

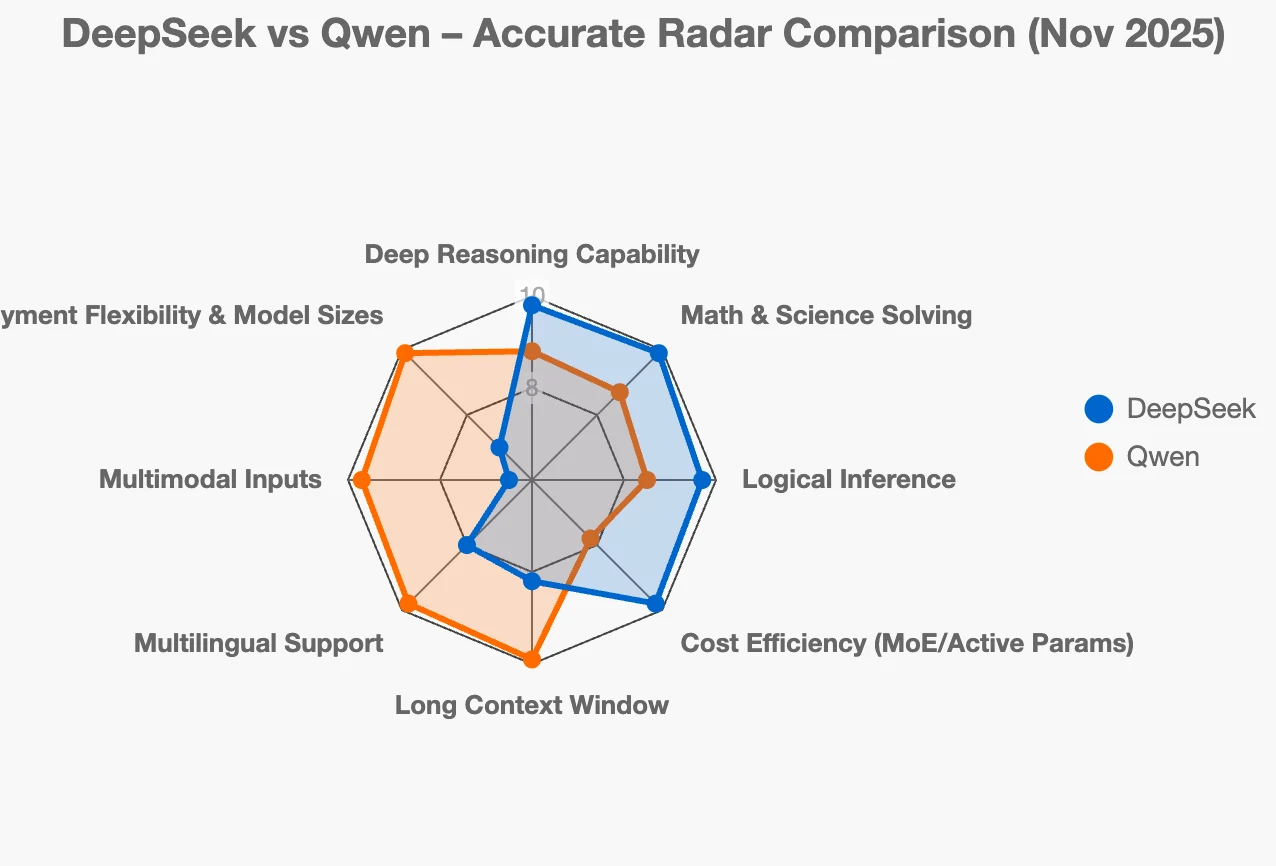
多數比較 DeepSeek 與 Qwen 的使用者都會感到困惑,因為這兩個生態系都實力堅強、開源且迭代快速,但它們的設計目標是解決完全不同的問題。DeepSeek 專注於深度推理、思路鏈穩定性、數學/程式碼準確性,以及基於 MoE(混合專家)的效率優化;而 Qwen 系列則專注於全棧部署,涵蓋從超大 MoE 模型到微型邊緣模型的所有場景,同時支援多模態、RAG(檢索增強生成)、嵌入、程式碼生成,以及企業級工具。
本文將透過檢視兩者的旗艦模型、蒸餾版本、高效能系列、RAG 模型以及硬體需求,釐清這些差異,幫助使用者理解每個生態系的實際目標,以及哪一個更符合自己的營運需求。
DeepSeek 與 Qwen 的實際目標究竟是什麼?
