

Google 的 Gemma 4 现已登陆 Novita AI。两款较大模型——31B 和 26B A4B——已在 Model API 上线。全部四种规格(包括端侧模型 E2B 和 E4B)均可通过 GPU Application 部署:这是 Novita AI 的一键模型部署产品,你只需选择模型、启动实例即可运行。
本文将介绍 Gemma 4 到底是什么、不同架构之间的区别、以及每种规格的适用场景——这样你可以在开始构建之前选择正确的接入路径。
Gemma 4 是什么?
Gemma 4 是 Google 第四代开放模型系列,采用三种不同的架构构建,针对不同的内存和性能目标进行了优化。该系列涵盖从端侧推理到服务器级部署的各种场景,每种架构都围绕特定的内存占用和性能目标设计。
四种模型规格如下:
| 模型 | 架构 | 参数量 | 上下文 | 模态 |
|---|---|---|---|---|
| Gemma 4 E2B | Dense(小型) | 2.3B 有效,5.1B 含 embeddings | 128K | 文本、视觉、音频 |
| Gemma 4 E4B | Dense(小型) | 4.5B 有效,7.9B 含 embeddings | 128K | 文本、视觉、音频 |
| Gemma 4 26B A4B | MoE | 4B 活跃 / 26B 总参数量 | 256K | 文本、视觉 |
| Gemma 4 31B | Dense | 31B | 256K | 文本、视觉 |
所有四种规格都包含指令调优(-it)变体以及基本的预训练检查点。
三种架构的工作原理
Dense 架构(31B):针对长上下文质量构建
31B 模型是旗舰级 Dense 架构。它在 Gemma 基线基础上进行了架构改进,提升了效率和长上下文质量。
MoE 架构(26B A4B):高能力、固定内存占用
26B A4B 模型采用混合专家(MoE)设计,共有 128 个专家——大量的小型专家——外加一个始终活跃的共享专家。每次前向传播仅激活 8 个专家,在 26.8B 总参数量中产生 3.8B 活跃参数。
该设计针对可在高端笔记本电脑上运行并应用量化的服务器架构的内存占用进行优化。提供了基于量化感知训练(QAT)的检查点——Q3-2、Q3-0 和 Q4-0——可在降低内存占用的情况下实现高质量推理。
小型架构(E2B 和 E4B):面向端侧,具备真实吞吐量
E2B 和 E4B 模型专为端侧推理而设计。该设计以 Gemma 4 Dense 基础为起点,并添加了来自 Gemma 3n 的精选创新,以提高每秒 token 数、减少预填充时间,并扩展设备、框架和运行时的兼容性。
Gemma 3n 的两个关键特性得到了保留:
- 逐层嵌入(PLE):来自 Gemma 3n
- KV-Cache 共享:在质量影响最小的情况下,减少预填充时间和 KV-cache 内存大小
关键能力
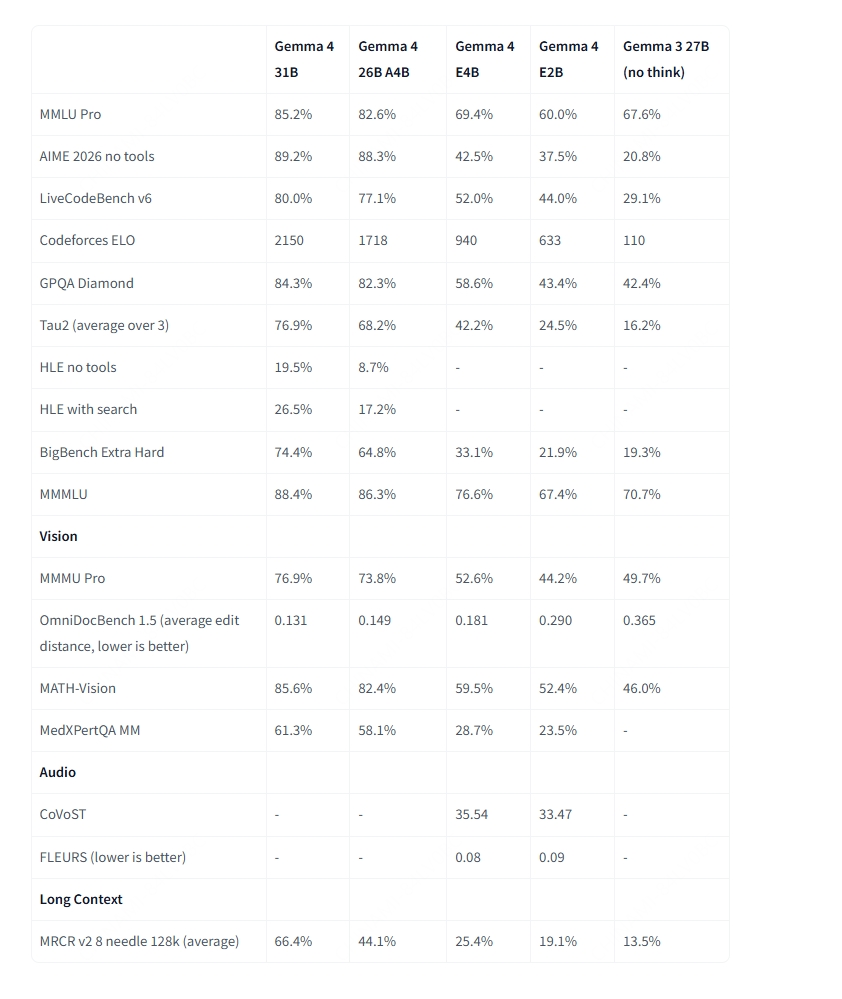
除了架构差异外,所有 Gemma 4 规格都共享一套强大的内置能力:
- 思考 —— 一种内置推理模式,让模型在回答前逐步思考。
- 长上下文 —— E2B 和 E4B 为 128K token,26B A4B 和 31B 为 256K token。
- 图像理解 —— 目标检测、文档和 PDF 解析、屏幕和 UI 理解、图表理解、OCR、手写识别和指向。
- 视频理解 —— 通过处理帧序列分析视频。
- 交错多模态输入 —— 文本和图像可在一个提示中自由混合。
- 函数调用 —— 原生支持结构化工具使用和代理工作流。
- 编码 —— 代码生成、补全和修正。
- 多语言 —— 开箱即用支持 35+ 种语言,预训练覆盖 140+ 种语言。
- 音频(仅 E2B 和 E4B) —— 多语言的自动语音识别(ASR)和语音到翻译文本。
多模态能力:视觉与音频
视觉:全部四种规格,原生宽高比
所有四种 Gemma 4 规格都支持视觉输入。图像以其原生宽高比使用混合分辨率处理——没有平移扫描裁剪,也没有强制正方形调整大小。
音频:仅 E2B 和 E4B
仅小型模型 E2B 和 E4B 支持音频输入。26B A4B 和 31B 不支持音频。
