

جيما 4 من جوجل متاح الآن على نوفيتا AI. النموذجان الأكبران — 31B و 26B A4B — متاحان الآن على Model API. جميع الأحجام الأربعة، بما في ذلك النماذج المخصصة للأجهزة E2B و E4B، يمكن نشرها عبر GPU Application: وهو منتج نشر النماذج بنقرة واحدة من نوفيتا AI حيث تختار النموذج، وتشغل نسخة، وتبدأ في العمل فوراً.
تغطي هذه المقالة ما هو جيما 4 بالضبط، وكيف تختلف البنى التحتية له، وما هو الغرض من كل حجم — حتى تتمكن من اختيار مسار الوصول المناسب قبل أن تبدأ في البناء.
ما هو جيما 4؟
جيما 4 هو عائلة النماذج المفتوحة الجيل الرابع من جوجل، تم بناؤها عبر ثلاث بنى تحتية مختلفة محسنة لأهداف ذاكرة وأداء مختلفة. يغطي الخطاف كل شيء من الاستدلال على الأجهزة إلى عمليات النشر على مستوى الخوادم، مع تصميم كل بنية تحتية حول أهداف محددة لحجم الذاكرة والأداء.
الأحجام الأربعة للنموذج هي:
| النموذج | البنية التحتية | المعلمات | السياق (عدد الرموز) | الأنماط |
|---|---|---|---|---|
| Gemma 4 E2B | كثيف (صغير) | 2.3B فعال، 5.1B مع التضمينات | 128K | نص، رؤية حاسوبية، صوت |
| Gemma 4 E4B | كثيف (صغير) | 4.5B فعال، 7.9B مع التضمينات | 128K | نص، رؤية حاسوبية، صوت |
| Gemma 4 26B A4B | خليط الخبراء (MoE) | 4B نشط / 26B إجمالي | 256K | نص، رؤية حاسوبية |
| Gemma 4 31B | كثيف | 31B | 256K | نص، رؤية حاسوبية |
تأتي جميع الأحجام الأربعة مع متغيرات معدلة للتعليمات (-it) إلى جانب نقاط التفتيش الأساسية المدربة مسبقاً.
كيف تعمل البنى التحتية الثلاث
البنية التحتية الكثيفة (31B): مصممة لجودة السياق الطويل
النموذج 31B هو البنية التحتية الكثيفة الرائدة. فهو يوسع أساس جيما مع تغييرات معمارية تحسن الكفاءة وجودة السياق الطويل.
بنية خليط الخبراء (26B A4B): قدرة عالية، حجم ذاكرة ثابت
يستخدم نموذج 26B A4B تصميم خليط الخبراء (MoE) مع 128 خبيراً إجمالياً — عدد كبير من الخبراء الصغار — بالإضافة إلى خبير مشترك واحد يكون نشطاً دائماً. يتم تفعيل 8 خبراء فقط في كل تمرير أمامي، مما ينتج 3.8B معلمة نشطة من أصل 26.8B إجمالي.
يهدف التصميم إلى أحجام ذاكرة يمكن تشغيلها على أجهزة الكمبيوتر المحمولة عالية الأداء وبنى الخوادم مع تطبيق التكميم. يتم توفير نقاط تفتيش تدريب واعية بالتكميم (QAT) — Q3-2 و Q3-0 و Q4-0 — مما يتيح استدلالاً عالي الجودة بأحجام ذاكرة مخفضة.
البنية التحتية الصغيرة (E2B و E4B): للاستدلال على الأجهزة مع إنتاجية حقيقية
تم تصميم نماذج E2B و E4B خصيصاً للاستدلال على الأجهزة. يبدأ التصميم من الأساس الكثيف لـ جيما 4 ويضيف ابتكارات مختارة من جيما 3n لزيادة عدد الرموز في الثانية، وتقليل وقت التعبئة المسبقة، وتوسيع التوافق عبر الأجهزة والأطر وبيئات التشغيل.
