

MiniMax M3 已作為 minimax/minimax-m3 在 Novita AI 上線。這使得這次推出不僅僅是另一張模型規格表:開發者可以透過 Novita 的 OpenAI 相容 API 試用 M3,並觀察它在大型程式碼庫審查、工具密集的代理工作流程、長上下文規劃以及需要文字答案的多模態輸入任務上的表現。
什麼是 MiniMax M3?
MiniMax M3 是 MiniMax 推出的較新 M 系列模型,專注於編碼、代理推理、工具使用、長上下文工作以及多模態輸入理解。在 Novita AI 上,它以無伺服器聊天模型 minimax/minimax-m3 的形式提供。
測試它的理由很簡單:M3 為您提供了承載專案上下文的巨大空間,並且可以讀取文字、圖片和影片,同時回傳文字。當任務包含多於一種證據時,這種組合非常有用:原始碼檔案、日誌、螢幕截圖、設計說明或簡短的產品導覽。
對使用者而言,實際界限很簡單:使用 M3 理解混合輸入,並回傳基於文字的分析、計畫、解釋或程式碼建議。它不是圖片生成器或影片生成器。在將其輸出用於生產環境之前,請使用您自己的驗收標準進行測試。
M3 在 Novita AI 上線後有哪些變化?
MiniMax M3 現已作為 minimax/minimax-m3 在 Novita AI 上可用。您可以開啟 MiniMax-M3 模型頁面 查看即時列表,然後透過 Novita 的 OpenAI 相容聊天補全端點呼叫它。
若要進行首次測試,請使用下方的模型 ID、基本 URL、端點、支援的模態、上下文和輸出限制,然後執行操作指南區段中的小型 Python 或 curl 請求。
如果您的堆疊已經使用 OpenAI SDK 模式,通常只需更改基本 URL、API 金鑰和模型字串即可開始。在生產環境上線前,請執行您對任何模型遷移時都會進行的相同檢查:延遲、token 使用量、工具行為以及您自己工作負載的成本。
Novita API 規格與模型 ID
| Novita 模型 ID | minimax/minimax-m3 |
| 模型顯示名稱 | MiniMax-M3 |
| 模型類型 | 聊天 |
| 上下文長度 | 1,000,000 tokens |
| 最大輸出 | 131,072 tokens |
| 輸入模態 | 文字、圖片、影片 |
| 輸出模態 | 文字 |
| 支援功能 | 無伺服器、函數呼叫、結構化輸出、推理 |
| OpenAI 相容基本 URL | https://api.novita.ai/openai |
| 聊天端點 | /v1/chat/completions |
請使用 Novita 模型頁面查看最新的 MiniMax-M3 列表,並在需要請求欄位、認證或參數詳細資訊時參考 API 參考文件。
如何在 Novita AI 上使用 MiniMax M3
當您想透過 Novita 的 OpenAI 相容 API 測試 MiniMax M3 時,請使用此快速路徑。
步驟 1:開啟 Novita LLM API 文件
從 Novita 的 LLM API 指南 開始,了解整合模式。將 建立聊天補全 API 參考 放在手邊,以獲取請求欄位、回應格式和可選參數。
步驟 2:準備您的 API 金鑰、基本 URL 和模型 ID
對於首次呼叫,您需要三個值:您的 Novita API 金鑰、OpenAI 相容基本 URL https://api.novita.ai/openai 以及模型 ID minimax/minimax-m3。將 API 金鑰存放在環境變數或秘密管理器中,而不是硬編碼在應用程式程式碼中。
步驟 3:執行 Python 測試請求
以下是一個使用 OpenAI SDK 模式的簡短 Python 範例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="minimax/minimax-m3",
messages=[
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty.",
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks.",
},
],
max_tokens=1200,
temperature=0.2,
)
print(response.choices[0].message.content)
步驟 4:使用 curl 測試相同請求
以下是使用 curl 的相同範例:
curl "https://api.novita.ai/openai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-d '{
"model": "minimax/minimax-m3",
"messages": [
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty."
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks."
