

MiniMax M3 已在 Novita AI 上以 minimax/minimax-m3 模型 ID 上线。这使得此次发布不仅仅是一份模型规格表:开发者可以通过 Novita 的 OpenAI 兼容 API 试用 M3,并观察它在大型代码库审查、工具密集型代理工作流、长上下文规划以及需要文本答案的多模态输入任务上的表现。
什么是 MiniMax M3?
MiniMax M3 是 MiniMax 推出的较新的 M 系列模型,专注于编码、代理推理、工具使用、长上下文工作以及多模态输入理解。在 Novita AI 上,它以无服务器聊天模型 minimax/minimax-m3 的形式提供。
测试它的理由很简单:M3 为你提供了很大的空间来承载项目上下文,并且它可以读取文本、图像和视频,同时返回文本。当任务包含不止一种证据(源文件、日志、截图、设计笔记或简短的产品演示)时,这种组合非常有用。
对用户而言,实际的边界很简单:使用 M3 理解混合输入并返回基于文本的分析、计划、解释或代码建议。它不是图像生成器或视频生成器。在将其输出投入生产之前,请使用你自己的验收标准进行测试。
M3 在 Novita AI 上线后有什么变化?
MiniMax M3 在 Novita AI 上以 minimax/minimax-m3 模型 ID 提供。你可以打开 MiniMax-M3 模型页面 查看实时列表,然后通过 Novita 的 OpenAI 兼容聊天补全端点调用它。
首次测试时,请使用下方的模型 ID、基础 URL、端点、支持的模态、上下文和输出限制,然后运行“如何使用”部分中的小型 Python 或 curl 请求。
如果你的技术栈已经使用 OpenAI SDK 模式,通常只需要更改基础 URL、API 密钥和模型字符串即可开始使用。在生产部署之前,请执行你为任何模型迁移所做的相同检查:延迟、令牌使用量、工具行为以及在你自己的工作负载上的成本。
Novita API 规格和模型 ID
| Novita 模型 ID | minimax/minimax-m3 |
| 模型显示名称 | MiniMax-M3 |
| 模型类型 | 聊天 |
| 上下文长度 | 1,000,000 个令牌 |
| 最大输出 | 131,072 个令牌 |
| 输入模态 | 文本、图像、视频 |
| 输出模态 | 文本 |
| 支持的功能 | 无服务器、函数调用、结构化输出、推理 |
| OpenAI 兼容基础 URL | https://api.novita.ai/openai |
| 聊天端点 | /v1/chat/completions |
请使用 Novita 模型页面获取当前 MiniMax-M3 的列表信息,并在需要请求字段、身份验证或参数详情时使用 API 参考。
如何在 Novita AI 上使用 MiniMax M3
当你希望通过 Novita 的 OpenAI 兼容 API 测试 MiniMax M3 时,请使用以下快速路径。
步骤 1:打开 Novita LLM API 文档
从 Novita 的 LLM API 指南 开始了解集成模式。将 创建聊天补全 API 参考 放在手边,以获取请求字段、响应格式和可选参数。
步骤 2:准备你的 API 密钥、基础 URL 和模型 ID
对于首次调用,你需要三个值:你的 Novita API 密钥、OpenAI 兼容基础 URL https://api.novita.ai/openai 以及模型 ID minimax/minimax-m3。将 API 密钥存储在环境变量或机密管理器中,而不是硬编码在应用程序代码中。
步骤 3:运行 Python 测试请求
以下是使用 OpenAI SDK 模式的最小 Python 示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="minimax/minimax-m3",
messages=[
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty.",
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks.",
},
],
max_tokens=1200,
temperature=0.2,
)
print(response.choices[0].message.content)
步骤 4:使用 curl 测试相同的请求
以下是使用 curl 的相同思路:
curl "https://api.novita.ai/openai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-d '{
"model": "minimax/minimax-m3",
"messages": [
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty."
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks."