如果您正在思考哪個開源中文 LLM 生態系符合自身需求,目前市場上最大的兩個玩家分別是 DeepSeek 與 Qwen 系列。兩者實力都非常強勁,但解決的問題不同,發展方向也大相逕庭。
DeepSeek:「我們想要真正能深度思考的模型」
可以把 DeepSeek 視為「推理專家」。
他們最重視的事項:
- 打造真正擅長艱難逐步思考的模型——數學證明、科學問題、複雜程式碼、邏輯謎題都能勝任。
- 突破思路鏈(CoT)推理的極限,讓模型不僅聽起來聰明,更能正確解決問題,並展示推理過程。
- 運用混合專家(MoE)+ 強化學習等巧妙技術,讓模型無需為每個 token 啟動數十億參數就能發揮強大效能(這能降低推論成本並提升速度)。
- 發布最佳推理模型的輕量「蒸餾」版本,讓一般使用者與小型公司也能實際運行這些模型。
他們正在解決的實際問題:
- 大多數巨型模型擅長撰寫文章,但連基礎數學或邏輯題目都答錯。DeepSeek 正是要解決這個問題。
- 推理能力並非參數越多越好——他們試圖用更少的主動參數發揮更強的推理能力(提升 GPU 的性價比)。
- 高端推理模型通常只有大型實驗室負擔得起運行成本。DeepSeek 希望讓這項能力普及化。
- 當您需要模型解釋得出答案的過程(如法律、醫療、教育等場景),您需要透明的思路鏈——DeepSeek 在這方面表現非常出色。
最適合場景:研究、教育、程式碼助手、數學/科學工具,任何「得出正確答案 + 展示推理過程」比作為通用聊天機器人更重要的情境。
Qwen:「我們要為真實企業打造完整的工具箱」
Qwen 更像是 LLM 界的「瑞士軍刀」。
他們最重視的事項:
- 提供您可能需要的所有尺寸與類型:手機用微型模型、伺服器用中型模型、追求極致效能的大型模型,還有密集/MoE 版本、視覺模型、程式碼模型、嵌入模型、重排序模型……應有盡有。
- 強大的多語言效能(尤其支援中文 + 100 種以上其他語言)。
- 極長的上下文視窗(部分版本可達 128k 甚至 100 萬 token)。
- 企業級部署就緒:簡單易用的 API、本地部署選項、邊緣裝置支援,以及企業級安全與工具鏈。
他們正在解決的實際問題:
- 企業需要的不仅是聊天機器人——還需要文件理解、搜尋、檢索增強生成(RAG)、圖文應用、多語言客戶支援等。Qwen 提供完整的全棧解決方案。
- 舊款模型處理長文件時容易出錯,切換語言時也常出現問題。Qwen 能從容處理這兩種場景。
- 您通常需要微型模型用於行動/邊緣場景,大型模型用於重型分析——Qwen 提供完整的尺寸梯隊,讓您永遠不會陷入無模型可用的困境。
- 搭建正規的企業搜尋或知識庫系統需要優質的嵌入 + 重排序模型。Qwen 的嵌入與重排序模型是開源界最頂尖的選擇之一。
最適合場景:企業搜尋引擎、多語言客服機器人、文件密集型工作流、RAG 流程、結合視覺+文字的應用,或任何可靠性與易部署性優先的生產環境系統。
那麼該如何選擇?
