост: получите ваш API-ключ, установите инструмент, настройте переменные окружения и начните писать код.
Для подробных команд настройки и примеров ознакомьтесь с официальными руководствами:
- Trae : Пошаговое руководство по доступу к ИИ-моделям в вашем IDE
- Claude Code: Как использовать Kimi-K2 в Claude Code на Windows, Mac и Linux
- Qwen Code: Как использовать совместимый с OpenAI API в Qwen Code (настройка за 60 секунд!)
Мультиагентные рабочие процессы с SDK OpenAI Agents
Создавайте продвинутые мультиагентные системы, интегрировав Novita AI с SDK OpenAI Agents:
- Подключи и работай: Используйте LLM Novita AI в любом рабочем процессе OpenAI Agents.
- Поддерживает передачу задач, маршрутизацию и использование инструментов: Создавайте агентов, которые могут делегировать задачи, сортировать их или запускать функции, все на основе моделей Novita AI.
- Интеграция с Python: Просто установите конечную точку SDK на
https://api.novita.ai/v3/openaiи используйте ваш API-ключ.
Подключение API на сторонних платформах
Совместимый с OpenAI API: Наслаждайтесь простой миграцией и интеграцией с такими инструментами, как Cline и Cursor, разработанными по стандарту API OpenAI.
Hugging Face: Используйте модели в Spaces, конвейерах или с библиотекой Transformers через эндпоинты Novita AI.
Фреймворки для агентов и оркестрации: Легко подключайте Novita AI к партнерским платформам, таким как Continue, AnythingLLM,LangChain, Dify и Langflow через официальные коннекторы и пошаговые руководства по интеграции.
Если ваша рабочая нагрузка с кодом включает сложную логику, длинный контекст, анализ нескольких файлов или поведение агентов, DeepSeek-V3.2 (или Speciale) является одним из самых мощных и экономически эффективных открытых вариантов. Если ваши потребности невелики (короткие скрипты, простое отладка), более подойдет меньшая модель.
Часто задаваемые вопросы
В чем разница между DeepSeek-V3.2 и DeepSeek-V3.2-Speciale?
DeepSeek-V3.2 оптимизирован для общего программирования, рассуждений с длинным контекстом и рабочих процессов с использованием инструментов, в то время как DeepSeek-V3.2-Speciale включает улучшенные алгоритмические рассуждения, подходящие для продвинутой отладки, сложной логики и задач конкурентного уровня.
Сколько VRAM нужно для запуска DeepSeek-V3.2 локально?
Для запуска DeepSeek-V3.2 требуется ~1.3–1.4 ТБ VRAM для FP16, ~800–900 ГБ для FP8, ~670 ГБ для Int8 и ~330 ГБ для Int4. DeepSeek-V3.2 не может работать на конфигурациях только с CPU.
Подходит ли DeepSeek-V3.2 для больших кодовых баз и анализа нескольких файлов?
Да. DeepSeek-V3.2 имеет контекстное окно в 128K токенов и механизм DeepSeek Sparse Attention, которые обеспечивают стабильность и согласованность ссылок в больших репозиториях.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



