

Este artículo aclara cómo DeepSeek-V3.2 y DeepSeek-V3.2-Speciale difieren en arquitectura, rendimiento, eficiencia de inferencia y requisitos de implementación. Al presentar especificaciones concretas, umbrales de VRAM cuantizados, implicaciones de benchmarks y vías de acceso, ofrece una guía de decisión enfocada para elegir la API de DeepSeek-V3.2 más adecuada para tareas de codificación del mundo real.
¡Atención! Novita AI está lanzando su campaña “Build Month”, ofreciendo a los desarrolladores un incentivo exclusivo de hasta un 20% de descuento en todos los productos principales.
DeepSeek V3.2 para desarrolladores
Una guía técnica compacta que ayuda a los desarrolladores a evaluar si DeepSeek-V3.2 es la API adecuada para cargas de trabajo de codificación reales.
Resumen de arquitectura de DeepSeek V3.2
| Componente | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | Notas |
|---|---|---|---|
| Parámetros totales | 671B MoE | 671B MoE | Tamaño del modelo completo sin cambios |
| Parámetros activos por token | 37B | 37B | |
| Ventana de contexto | 128K tokens | 128K tokens | Suficientemente larga para bases de código completas |
| Atención | DeepSeek Sparse Attention (DSA) | DSA (ajuste mejorado) | Gran aceleración para secuencias largas |
| Precisión | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | Se recomienda Int8/Int4 para implementación |
Mejoras relevantes para codificación en DeepSeek V3.2
- DeepSeek Sparse Attention (DSA)
Reduce la complejidad de atención en secuencias de código largas; mejora la eficiencia de VRAM. - Estabilidad de contexto largo (>100K tokens)
Mantiene la consistencia de referencia—importante para navegación de archivos múltiples, trazado de dependencias y refactorización. - Entrenamiento híbrido CoT + Uso de herramientas
V3.2 está ajustado explícitamente para patrones de “piensa luego actúa”. - Variante Speciale
Optimización adicional para tareas de razonamiento algorítmico. Introducen DSA, un mecanismo de atención eficiente que reduce sustancialmente la complejidad computacional mientras preserva el rendimiento del modelo, específicamente optimizado para escenarios de contexto largo.
