

Este artigo esclarece as diferenças entre o DeepSeek-V3.2 e o DeepSeek-V3.2-Speciale em arquitetura, desempenho, eficiência de inferência e requisitos de implantação. Ao apresentar especificações concretas, limites de VRAM quantizada, implicações de benchmarks e caminhos de acesso, ele fornece um guia de decisão focado para escolher a API DeepSeek-V3.2 mais adequada para tarefas de codificação do mundo real.
Atenção, por favor! A Novita AI está lançando sua campanha “Mês da Construção”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
Entre no seu Mês da Construção!
DeepSeek V3.2 para Desenvolvedores
Um guia técnico compacto ajudando desenvolvedores a avaliar se o DeepSeek-V3.2 é a API certa para cargas de trabalho de codificação do mundo real.
Visão Geral da Arquitetura do DeepSeek V3.2
| Componente | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | Observações |
|---|---|---|---|
| Total de Parâmetros | 671B MoE | 671B MoE | Tamanho total do modelo inalterado |
| Parâmetros Ativos por Token | 37B | 37B | |
| Janela de Contexto | 128K tokens | 128K tokens | Suficiente para bases de código inteiras |
| Atenção | Atenção Esparsa DeepSeek (DSA) | DSA (ajuste aprimorado) | Aceleração principal para sequências longas |
| Precisão | FP16 / FP8 / Int8 / Int4 | FP16 / FP8 | Int8/Int4 recomendados para implantação |
Aprimoramentos Relevantes para Codificação do DeepSeek V3.2
- Atenção Esparsa DeepSeek (DSA)
Reduz a complexidade de atenção em sequências de código longas; melhora a eficiência de VRAM. - Estabilidade de Longo Contexto (>100K tokens)
Mantém a consistência de referência—importante para navegação em código multi-arquivo, rastreamento de dependências e refatoração. - Treinamento Híbrido de CoT + Uso de Ferramentas
O V3.2 é ajustado explicitamente para padrões de “pensar-depois-agir”. - Variante Speciale
Otimização extra para tarefas de raciocínio algorítmico. Eles introduzem o DSA, um mecanismo de atenção eficiente que reduz substancialmente a complexidade computacional enquanto preserva o desempenho do modelo, otimizado especificamente para cenários de longo contexto.
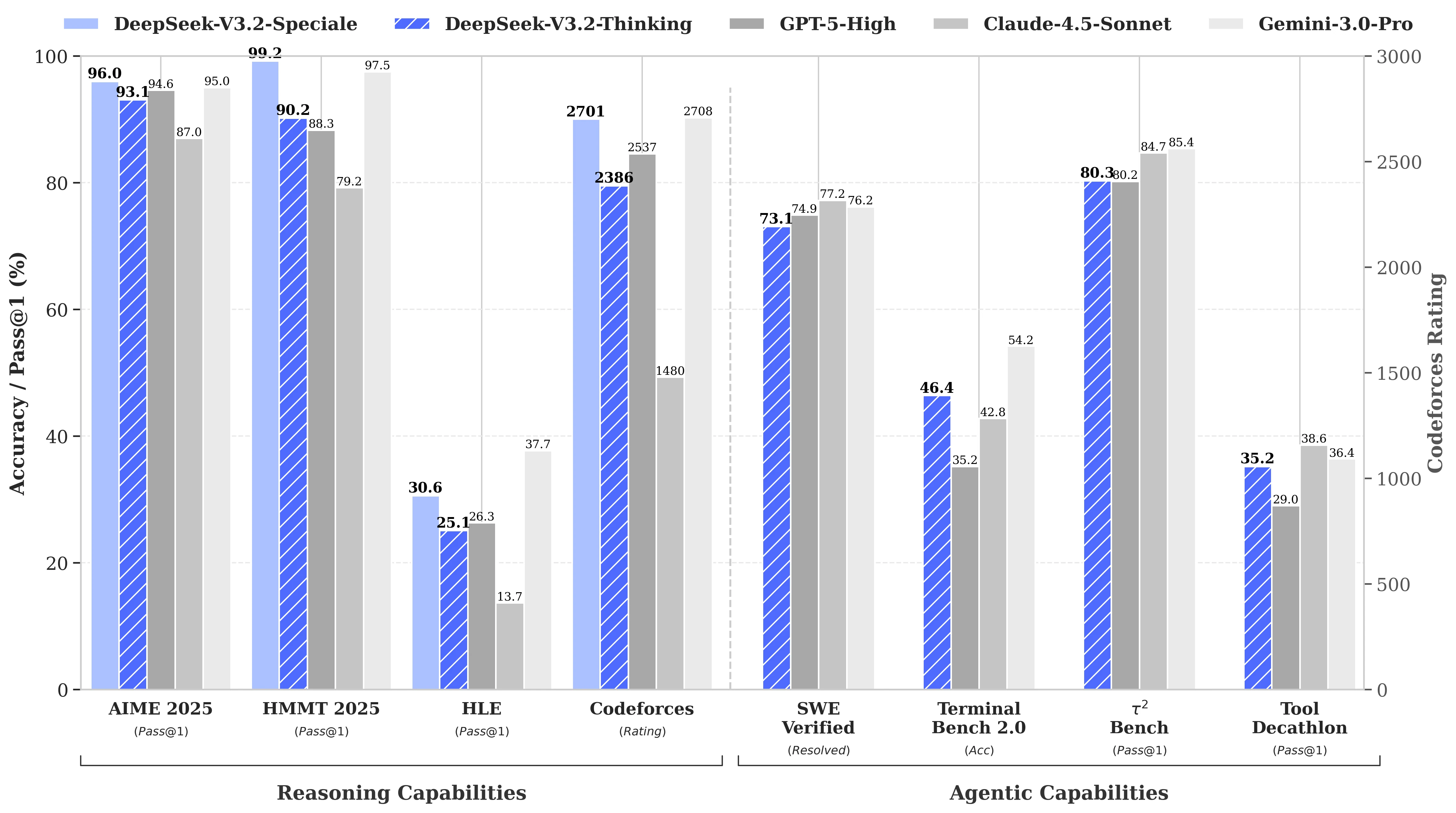
