

O Gemma 4 do Google já está disponível na Novita AI. Os dois modelos maiores — 31B e 26B A4B — já estão disponíveis na API de Modelos. Todos os quatro tamanhos, incluindo os modelos E2B e E4B para execução em dispositivo, podem ser implantados via GPU Application: o produto de implantação de modelos com um clique da Novita AI, onde você escolhe um modelo, inicia uma instância e já está em execução.
Este artigo explica o que é o Gemma 4, como as arquiteturas diferem e para que cada tamanho foi projetado — para que você possa escolher o caminho de acesso ideal antes de começar a desenvolver.
Experimente o Gemma 4 31B agora
Experimente o Gemma 4 26B A4B agora
O que é o Gemma 4?
O Gemma 4 é a família de modelos abertos de quarta geração do Google, desenvolvida com três arquiteturas diferentes otimizadas para diferentes metas de memória e desempenho. A linha abrange desde inferência em dispositivo até implantações de nível de servidor, com cada arquitetura projetada para ocupações de memória e metas de desempenho específicas.
Os quatro tamanhos de modelo são:
| Modelo | Arquitetura | Parâmetros | Contexto | Modalidades |
|---|---|---|---|---|
| Gemma 4 E2B | Dense (pequeno) | 2.3B efetivos, 5.1B com incorporações | 128K | Texto, Visão, Áudio |
| Gemma 4 E4B | Dense (pequeno) | 4.5B efetivos, 7.9B com incorporações | 128K | Texto, Visão, Áudio |
| Gemma 4 26B A4B | MoE | 4B ativos / 26B total | 256K | Texto, Visão |
| Gemma 4 31B | Dense | 31B | 256K | Texto, Visão |
Todos os quatro tamanhos incluem variantes com ajuste por instrução (-it) além dos checkpoints pré-treinados base.
Como funcionam as três arquiteturas
Arquitetura Dense (31B): projetada para qualidade em contexto longo
O modelo 31B é a arquitetura densa principal. Ele amplia a linha base do Gemma com alterações arquiteturais que melhoram a eficiência e a qualidade em contexto longo.
Arquitetura MoE (26B A4B): alta capacidade e ocupação de memória fixa
O modelo 26B A4B usa um design de Mixture of Experts (MoE) com 128 especialistas no total — um número alto de especialistas pequenos — além de um único especialista compartilhado que está sempre ativo. Apenas 8 especialistas são ativados por forward pass, resultando em 3,8B de parâmetros ativos de um total de 26,8B.
O design tem como alvo ocupações de memória que permitem a execução em laptops de alto desempenho e arquiteturas de servidor com quantização aplicada. São fornecidos checkpoints de treinamento consciente de quantização (QAT) — Q3-2, Q3-0 e Q4-0 — permitindo inferência de alta qualidade com ocupações de memória reduzidas.
Arquitetura pequena (E2B e E4B): execução em dispositivo com throughput real
Os modelos E2B e E4B são projetados especificamente para inferência em dispositivo. O design parte da base densa do Gemma 4 e adiciona inovações selecionadas do Gemma 3n para aumentar os tokens por segundo, reduzir o tempo de prefill e ampliar a compatibilidade com diferentes dispositivos, frameworks e runtimes.
Duas funcionalidades principais foram herdadas do Gemma 3n:
- Incorporações por camada (PLE): mantidas do Gemma 3n
- Compartilhamento de KV-Cache: reduz tanto o tempo de prefill quanto o tamanho de memória do KV-Cache com impacto mínimo na qualidade.
Principais funcionalidades
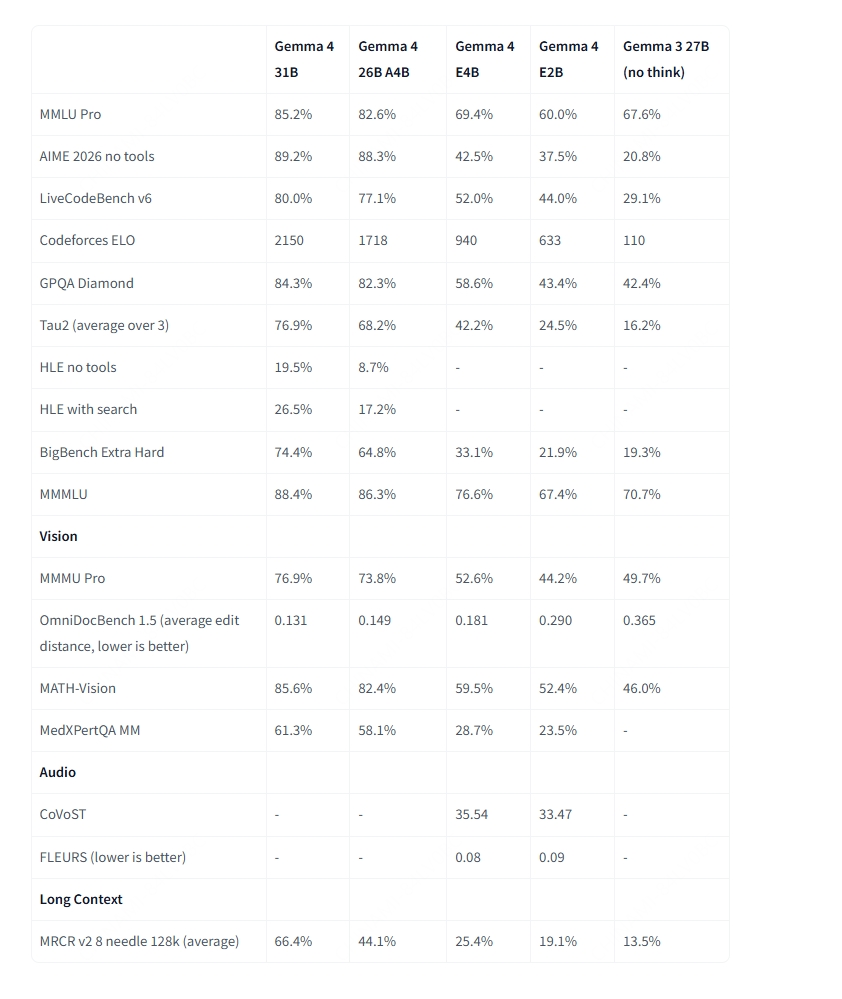
Além das diferenças de arquitetura, todos os tamanhos do Gemma 4 compartilham um conjunto robusto de funcionalidades nativas:
- Pensamento — Um modo de raciocínio nativo que permite que o modelo pense passo a passo antes de responder.