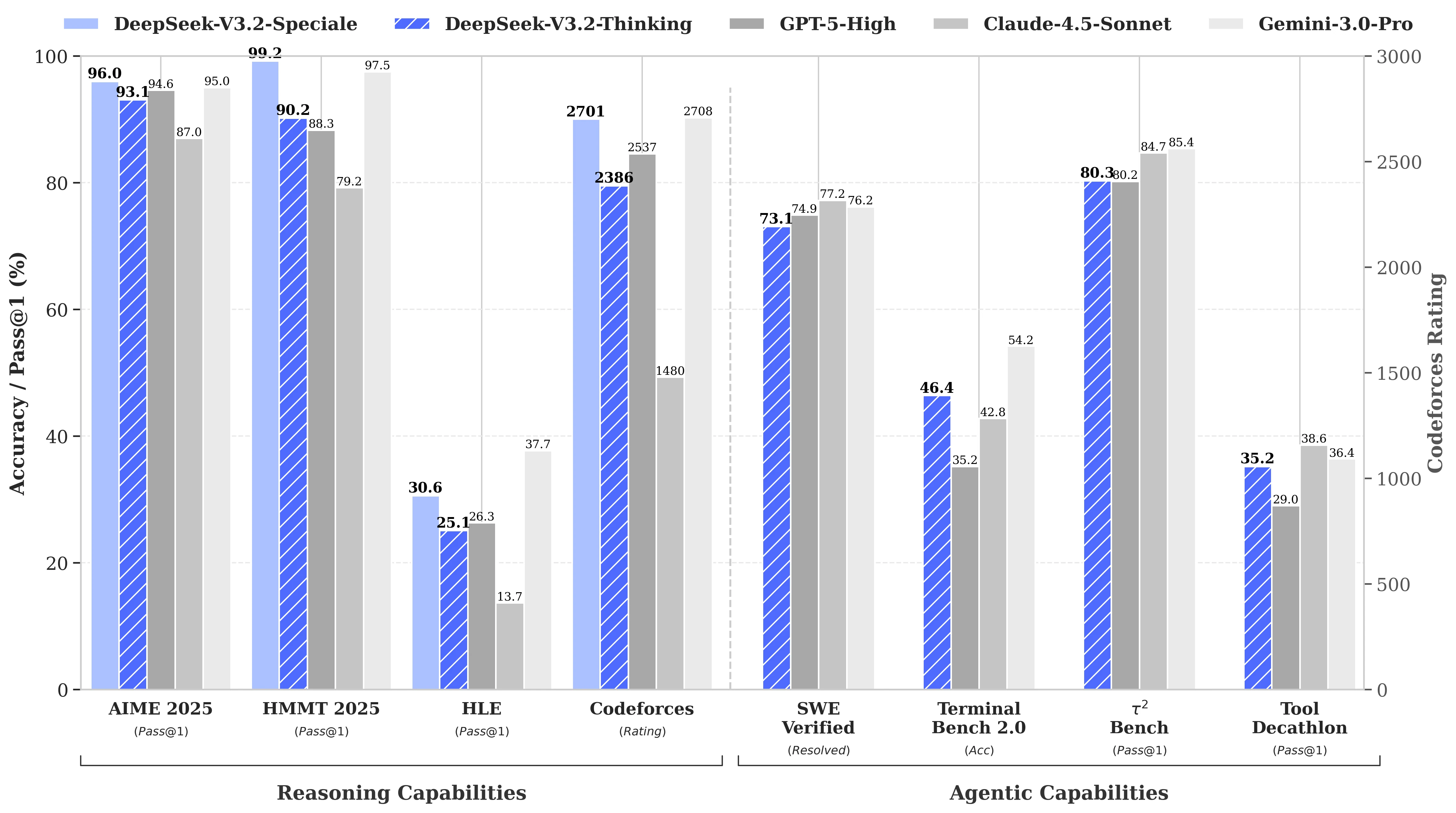
Rendimiento en benchmarks de DeepSeek V3.2
DeepSeek-V3.2 rinde de manera comparable a GPT-5. Notablemente, nuestra variante de alta computación, DeepSeek-V3.2-Speciale, supera a GPT-5 y muestra un nivel de razonamiento a la par de Gemini-3.0-Pro.
De Hugging Face
¡Prueba DeepSeek V3.2 con 20% de descuento!
Requisitos de hardware de DeepSeek V3.2
Consejos prácticos de velocidad
- La cuantización Int8 o Int4 ofrece el mejor equilibrio entre latencia y VRAM
- Usa backends vLLM o TensorRT-LLM para máximo rendimiento
- Evita implementaciones solo FP16 a menos que tengas >1 TB de VRAM
| Precisión | GPUs necesarias | VRAM total | Notas de implementación |
|---|---|---|---|
| FP16 (completo) | 8–16× H100/A100 80GB | 1.3–1.4 TB | Solo clústeres empresariales |
| FP8 | 6–8× H100/A100 | 800–900 GB | Entorno de alto rendimiento |
| Int8 | 4–8× GPUs 80GB | 670 GB | Recomendado para implementación estándar en servidor |
| Int4 | 2–4× GPUs 80GB | 330 GB | Opción más realista para laboratorios/empresas |
| Solo CPU | No factible | N/A | No lo intentes |
Interpretación del desarrollador
- Para inferencia local personalizada → Int4 o Int8
- Para tareas de codificación de máxima precisión → Clústeres multi-GPU FP8
- Para pipelines empresariales → Puedes elegir Novita AI
Novita ofrece el precio más bajo bajo demanda para H100 a $1.80/hr, hasta un 30% más barato que otros proveedores con el mismo rendimiento de GPU.
| Tipo de GPU | Especificación | Modelo de precios | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | Bajo demanda | $1.45/hr | $11.60/hr |
| Spot | $0.73/hr | $5.84/hr | ||
| A100 SXM 80GB | 80 GB VRAM | Bajo demanda | $1.60/hr | $12.80/hr |
| Spot | $0.80/hr | $6.40/hr |
El modo Spot de Novita AI es una opción de alquiler de GPU optimizada en costo que aprovecha la capacidad de GPU no utilizada o inactiva de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para uso continuo garantizado, las instancias Spot son interrumpibles—ofrecidas a precios significativamente más bajos, típicamente 40–60% más baratas.