- 如果您的項目成敗取決於邏輯推理、數學或程式碼準確性 → 選擇 DeepSeek(尤其是 DeepSeek-R1 或最新的 DeepSeek-V3 推理模型)。
- 如果您正在打造包含搜尋、長文件、多語言、圖像功能的真實產品,或需要 0.5B 到 72B 參數的模型 → 選擇 Qwen。
DeepSeek 模型生態系
DeepSeek 模型主要專注於透過大規模混合專家(MoE)架構與密集強化學習(RL)流程,最大化推理能力,打造出精準高效能的 671B–685B 參數模型,以及專為輕量場景設計的蒸餾版本(Distill 模型)。
DeepSeek 旗艦模型
以下為各 DeepSeek 模型版本的詳細架構摘要:
| 版本 | 總參數 / 啟動參數 | 上下文視窗 | 核心架構與優化點 |
|---|---|---|---|
| DeepSeek V3 | 總計 671B,每 token 啟動 37B | 128K token | 混合專家(MoE)架構;採用多頭潛在注意力(MLA)降低 KV 快取大小;使用多 token 預測(MTP)目標;採用無輔助損失負載均衡。 |
| DeepSeek R1 | 總計 671B,每 token 啟動 37B |
128K token | 基礎架構與 V3 相同(MoE + MLA),但搭載密集 RL 流程(SFT → RL → SFT → RL)以強化推理/邏輯能力。 |
| DeepSeek V3.1 | 總計 671B,每 token 啟動 37B |
128K token | 混合推論模式:支援「思考」(思路鏈)與「非思考」模式;結合 V3 的通用能力與 R1 的推理優勢;擴展長上下文訓練。 |
| DeepSeek R1 0528 | 總計 685B 參數(啟動參數子集未標註) | 64K token | 更新的 R1 版本,參數量更高,上下文視窗縮短至約 64K 以提升推論速度/穩定性(而非完整的 128K)。(資料來源:版本列表) |
| DeepSeek V3 0324 | 總計 671B,每 token 啟動 37B | 128K token | 架構與 V3 相同,但針對多語言處理(尤其是中文)優化,增強了函數呼叫(Function Calling)能力,優化了前端/網頁開發場景。 |
DeepSeek 蒸餾模型
將 DeepSeek 的推理能力(邏輯、數學、逐步思考、思路鏈穩定性)轉移到更小、更密集的模型中,這些模型成本更低、速度更快,且可在消費級 GPU 上運行。
| 蒸餾模型 | 基礎模型 | 強化能力 |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | 強大的思路鏈(CoT)能力,更穩定的邏輯表現,提升的多語言推理能力 |
| R1-0528 Qwen3 8B | Qwen3 8B | 高推理準確率(AIME 86%),高效的思路鏈,快速的推論速度 |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | 卓越的數學準確率(MATH-500 92.8%),結構化的逐步推理能力 |
| R1-Distill Llama 8B | Llama-8B | 更優質的指令遵循能力 + 緊湊的推理表現 |
| R1-Distill Llama 70B | Llama-70B | 強大的通用推理能力,穩定的長篇思路鏈,一致的輸出表現 |
Qwen 模型生態系
Qwen 系列(Qwen 2.5 與 Qwen 3)提供參數範圍從 0.6B 到 480B 的高度靈活模型陣容,強調多語言支援、廣泛的上下文處理能力,以及針對程式碼生成、嵌入、多模態任務的專業版本。
Qwen 旗艦模型
| 版本 | 總參數 / 啟動參數 | 上下文視窗 | 核心定位與特性 |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B(MoE) | 原生 256K,可擴展至約 100 萬 token | 代理式程式碼生成與多檔案儲存庫理解;優化函數呼叫/工具使用;僅支援非思考模式 |
| Qwen3-VL-235B-A22B | 235B / 22B(MoE) | 原生 256K(可擴展至約 100 萬) | 多模態視覺語言(圖像/影片)模型;擅長視覺轉程式碼、3D 推理、OCR;提供 Instruct/Thinking 版本 |
| Qwen3 32B | 32B / 密集 | 128K token | 通用推理 + 多語言支援;密集骨幹架構,部署成本更低 |
| Qwen2.5-72B Instruct | 72B(密集或 MoE 版本) | 128K token | 強大的多語言支援(29 種以上語言); |
Qwen 3 高效能模型
Qwen 3 系列推出了一套完整的輕量模型,全部支援高效的「混合思考模式」(思考 vs 非思考),以及廣泛的多語言支援(119 種語言)。