}
],
"max_tokens": 1200,
"temperature": 0.2
}'
步骤 5:用真实的编码任务进行评估
在首次评估时,不要试图要求生成整个应用。相反,给 M3 一个小而现实的任务:五个相关文件、一个失败的测试,以及解释失败原因并建议最小安全修复的请求。这对于推理质量、代码定位以及长上下文是否有帮助都是更好的信号。
面向开发者的关键能力
阅读 M3 规格的有用方式不是将其视为大数字清单。每种能力都指向不同类型的工作负载:
- 百万令牌上下文:当任务需要超过一个提示和一个文件时很有用,例如仓库审查、冗长的问题历史、日志、规格或迁移计划。如果任务是一个简短的编码问题,且较小的模型已经表现良好,则不太有用。
- 函数调用和结构化输出:值得为需要调用工具、返回 JSON 格式结果或将工作传递给其他服务的代理进行测试。这些功能本身并不能使代理变得可靠;它们只是为你提供正确评估工具密集型工作流的机制。
- 文本、图像和视频输入:当工程工作中包含视觉证据时很有用:UI 截图、工作流录制、架构图或产品演示。由于输出是文本,最合适的用途是解释、调试、总结、分类和实施规划。
- 推理支持:当你要求 M3 比较选项、发现风险或解释为什么某个修复比其他方案更安全时,最有价值。对于简单的提取或路由任务,额外的推理预算可能不值得花费。
实用的测试是这些能力是否能减少你工作流程中的步骤。如果它们只是让提示看起来更令人印象深刻,请使用更小或更便宜的模型。如果它们能让模型保留相关的项目状态、检查视觉上下文并返回结构化决策,那么 M3 是更好的候选。
基准测试和评估说明
MiniMax 报告了 M3 在编码、终端、浏览器和代理基准测试中的强劲成绩。请将下面的基准图用作基于来源的起点,然后在 Novita AI 上针对你自己的提示、仓库、工具和成本目标将 M3 进行比较。
官方 MiniMax 基准图显示 M3 在 SWE Bench Pro 59.0、Terminal Bench 2.1 66.0、VIBE V2 50.1、SVG-Bench 63.7、KernelBench Hard 28.8、BrowseComp 83.5、GDPval-rubrics 74.7、BankerToolBench 76.1、MCP Atlas 74.2 和 OSWorld-verified 70.0 上的得分。这些是 MiniMax 报告的分数,因此请将其视为评估信号,而不是生产性能的保证。
对于代理式编码,在切换流量之前先构建一个小型评估集。跟踪解决任务率、工具调用准确性、重试行为、每个已解决任务的成本以及你自己仓库中的故障模式。
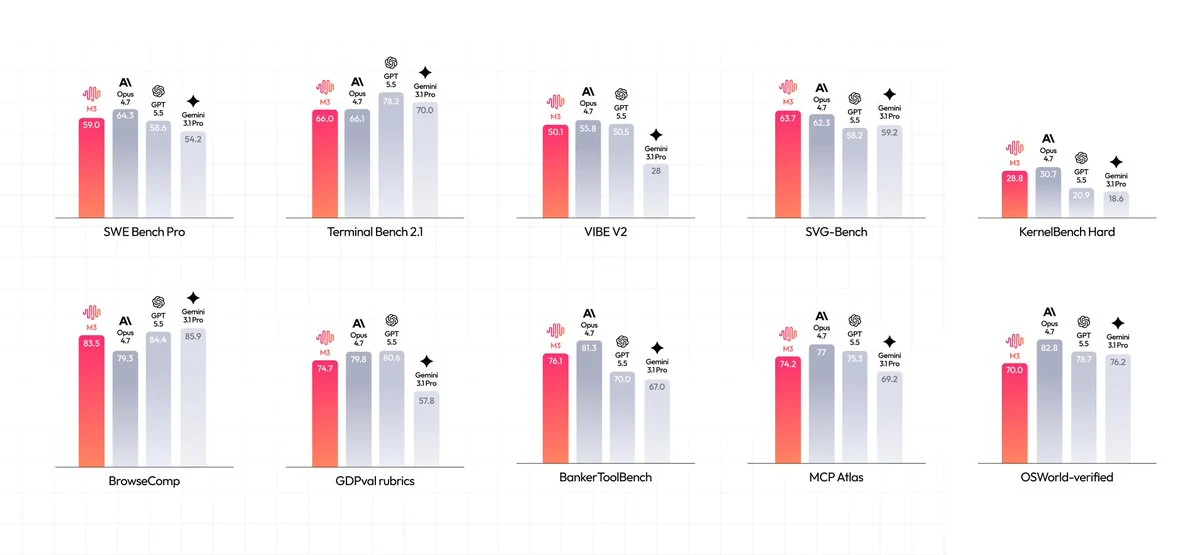
来源:MiniMax 官方基准图。分数由 MiniMax 报告,在生产使用前应在您自己的工作负载上进行验证。
定价说明和成本检查
2026 年 6 月 1 日检查的 Novita 实时模型列表 API 返回了 minimax/minimax-m3 的原始定价字段:输入 3000,输出 12000。解释为每百万令牌的美元价格,这些字段对应每百万输入令牌 $0.30 和每百万输出令牌 $1.20。在生产使用前请检查 Novita 模型页面和账户仪表板,因为显示的定价可能会变化。
对于 Novita AI 上的生产估算,请使用实时模型页面和账户仪表板作为真实来源,然后根据实际输入令牌、输出令牌、缓存读取行为和重试率进行计算。