Este modelo de precios funciona porque Novita reasigna dinámicamente GPUs inactivas a usuarios a corto plazo en lugar de dejarlas sin usar. Al hacerlo, la plataforma mejora la eficiencia general de utilización de la infraestructura, mientras que los desarrolladores se benefician de costos computacionales mucho más bajos para cargas de trabajo flexibles.
¿Cómo acceder a DeepSeek V3.2?
Novita AI ofrece APIs de DeepSeek V3.2 Exp con una ventana de contexto de 163K a $0.216 por entrada y $0.318 por salida, soportando salidas estructuradas y llamadas a funciones.
¡Atención! Novita AI está lanzando su campaña “Build Month”, ofreciendo a los desarrolladores un incentivo exclusivo de hasta un 20% de descuento en todos los productos principales.
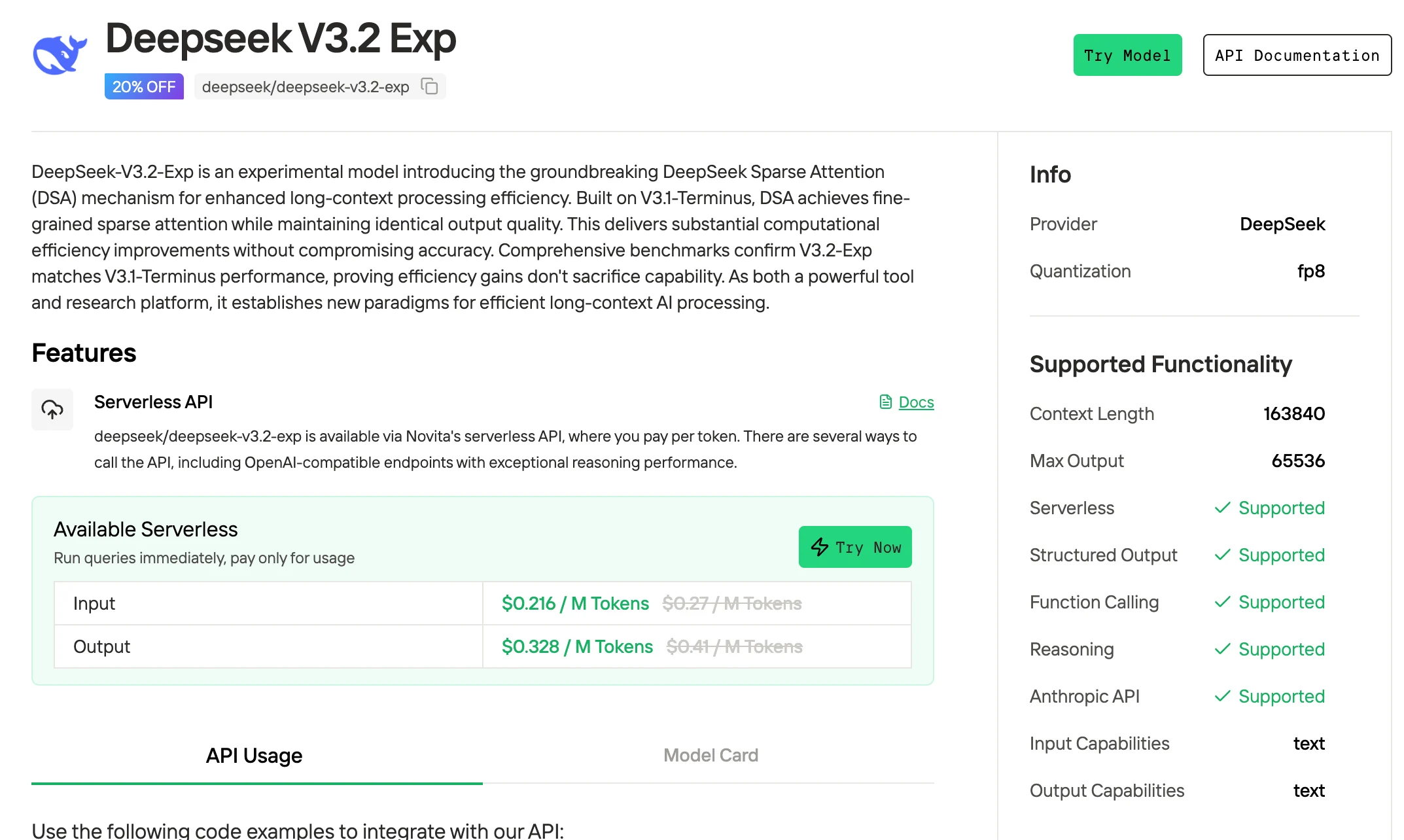
1. Acceder a DeepSeek V3.2 en interfaz web (más fácil para principiantes)
¡Prueba DeepSeek V3.2 con 20% de descuento!