| 版本 | 總參數 | 上下文視窗 | 核心定位與特性 |
|---|---|---|---|
| Qwen3-14B | 14.8B | 原生 32,768 token,可擴展至 131,072 | 通用強效中型模型;支援「思考」與「非思考」模式;具備多語言與代理能力 |
| Qwen3-8B | 8.19B | 128K token | 輕量推理模型;數學與通用推理任務表現優異 |
| Qwen3-4B | 4.0B | 原生 32K token(可擴展) | 針對效率優化;低資源部署場景,仍能保持強勁效能 |
| Qwen3-1.7B | 1.7B | 32K token | 適用於邊緣場景/快速聊天機器人;佔用資源極少 |
| Qwen3-0.6B | 0.6B | 32K token | 超輕量模型,適用於高併發/裝置端部署 |
Qwen 3 RAG 模型
Qwen3 嵌入產品線體現了業界對檢索 + 嵌入 + 檢索增強工作流是現代 AI 應用(搜尋、問答、RAG、程式碼)核心的共識。
| 版本 | 總參數 / 啟動參數 | 上下文視窗 | 核心定位與特性 |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K token | 文字嵌入模型;多語言支援(100 種以上);長輸入支援;嵌入維度可配置至最高 4096;MTEB 基準測試表現優異(70.58) |
| Qwen3-Reranker 8B | 8B | 32K token | 交叉編碼器重排序模型;在 RAG 流程中按相關性對檢索到的文件排序;多語言檢索精度高 |
如何以低成本、高效率的方式使用 DeepSeek 與 Qwen?
1. 網頁介面(最適合新手)
2. API 存取(適合開發者)
步驟 1:登入並存取模型庫
登入您的帳號並點擊 模型庫 按鈕。

步驟 2:選擇模型
瀏覽可用選項並選擇符合需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得 API 金鑰
要進行 API 驗證,我們會提供給您新的 API 金鑰。進入「設定」頁面後,即可按照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用對應程式語言的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下為 Python 使用者呼叫聊天完成 API 的範例。
3. 本地部署(適合進階使用者)
| 模型 | 總 VRAM(FP16 推論) | 最低消費級配置 |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | 約 780–820 GB | 8 張 RTX 4090(24GB)僅在大量卸載的情況下勉強可行 |
| DeepSeek-R1-0528 685B | 約 800–850 GB | 8 張 H100 80GB(非常緊湊) |
| DeepSeek-V3-0324 671B | 約 780–820 GB | 8 張 RTX 4090(24GB)僅在大量卸載的情況下勉強可行 |
| 模型 | 量化方式 | 所需 VRAM | 可行的消費級配置 |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-bit(NF4/GPTQ/AWQ) | 170–190 GB | 8 張 RTX 4090 或 4 張 H100 80GB |
| DeepSeek-R1/V3 671B | INT8 | 340–380 GB | 6–8 張 RTX 4090 或 4 張 A100/H100 80GB |
| 模型 | VRAM(FP16) | 可運行的消費級 GPU |
|---|---|---|
| R1-Distill-Qwen-32B | 64 GB | 2 張 RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 GB | 1 張 RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 GB | 1 張 RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 GB | 4 張 RTX 4090 或 2 張 A100 80GB |
| 模型 | 總 VRAM(FP16/BF16) | 最低消費級配置 |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 GB(啟動 35B) | 8 張 H100 80GB |
| Qwen3-VL-235B MoE | 280–320 GB(啟動 22B) | 4 張 H100 80GB |