Desempenho em Benchmarks do DeepSeek V3.2
O DeepSeek-V3.2 tem desempenho comparável ao GPT-5. Notavelmente, nossa variante de alto poder computacional, DeepSeek-V3.2-Speciale, supera o GPT-5 e apresenta proficiência em raciocínio equivalente ao Gemini-3.0-Pro.
Do Hugging Face
Experimente o DeepSeek V3.2 com 20% de desconto!
Requisitos de Hardware do DeepSeek V3.2
Dicas Práticas de Velocidade
- A quantização Int8 ou Int4 oferece o melhor equilíbrio entre latência e VRAM
- Use backends vLLM ou TensorRT-LLM para máximo throughput
- Evite implantações apenas FP16 a menos que você tenha mais de 1TB de VRAM
| Precisão | GPUs Necessárias | VRAM Total | Observações de Implantação |
|---|---|---|---|
| FP16 (completo) | 8–16× H100/A100 80GB | 1,3–1,4 TB | Apenas clusters empresariais |
| FP8 | 6–8× H100/A100 | 800–900 GB | Configuração de alto throughput |
| Int8 | 4–8× GPUs de 80GB | 670 GB | Recomendado para implantação em servidor padrão |
| Int4 | 2–4× GPUs de 80GB | 330 GB | Opção mais realista para laboratórios/empresas |
| Apenas CPU | Não viável | N/A | Não tente |
Interpretação para Desenvolvedores
- Para inferência local personalizada → Int4 ou Int8
- Para tarefas de codificação de maior precisão → Clusters multi-GPU FP8
- Para pipelines empresariais → Você pode escolher a Novita AI
A Novita oferece o menor preço sob demanda de H100 a US$ 1,80/hora, até 30% mais barata que outros provedores com desempenho de GPU idêntico.
| Tipo de GPU | Especificação | Modelo de Preço | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB de VRAM | Sob Demanda | US$ 1,45/hora | US$ 11,60/hora |
| Spot | US$ 0,73/hora | US$ 5,84/hora | ||
| A100 SXM 80GB | 80 GB de VRAM | Sob Demanda | US$ 1,60/hora | US$ 12,80/hora |
| Spot | US$ 0,80/hora | US$ 6,40/hora |
O modo Spot da Novita AI é uma opção de aluguel de GPU otimizada para custos que aproveita a capacidade de GPU não utilizada ou ociosa da plataforma. Ao contrário de instâncias sob demanda, que reservam hardware dedicado para uso contínuo garantido, as instâncias Spot são interrompíveis—oferecidas a preços significativamente mais baixos, tipicamente 40–60% mais baratas.