2. Acceder a DeepSeek V3.2 mediante API (para desarrolladores)
Paso 1: Inicia sesión y accede a la Biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
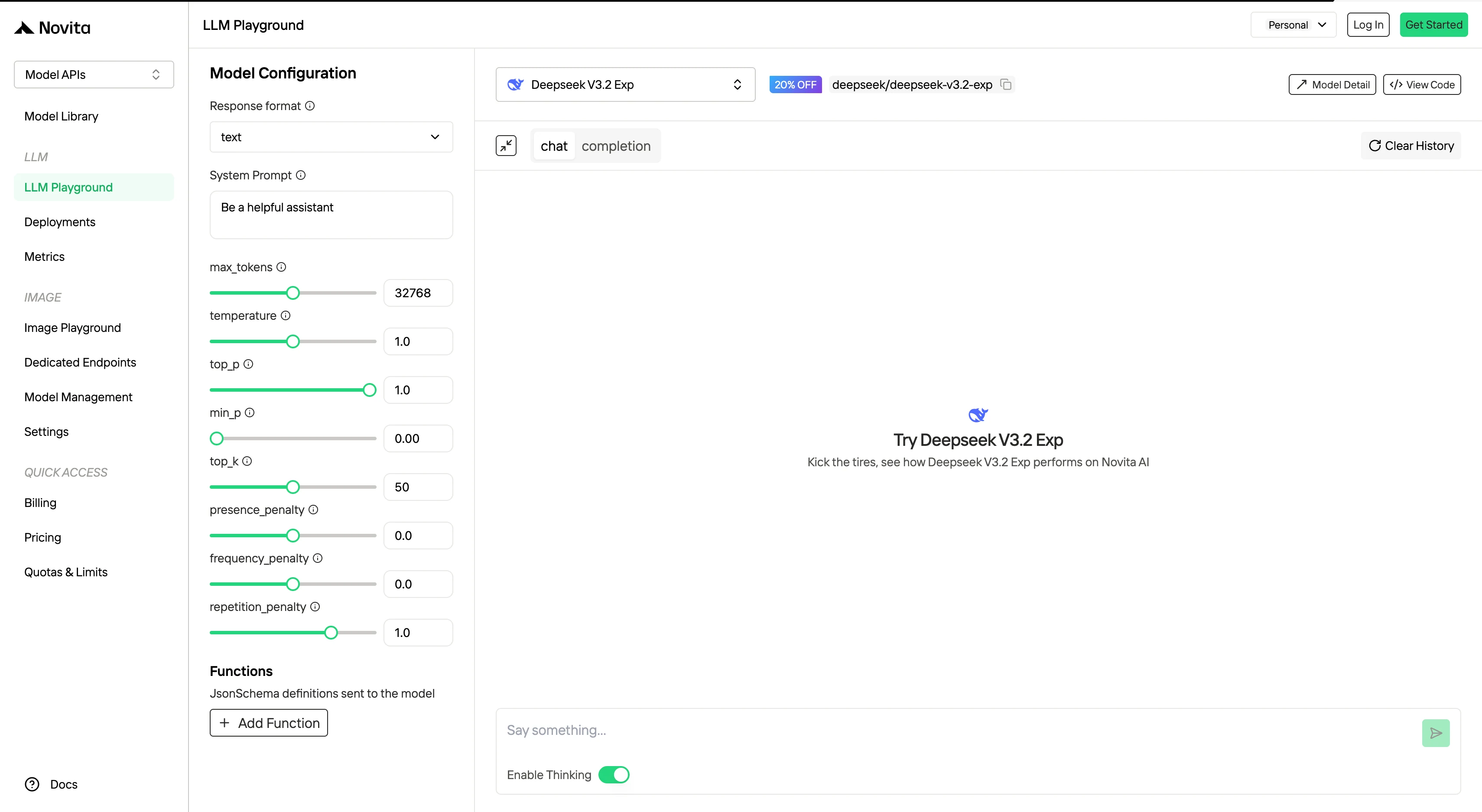
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se muestra en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
3. Acceder a DeepSeek V3.2 mediante implementación local (usuarios avanzados)
| Precisión | GPUs necesarias |
|---|---|
| FP16 (completo) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× GPUs 80GB |
| Int4 | 2–4× GPUs 80GB |
| Solo CPU | No factible |
Pasos de instalación:
- Descarga los pesos del modelo desde HuggingFace o ModelScope
- Elige el framework de inferencia: soporte para vLLM o SGLang
- Sigue la guía de implementación en el repositorio oficial de GitHub
4. Acceder a DeepSeek V3.2 mediante integración de código como Claude Code
Usando CLI como Trae, Claude Code, Qwen Code
Si deseas usar los mejores modelos de Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para asistencia de codificación con IA en tu entorno local o IDE, el proceso es simple: obtén tu clave API, instala la herramienta, configura las variables de entorno y comienza a codificar.
Para instrucciones detalladas de configuración y ejemplos, consulta los tutoriales oficiales:
- Trae : Guía paso a paso para acceder a modelos de IA en tu IDE
- Claude Code: Cómo usar Kimi-K2 en Claude Code en Windows, Mac y Linux
- Qwen Code: Cómo usar la API compatible con OpenAI en Qwen Code (¡configuración en 60 segundos!)
Flujos de trabajo multi-agente con OpenAI Agents SDK
Construye sistemas multi-agente avanzados integrando Novita AI con OpenAI Agents SDK:
- Plug-and-play: Usa los LLMs de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta traspasos, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración en Python: Simplemente establece el endpoint del SDK a