ميزتان رئيسيتان محفوظتان من جيما 3n:
- تضمينات كل طبقة (PLE): محفوظة من جيما 3n
- مشاركة ذاكرة التخزين المؤقت KV: تقلل من وقت التعبئة المسبقة وحجم ذاكرة التخزين المؤقت KV مع تأثير ضئيل على الجودة
القدرات الأساسية
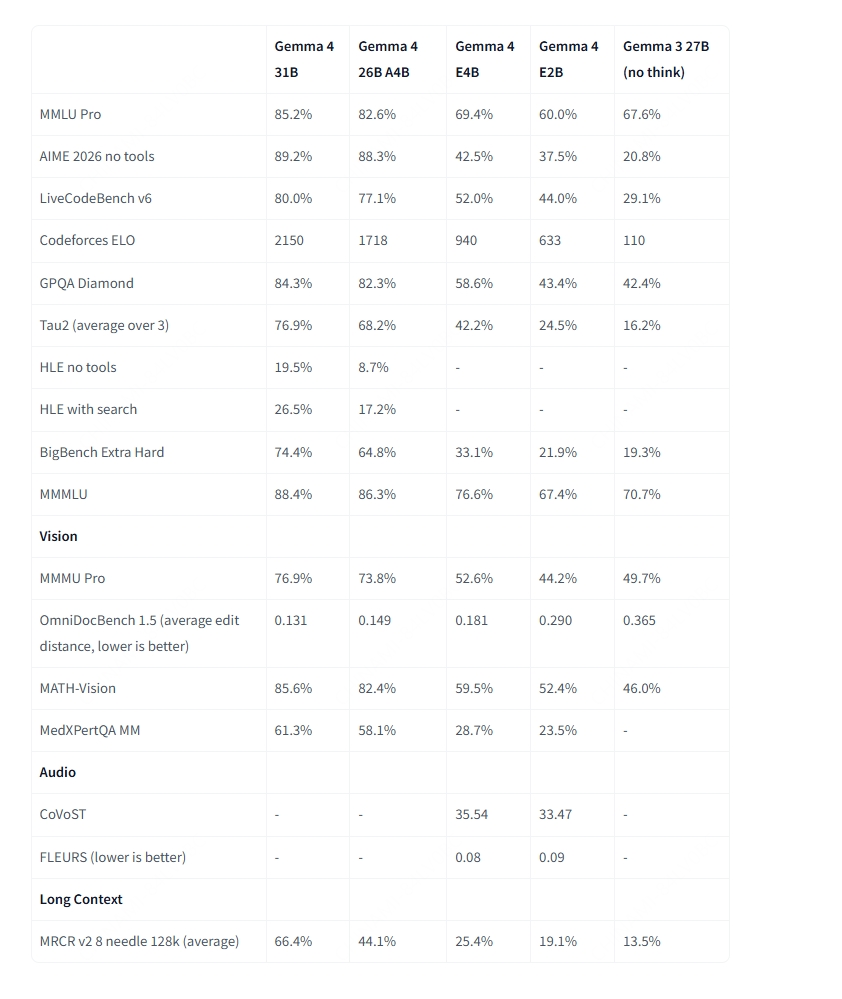
بالإضافة إلى اختلافات البنية التحتية، تشترك جميع أحجام جيما 4 في مجموعة قوية من القدرات المدمجة:
- التفكير — وضع استدلال مدمج يسمح للنموذج بالتفكير خطوة بخطوة قبل الإجابة.
- السياق الطويل — 128 ألف رمز لنماذج E2B و E4B، و 256 ألف رمز لنماذج 26B A4B و 31B.
- فهم الصور — اكتشاف الأشياء، تحليل المستندات وملفات PDF، فهم الشاشة وواجهة المستخدم، فهم الرسوم البيانية، التعرف الضوئي على الرموز (OCR)، التعرف على الخط اليدوي، والتحديد.
- فهم الفيديو — تحليل الفيديو عن طريق معالجة تسلسلات الإطارات.
- الإدخال متعدد الأنماط المتداخل — يمكن خلط النصوص والصور بحرية في موجه واحد.
- استدعاء الدوال — دعم أصلي لاستخدام الأدوات المنظمة وسير عمل الوكلاء.
- البرمجة — توليد الكود، إكماله، وتصحيحه.
- متعدد اللغات — دعم جاهز لأكثر من 35 لغة، مدربة مسبقاً على أكثر من 140 لغة.
- الصوت (نموذجان E2B و E4B فقط) — التعرف التلقائي على الكلام (ASR) وتحويل الكلام إلى نص مترجم عبر لغات متعددة.
القدرات متعددة الأنماط: الرؤية الحاسوبية والصوت
الرؤية الحاسوبية: جميع الأحجام الأربعة، نسبة أبعاد أصلية
تدعم جميع أحجام جيما 4 الأربعة إدخال الرؤية الحاسوبية. تتم معالجة الصور بنسبة أبعادها الأصلية باستخدام معالجة الدقة المختلطة — لا قص وتصغير تلقائي ولا إعادة تحجيم إجبارية إلى مربع.
الصوت: نموذجان E2B و E4B فقط
يدعم إدخال الصوت فقط على النماذج الصغيرة E2B و E4B. النموذجان 26B A4B و 31B لا يدعمان الصوت.
يدعم نموذج الصوت الميزات التالية:
- التعرف التلقائي على الكلام (ASR) — يحول الكلام إلى نص باللغة المصدر.
- الترجمة التلقائية للكلام (AST) — يحول الكلام من لغة مصدر ويترجم المخرج إلى لغة هدف.
معلمات أخذ العينات الموصى بها
التكوين القياسي لأخذ العينات من جوجل عبر جميع حالات استخدام جيما 4:
| المعامل | القيمة |
|---|---|
| temperature | 1.0 |
| top_p | 0.95 |
| top_k | 64 |
استخدم هذه كتكوين أساسي لأخذ العينات عبر جميع حالات استخدام جيما 4.