Esse modelo de preços funciona porque a Novita realoca dinamicamente GPUs ociosas para usuários de curto prazo, em vez de deixá-las sem uso. Ao fazer isso, a plataforma melhora a eficiência geral de utilização da infraestrutura, enquanto os desenvolvedores se beneficiam de custos computacionais muito menores para cargas de trabalho flexíveis.
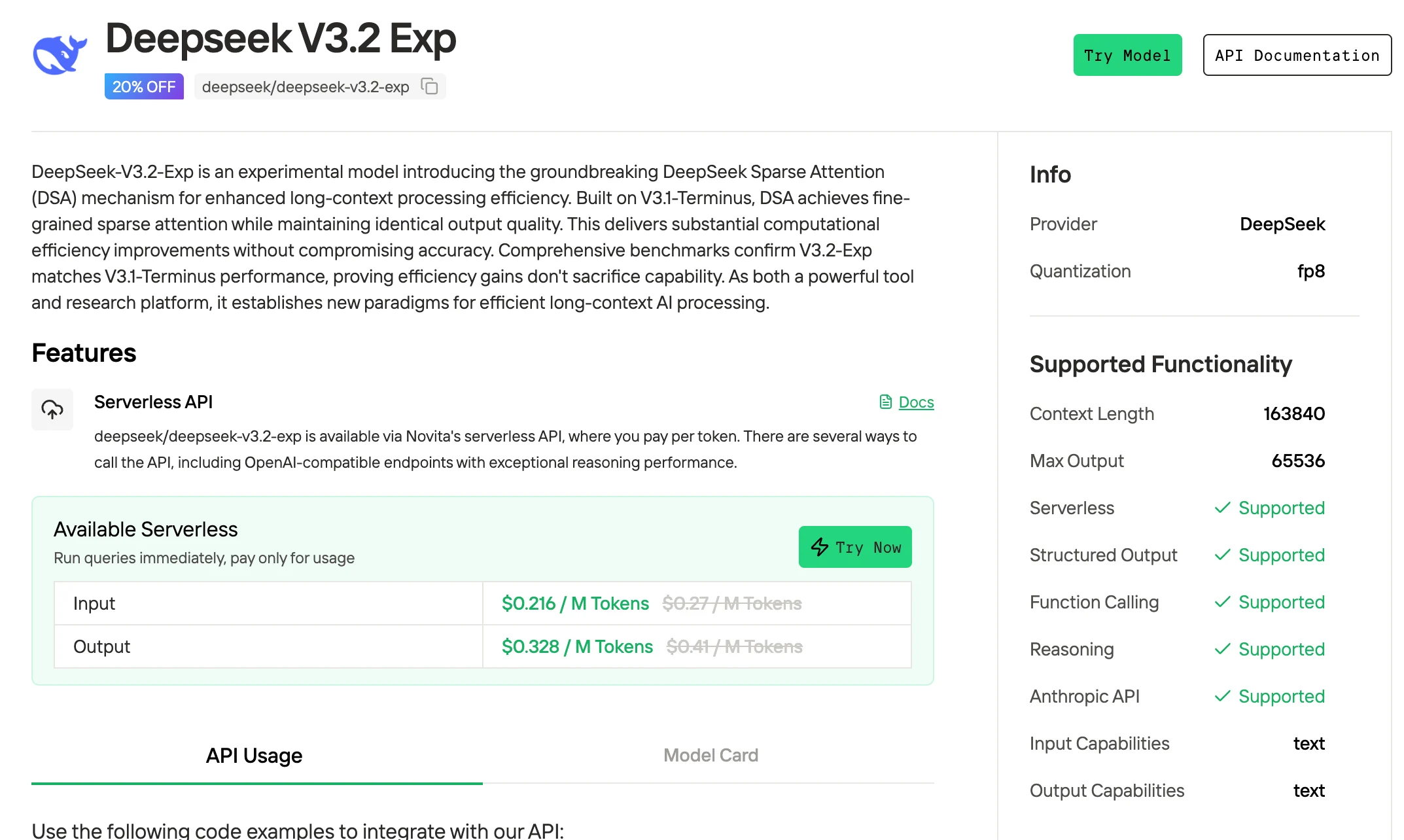
Como Acessar o DeepSeek V3.2?