https://api.novita.ai/v3/openaiy usa tu clave API.
Conectar API en plataformas de terceros
API compatible con OpenAI: Disfruta de una migración e integración sin complicaciones con herramientas como Cline y Cursor, diseñadas para el estándar de la API de OpenAI.
Hugging Face: Usa modelos en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM,LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
Si tu carga de trabajo de codificación implica lógica compleja, contexto largo, análisis de múltiples archivos o comportamiento de agente, DeepSeek-V3.2 (o Speciale) es una de las opciones de código abierto más potentes y rentables disponibles. Si tus necesidades son ligeras (scripts cortos, depuración simple), un modelo más pequeño es más apropiado.
Preguntas frecuentes
¿Qué diferencia a DeepSeek-V3.2 de DeepSeek-V3.2-Speciale?
DeepSeek-V3.2 está optimizado para codificación general, razonamiento de contexto largo y flujos de trabajo con uso de herramientas, mientras que DeepSeek-V3.2-Speciale incluye razonamiento algorítmico mejorado, adecuado para depuración avanzada, lógica compleja y tareas a nivel de competencia.
¿Cuánta VRAM necesito para ejecutar DeepSeek-V3.2 localmente?
DeepSeek-V3.2 requiere ~1.3–1.4 TB de VRAM para FP16, ~800–900 GB para FP8, ~670 GB para Int8 y ~330 GB para Int4. DeepSeek-V3.2 no puede ejecutarse en configuraciones solo CPU.
¿Es DeepSeek-V3.2 adecuado para bases de código largas y análisis de múltiples archivos?
Sí. DeepSeek-V3.2 proporciona una ventana de contexto de 128K tokens y DeepSeek Sparse Attention, que mantienen la estabilidad y consistencia de referencia en repositorios grandes.
Novita AI es una plataforma cloud de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, además de proporcionar una GPU cloud asequible y confiable para construir y escalar.