音频模型支持:
- 自动语音识别(ASR) —— 将语音转录为源语言的文本。
- 自动语音翻译(AST) —— 将源语言的语音转录并将输出翻译成目标语言。
推荐的采样参数
Google 在 Gemma 4 用例中标准化的采样配置:
| 参数 | 值 |
|---|---|
| temperature | 1.0 |
| top_p | 0.95 |
| top_k | 64 |
将这些作为 Gemma 4 用例的基线采样配置。
模型对比
| 模型 | 上下文 | 音频 | 接入方式 |
|---|---|---|---|
| Gemma 4 31B | 256K | 否 | Model API 或 GPU Application |
| Gemma 4 26B A4B | 256K | 否 | Model API 或 GPU Application |
| Gemma 4 E4B | 128K | 是 | GPU Application |
| Gemma 4 E2B | 128K | 是 | GPU Application |
在 Novita AI 上运行 Gemma 4
Novita AI 提供两种运行 Gemma 4 的方式,具体取决于你希望使用托管 API 还是完全控制你的实例。
Model API:31B 和 26B A4B
Gemma 4 31B 和 Gemma 4 26B A4B 已在 Novita AI Model API 上线——兼容 OpenAI,按 token 付费,无需月度承诺。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
如果你已经在使用 OpenAI 兼容的客户端,无需更改 SDK。只需更换 base_url 和 api_key,更新模型字符串即可运行。
GPU Application:全部四种规格
所有四种 Gemma 4 模型——E2B、E4B、26B A4B 和 31B——均可通过 Novita AI GPU Application 使用。GPU Application 是一个预配置、即用型模型部署库:选择模型、启动实例,一键运行。无需基础设施设置,无需手动容器配置。
通过 GPU Application 启动 Gemma 4 →
结论
Gemma 4 在一个模型系列下带来了三种截然不同的架构:用于长上下文质量的 31B Dense 模型、用于受约束内存目标并支持 QAT 的 26B A4B MoE 模型,以及专为端侧推理构建的小型 E2B/E4B 模型。视觉输入在所有四种规格上均可用,而音频(ASR 和 AST)仅 E2B 和 E4B 支持。所有规格都内置了思考、函数调用、多语言支持和视频理解。
在 Novita AI 上,31B 和 26B A4B 已在 Model API 上线——兼容 OpenAI,可直接集成。包括小型模型在内的全部四种规格均可通过 GPU Application 进行一键部署。
常见问题
Gemma 4 31B 和 Gemma 4 26B A4B 有什么区别?
31B 是 Dense 模型——每次前向传播所有 31.3B 参数均激活,针对长上下文质量优化。26B A4B 是混合专家模型,总参数量 26.8B,但推理时仅 3.8B 活跃,专为受约束内存部署并支持量化而设计。
所有 Gemma 4 规格都支持视觉和音频吗?
视觉在所有四种规格上均受支持。音频仅 E2B 和 E4B 支持——26B A4B 和 31B 接受文本和图像输入,但不接受音频。
Gemma 4 有哪些可用的量化格式?
针对 MoE(26B A4B)变体提供了基于 QAT 的检查点:Q3-2、Q3-0 和 Q4-0。
什么是 Novita AI GPU Application?
GPU Application 是 Novita AI 上的一键模型部署产品。从一个预配置、即用型模型应用库中选择——包括 LLM、图像、音频和视频——选择模型、启动实例即可运行。无需容器设置或基础设施配置。全部四种 Gemma 4 规格均可在此使用。
Novita AI 是一个 AI 与智能体云平台,帮助开发者和初创公司以高性能、高可靠性和成本效益构建、部署和扩展模型及智能体应用。