避免诸如“Claude Sonnet 的 20%”之类的宽泛捷径。要进行有用的比较,请使用当前的 Novita 模型页面或账户仪表板费率,并根据你自己的令牌组合、输出长度、重试次数和延迟目标进行估算。
MiniMax M3 vs MiniMax M2.7、M2 和 M1
如果你已经阅读了 MiniMax M2.7 on Novita AI 文章,主要区别在于范围。M2.7 涵盖了具有 204,800 个令牌上下文窗口的先前代理式编码模型。M3 将上限提高到 1,000,000 个令牌上下文窗口,增加了多模态输入,并在编码和代理基准测试中带来了更广泛的 MiniMax 报告覆盖范围。
与 M2.7 和 M2.5 相比,当你需要测试更大的项目状态、工具密集型工作流或多模态推理时,请选择 M3。与 MiniMax M1 on Novita AI 相比,M3 更少是关于将长上下文作为头条新闻,而更多是关于将该上下文应用于编码、浏览、终端和代理任务。
MiniMax M3 的适用场景
一个实用的测试是大规模代码库审查。给 M3 一个功能简介、相关的源文件、日志、失败的测试输出以及先前的实现说明。然后要求它识别最小的安全更改,或者在任何人开始编辑代码之前需要解决的主要风险。
它同样适合测试代理式编码助手:搜索文件、规划更改、调用工具并返回结构化结果。Novita 的函数调用和结构化输出支持有助于此,但真正的测试是当工具失败、上下文嘈杂或正确的做法是停下来请求澄清时,M3 的行为方式。
对于产品和工程团队,多模态角度也值得测试。M3 可以读取 UI 截图、检查工作流录制、从架构图中提取实现任务,或将视觉质量反馈转化为更清晰的工单。
何时 MiniMax M3 可能不是正确的选择
对于开发者工作流,当长上下文、工具使用或多模态输入可以减少审查时间时,请选择 M3。当工作是简单的提取、短问答或路由时,请使用较小的模型。在生产中,对于错误成本高昂的任务,请保留验收测试和人工审查。
如果你的团队需要在采用模型之前获得独立的基准证据,请针对代表性的仓库、提示、工具循环、延迟目标和预算限制在 Novita AI 上运行评估。这将为你提供比仅比较发布页面数字更清晰的答案。
常见问题
MiniMax M3 在 Novita AI 上上线了吗?
是的。实时 Novita 模型页面列出了 MiniMax-M3,OpenAI 兼容模型端点将 minimax/minimax-m3 作为活跃聊天模型返回。
我应该使用什么模型 ID?
使用 minimax/minimax-m3 配合 Novita 的 OpenAI 兼容 LLM API。
在 Novita 上 MiniMax M3 支持多少上下文长度?
Novita 列出 MiniMax-M3 的上下文长度为 1,000,000 个令牌,最大输出令牌为 131,072。
MiniMax M3 能生成图像或视频吗?
在此草案中,没有任何经过验证的 Novita 声明支持图像或视频输出生成。经过验证的模态集是文本、图像和视频输入,文本输出。
如何评估用于编码代理的 MiniMax M3?
在真实任务上测试它:仓库搜索、失败的测试、冗长的问题历史、工具调用、结构化输出和嘈杂的上下文。跟踪解决任务率、工具调用质量、成本、延迟和故障恢复,而不是仅依赖已发布的基准数字。