}
],
"max_tokens": 1200,
"temperature": 0.2
}'
步驟 5:使用真實的編碼任務進行評估
在首次評估時,請避免要求建立整個應用程式。相反地,給 M3 一個小而真實的任務:五個相關檔案、一個失敗的測試,以及一個要求先解釋失敗原因再提出最小安全修復的請求。這對推理品質、程式碼局部性以及長上下文是否確實有幫助,是更好的指標。
對開發者的關鍵能力
閱讀 M3 規格的實用方法,不是將其視為一連串巨大數字的清單。每個能力都指向不同類型的工作負載:
- 1M token 上下文: 當任務需要的不僅僅是一個提示和一個檔案時非常有用,例如倉庫審查、長篇問題歷史、日誌、規格或遷移計畫。如果任務是簡短的編碼問題,而較小的模型已經做得很好,那麼這就沒那麼有用了。
- 函數呼叫與結構化輸出: 對於需要呼叫工具、回傳 JSON 格式結果或將工作傳遞給其他服務的代理來說,值得測試。這些功能本身並不能使代理變得可靠;它們只是為您提供了正確評估工具密集型工作流程所需的機制。
- 文字、圖片與影片輸入: 當工程工作包含視覺證據時非常有用:UI 螢幕截圖、工作流程錄影、架構圖或產品導覽。由於輸出是文字,最適合的應用是解釋、除錯、摘要、分類和實作規劃。
- 推理支援: 在您要求 M3 比較選項、找出風險或解釋為什麼某個修復比另一個更安全時最有價值。對於簡單的提取或路由任務,額外的推理預算可能不值得花費成本。
實際的測試是這些能力是否能減少您工作流程中的步驟。如果它們只讓提示看起來更令人印象深刻,請使用更小或更便宜的模型。如果它們能讓模型保留相關的專案狀態、檢查視覺上下文並回傳結構化決策,那麼 M3 是更好的候選者。
基準測試與評估說明
MiniMax 報告了 M3 在編碼、終端機、瀏覽和代理基準測試中的強勁結果。請將下方的基準圖表作為有來源依據的起點,然後在 Novita AI 上針對您自己的提示、倉庫、工具和成本目標比較 M3。
官方 MiniMax 基準圖表顯示 M3 在 SWE Bench Pro 為 59.0,Terminal Bench 2.1 為 66.0,VIBE V2 為 50.1,SVG-Bench 為 63.7,KernelBench Hard 為 28.8,BrowseComp 為 83.5,GDPval-rubrics 為 74.7,BankerToolBench 為 76.1,MCP Atlas 為 74.2,以及 OSWorld-verified 為 70.0。這些是 MiniMax 報告的分數,因此請將其視為評估信號,而非生產效能的保證。
對於代理式編碼,請在切換流量之前建立一個小型評估集。追蹤解題率、工具呼叫準確率、重試行為、每道題目的成本以及您自己倉庫中的失敗模式。
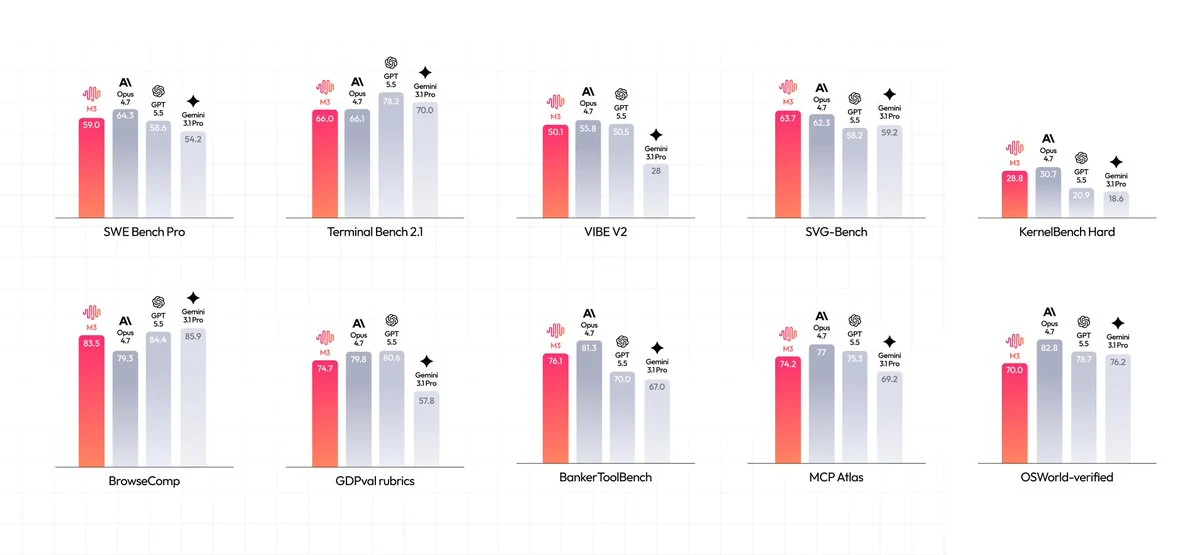
來源:MiniMax 官方基準圖表。分數由 MiniMax 報告,應在生產使用前根據您自己的工作負載進行驗證。
定價說明與成本檢查
於 2026 年 6 月 1 日檢查的 Novita 即時模型列表 API 回傳了 minimax/minimax-m3 的原始定價欄位:輸入 3000 和輸出 12000。解釋為每 1M tokens 的美元價格,這些欄位對應到每百萬輸入 tokens 0.30 美元,每百萬輸出 tokens 1.20 美元。請在生產使用前檢查 Novita 模型頁面和帳戶儀表板,因為顯示的價格可能會變動。