مقارنة النماذج
| النموذج | السياق (عدد الرموز) | الصوت | طريقة الوصول |
|---|---|---|---|
| Gemma 4 31B | 256K | لا | Model API أو GPU Application |
| Gemma 4 26B A4B | 256K | لا | Model API أو GPU Application |
| Gemma 4 E4B | 128K | نعم | GPU Application |
| Gemma 4 E2B | 128K | نعم | GPU Application |
تشغيل جيما 4 على نوفيتا AI
تقدم نوفيتا AI طريقتين لتشغيل جيما 4، اعتماداً على ما إذا كنت تريد واجهة برمجة تطبيقات مُدارة أو تحكماً كاملاً في نسختك.
Model API: 31B و 26B A4B
نماذج جيما 4 31B و جيما 4 26B A4B متاحة على Novita AI Model API — متوافقة مع OpenAI، تُدفع حسب الرمز، وبدون التزام شهري.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
لا حاجة لتغييرات في SDK إذا كنت تستخدم بالفعل عميلاً متوافقاً مع OpenAI. استبدل base_url و api_key، وقم بتحديث سلسلة النموذج، وستكون جاهزاً للعمل فوراً.
GPU Application: جميع الأحجام الأربعة
جميع نماذج جيما 4 الأربعة — E2B و E4B و 26B A4B و 31B — متاحة عبر Novita AI GPU Application. GPU Application هو مكتبة من عمليات نشر النماذج المُعدة مسبقاً والجاهزة للتشغيل: اختر النموذج، شغل نسخة، وسيعمل بنقرة واحدة. لا حاجة لإعداد البنية التحتية ولا تكوين يدوي للحاويات.
شغل جيما 4 عبر GPU Application →
الخلاصة
يجمع جيما 4 بين ثلاث بنى تحتية متميزة تحت عائلة نماذج واحدة: نموذج كثيف 31B لجودة السياق الطويل، نموذج MoE 26B A4B مصمم لأهداف ذاكرة مقيدة مع دعم QAT، ونماذج صغيرة E2B/E4B مصممة خصيصاً للاستدلال على الأجهزة. إدخال الرؤية الحاسوبية متاح لجميع الأحجام الأربعة، بينما الصوت (ASR و AST) مدعوم فقط على E2B و E4B. جميع الأحجام تأتي مدمجاً مع ميزات التفكير، واستدعاء الدوال، والدعم متعدد اللغات، وفهم الفيديو.
على نوفيتا AI، النموذجان 31B و 26B A4B متاحان الآن على Model API — متوافقان مع OpenAI وجاهزان للاستخدام الفوري. جميع الأحجام الأربعة، بما في ذلك النماذج الصغيرة، متاحة عبر GPU Application للنشر بنقرة واحدة.
الأسئلة الشائعة
ما هو الفرق بين جيما 4 31B و جيما 4 26B A4B؟
النموذج 31B هو نموذج كثيف — جميع المعلمات البالغة 31.3B تكون نشطة في كل تمرير أمامي، محسنة لجودة السياق الطويل. النموذج 26B A4B هو نموذج خليط خبراء بإجمالي 26.8B معلمة ولكن فقط 3.8B نشطة في وقت الاستدلال، مصمم لعمليات النشر ذات الذاكرة المقيدة مع دعم التكميم.
هل تدعم جميع أحجام جيما 4 الرؤية الحاسوبية والصوت؟
الرؤية الحاسوبية مدعومة في جميع الأحجام الأربعة. الصوت مدعوم فقط على E2B و E4B — النموذجان 26B A4B و 31B يقبلان إدخال النص والصورة ولكن ليس الصوت.
ما هي صيغ التكميم المتاحة لـ جيما 4؟
يتم توفير نقاط تفتيش تعتمد على تدريب واعية بالتكميم (QAT) لنموذج خليط الخبراء (26B A4B): Q3-2 و Q3-0 و Q4-0.
ما هو تطبيق GPU من نوفيتا AI؟
تطبيق GPU هو منتج نشر النماذج بنقرة واحدة على نوفيتا AI. اختر من مكتبة تطبيقات النماذج المُعدة مسبقاً والجاهزة للتشغيل — نماذج اللغة الكبيرة (LLM)، الصور، الصوت، والفيديو — اختر النموذج، شغل نسخة، وسيعمل فوراً. لا حاجة لإعداد الحاويات أو تكوين البنية التحتية. جميع أحجام جيما 4 الأربعة متاحة هناك.
نوفيتا AI هي منصة سحابية للذكاء الاصطناعي والوكلاء تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج وتطبيقات الوكلاء بأداء عالٍ، وموثوقية، وكفاءة في التكاليف.