| Qwen2.5-72B / Qwen3-32B 密集 | 140–160 GB | 4 張 RTX 4090 或 2 張 A100 80GB |
| Qwen3-14B | 28–32 GB | 1 張 RTX 4090 |
| Qwen3-8B | 16–18 GB | 1 張 RTX 4080/4090 |
| Qwen3-4B | 8–10 GB | 1 張 RTX 4060 Ti / 4070 |
| Qwen3-1.7B 與 0.6B | 4 GB | 手機、RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 GB | 1 張 RTX 4090 |
安裝步驟:
- 從 HuggingFace 或 ModelScope 下載模型權重
- 選擇推論框架:支援 vLLM 或 SGLang
- 按照官方 GitHub 儲存庫的部署指南操作
4. 整合
使用 Trae、Claude Code、Qwen Code 等 CLI 工具
如果您想在本地環境或 IDE 中使用 Novita AI 的頂尖模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1)獲取 AI 程式碼輔助,流程非常簡單:取得 API 金鑰、安裝工具、配置環境變數,即可開始寫程式。
詳細的設置指令與範例請參考官方教學:
- Trae:在 IDE 中存取 AI 模型的逐步指南
- Claude Code:如何在 Windows、Mac 和 Linux 的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 相容 API(60 秒完成設置!)
使用 OpenAI Agents SDK 搭建多代理工作流
透過整合 Novita AI 與 OpenAI Agents SDK 搭建進階多代理系統:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支援交接、路由與工具使用: 設計能委派任務、分流處理或執行函式的代理,全部由 Novita AI 的模型驅動。
- Python 整合: 只需將 SDK 端點設定為
https://api.novita.ai/v3/openai,並使用您的 API 金鑰即可。
在第三方平台連接 API
OpenAI 相容 API: 無縫遷移與整合,支援符合 OpenAI API 標準的工具,例如 Cline 和 Cursor。
Hugging Face: 透過 Novita AI 端點,在 Spaces、pipeline 中使用模型,或搭配 Transformers 函式庫使用。
代理與編排框架: 透過官方連接器與逐步整合指南,輕鬆將 Novita AI 與合作夥伴平台連接,包括 Continue、AnythingLLM,LangChain、Dify 和 Langflow。
DeepSeek 以 DeepSeek-V3、DeepSeek-R1 和 DeepSeek-V3.1 等模型為核心,目標是最大化推理能力,並搭配 R1-Distill-Qwen-32B 和 R1-Distill-Qwen3-8B 等輕量蒸餾版本提供支援。Qwen 則以多功能性與企業級就緒為目標,提供 Qwen3-Coder-480B-A35B-Instruct、Qwen3-VL-235B-A22B 等模型,涵蓋從 Qwen3-14B 到 Qwen3-0.6B 的高效能模型,以及 Qwen3-Embedding-8B 和 Qwen3-Reranker-8B 等 RAG 導向模型。簡而言之:DeepSeek 優化深度推理效能;Qwen 優化完整、可部署、多語言、多模態的 AI 工具箱。
常見問題
DeepSeek-V3 與 Qwen 模型相比的核心優勢是什麼?
DeepSeek-V3 採用搭載 MLA 與 MTP 的 MoE 架構,最大化推理品質;而 Qwen 模型更側重多語言覆蓋、部署範圍與應用多功能性。
為什麼有人會選擇 DeepSeek-V3.1 而非 Qwen3-14B?
DeepSeek-V3.1 提供針對思路鏈深度優化的混合「思考/非思考」推理模式;而 Qwen3-14B 優先考慮通用推論、多語言任務與高效部署。
哪個模型生態系更適合長文件工作流?
Qwen 表現更優,其 Qwen3-Coder-480B-A35B-Instruct 和 Qwen3-VL-235B-A22B 等模型可提供最高 256K–100 萬 token 的上下文,而 DeepSeek 專注於推理能力,而非超長上下文文件處理。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 部署 AI 模型,同時也提供平價且可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。