對於 Novita AI 上的生產估算,請使用即時模型頁面和帳戶儀表板作為權威來源,然後根據實際輸入 tokens、輸出 tokens、快取讀取行為和重試率進行計算。
避免使用如「Claude Sonnet 的 20%」這類粗略的捷徑。若要進行有用的比較,請使用目前的 Novita 模型頁面或帳戶儀表板費率,並根據您自己的 token 組合、輸出長度、重試次數和延遲目標進行估算。
MiniMax M3 與 MiniMax M2.7、M2 及 M1 的比較
如果您已經讀過 MiniMax M2.7 on Novita AI 文章,主要區別在於範圍。M2.7 涵蓋了一個具有 204,800 token 上下文視窗的先前代理式編碼模型。M3 將上限提高到 1M token 上下文視窗,增加了多模態輸入,並在編碼和代理基準測試中帶來了更廣泛的 MiniMax 回報覆蓋範圍。
與 M2.7 和 M2.5 相比,當您需要測試更大的專案狀態、工具密集型工作流程或多模態推理時,請選擇 M3。與 MiniMax M1 on Novita AI 相比,M3 與其說是將長上下文作為標題,不如說是將該上下文應用於編碼、瀏覽、終端機和代理任務。
MiniMax M3 的適用場景
一個實際的測試是大型程式碼庫審查。給 M3 一份功能簡報、相關的原始碼檔案、日誌、失敗的測試輸出以及先前的實作說明。然後要求它找出最小的安全變更,或在任何人開始編輯程式碼之前要解決的主要風險。
它也適用於測試代理式編碼助手:搜尋檔案、規劃變更、呼叫工具並回傳結構化結果。Novita 的函數呼叫和結構化輸出支援對此有所幫助,但真正的測試是當工具失敗、上下文雜訊多或正確的作法是停下來要求澄清時,M3 的表現如何。
對於產品和工程團隊而言,多模態角度也值得測試。M3 可以讀取 UI 螢幕截圖、檢查工作流程錄影、從架構圖中提取實作任務,或將視覺 QA 回饋轉換為更清晰的工單。
何時不應該選擇 MiniMax M3
當開發者工作流程需要長上下文、工具使用或多模態輸入來減少審查時間時,請選擇 M3。當任務是簡單的提取、簡短的問答或路由時,請使用較小的模型。在生產環境中,請在錯誤成本高昂的任務上保留驗收測試和人為審查。
如果您的團隊需要獨立的基準證據才能採用某個模型,請在 Novita AI 上針對具有代表性的倉庫、提示、工具循環、延遲目標和預算限制進行評估。這會比單純比較上線頁面的數字提供更清晰的答案。
常見問題
MiniMax M3 在 Novita AI 上線了嗎?
是的。即時的 Novita 模型頁面列出了 MiniMax-M3,且 OpenAI 相容的模型端點將 minimax/minimax-m3 回傳為活躍的聊天模型。
我應該使用哪個模型 ID?
使用 minimax/minimax-m3 搭配 Novita 的 OpenAI 相容 LLM API。
MiniMax M3 在 Novita 上支援多少上下文長度?
Novita 列出 MiniMax-M3 具有 1,000,000 token 的上下文長度和 131,072 的最大輸出 tokens。
MiniMax M3 會生成圖片或影片嗎?
本草案中沒有經過驗證的 Novita 聲明支援圖片或影片輸出生成。已驗證的模態組合是文字、圖片和影片輸入,以及文字輸出。
我該如何評估用於編碼代理的 MiniMax M3?
在真實任務上進行測試:倉庫搜尋、失敗的測試、長篇問題歷史、工具呼叫、結構化輸出和雜訊上下文。追蹤解題率、工具呼叫品質、成本、延遲和失敗恢復,而不是僅依賴已發布的基準數字。