A Novita AI oferece APIs do DeepSeek V3.2 Exp com uma janela de contexto de 163K a US$ 0,216 por entrada e US$ 0,318 por saída, suportando saídas estruturadas e chamadas de função.
Atenção, por favor! A Novita AI está lançando sua campanha “Mês da Construção”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
1. Acesse o DeepSeek V3.2 na Interface Web (Mais fácil para iniciantes)
Experimente o DeepSeek V3.2 com 20% de desconto!
**2. Acesse o DeepSeek V3.2 via API (Para Desenvolvedores)
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
**3. Acesse o DeepSeek V3.2 em Implantação Local (Usuários Avançados)
| Precisão | GPUs Necessárias |
|---|---|
| FP16 (completo) | 8–16× H100/A100 80GB |
| FP8 | 6–8× H100/A100 |
| Int8 | 4–8× GPUs de 80GB |
| Int4 | 2–4× GPUs de 80GB |
| Apenas CPU | Não viável |
Passos de Instalação:
- Baixe os pesos do modelo do HuggingFace ou ModelScope
- Escolha o framework de inferência: vLLM ou SGLang são suportados
- Siga o guia de implantação no repositório oficial do GitHub
**4. Acesse o DeepSeek V3.2 via Integração de Código Como o Claude Code
Usando CLI como Trae, Claude Code, Qwen Code
Se você quiser usar os principais modelos da Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para assistência de codificação com IA no seu ambiente local ou IDE, o processo é simples: obtenha sua Chave de API, instale a ferramenta, configure as variáveis de ambiente e comece a codificar.
Para comandos de configuração detalhados e exemplos, confira os tutoriais oficiais:
- Trae : Guia Passo a Passo para Acessar Modelos de IA no Seu IDE
- Claude Code:Como Usar o Kimi-K2 no Claude Code no Windows, Mac e Linux
- Qwen Code:Como Usar a API Compatível com OpenAI no Qwen Code (Configuração em 60s!)
Fluxos de Trabalho Multi-Agente com o SDK de Agentes OpenAI
Construa sistemas multi-agente avançados integrando a Novita AI com o SDK de Agentes OpenAI:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho de Agentes OpenAI.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que possam delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Basta definir o endpoint do SDK como
https://api.novita.ai/v3/openaie usar sua chave de API.
Conecte a API em Plataformas de Terceiros
API Compatível com OpenAI: Aproveite a migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API OpenAI.
Hugging Face: Use modelos em Spaces, pipelines ou com a biblioteca Transformers via endpoints da Novita AI.
Frameworks de Agente e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
Se sua carga de trabalho de codificação envolve lógica complexa, contexto longo, análise multi-arquivo ou comportamento de agente, o DeepSeek-V3.2 (ou Speciale) é uma das opções de código aberto mais fortes e econômicas disponíveis. Se suas necessidades são leves (scripts curtos, depuração simples), um modelo menor é mais adequado.
Perguntas Frequentes
O que diferencia o DeepSeek-V3.2 do DeepSeek-V3.2-Speciale?
O DeepSeek-V3.2 é otimizado para codificação geral, raciocínio de longo contexto e fluxos de trabalho de uso de ferramentas, enquanto o DeepSeek-V3.2-Speciale inclui raciocínio algorítmico aprimorado, adequado para depuração avançada, lógica complexa e tarefas de nível de concurso.
Quanta VRAM preciso para executar o DeepSeek-V3.2 localmente?
O DeepSeek-V3.2 requer ~1,3–1,4 TB de VRAM para FP16, ~800–900 GB para FP8, ~670 GB para Int8 e ~330 GB para Int4. O DeepSeek-V3.2 não pode ser executado em configurações apenas com CPU.
O DeepSeek-V3.2 é adequado para bases de código longas e análise multi-arquivo?
Sim. O DeepSeek-V3.2 fornece uma janela de contexto de 128K tokens e a Atenção Esparsa DeepSeek, que mantêm a estabilidade e a consistência de referência em repositórios grandes.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