- Contexto longo — 128K tokens para os modelos E2B e E4B, e 256K tokens para os modelos 26B A4B e 31B.
- Compreensão de imagens — Detecção de objetos, parsing de documentos e PDFs, compreensão de telas e interfaces, interpretação de gráficos, OCR, reconhecimento de caligrafia e apontamento.
- Compreensão de vídeo — Análise de vídeo por meio do processamento de sequências de quadros.
- Entrada multimodal intercalada — Texto e imagens podem ser misturados livremente em um único prompt.
- Chamada de funções — Suporte nativo a uso de ferramentas estruturadas e fluxos de trabalho agenticos.
- Programação — Geração, complementação e correção de código.
- Multilíngue — Suporte nativo a mais de 35 idiomas, pré-treinado em mais de 140 idiomas.
- Áudio (apenas E2B e E4B) — Reconhecimento automático de fala (ASR) e conversão de fala para texto traduzido em vários idiomas.
Funcionalidades multimodais: Visão e áudio
Visão: todos os quatro tamanhos, proporção nativa
Todos os quatro tamanhos do Gemma 4 suportam entrada de visão. As imagens são processadas em sua proporção nativa usando processamento de resolução mista — sem recorte panorâmico e sem redimensionamento forçado para quadrado.
Áudio: apenas E2B e E4B
A entrada de áudio é suportada apenas nos modelos pequenos E2B e E4B. Os modelos 26B A4B e 31B não suportam áudio.
O modelo de áudio suporta:
- Reconhecimento Automático de Fala (ASR) — Transcreve a fala em texto no idioma de origem.
- Tradução Automática de Fala (AST) — Transcreve a fala em um idioma de origem e traduz a saída para um idioma de destino.
Parâmetros de amostragem recomendados
Configuração de amostragem padronizada do Google para todos os casos de uso do Gemma 4:
| Parâmetro | Valor |
|---|---|
| temperature | 1.0 |
| top_p | 0.95 |
| top_k | 64 |
Use essa configuração como base para amostragem em todos os casos de uso do Gemma 4.
Comparação de modelos
| Modelo | Contexto | Áudio | Acesso |
|---|---|---|---|
| Gemma 4 31B | 256K | Não | API de Modelos ou GPU Application |
| Gemma 4 26B A4B | 256K | Não | API de Modelos ou GPU Application |
| Gemma 4 E4B | 128K | Sim | GPU Application |
| Gemma 4 E2B | 128K | Sim | GPU Application |
Execute o Gemma 4 na Novita AI
A Novita AI oferece duas formas de executar o Gemma 4, dependendo se você quer uma API gerenciada ou controle total sobre sua instância.
API de Modelos: 31B e 26B A4B
Os modelos Gemma 4 31B e Gemma 4 26B A4B estão disponíveis na API de Modelos da Novita AI — compatível com OpenAI, pagamento por token e sem compromisso mensal.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Nenhuma alteração no SDK é necessária se você já usa um cliente compatível com OpenAI. Basta substituir o base_url e o api_key, atualizar a string do modelo e você já está rodando.
GPU Application: todos os quatro tamanhos
Todos os quatro modelos do Gemma 4 — E2B, E4B, 26B A4B e 31B — estão disponíveis via GPU Application da Novita AI. O GPU Application é uma biblioteca de implantações de modelos pré-configuradas e prontas para uso: escolha um modelo, inicie uma instância e ele já está rodando com um clique. Nenhuma configuração de infraestrutura ou de contêiner manual é necessária.
Inicie o Gemma 4 via GPU Application →
Conclusão
O Gemma 4 reúne três arquiteturas distintas em uma única família de modelos: um modelo denso de 31B para qualidade em contexto longo, um modelo MoE de 26B A4B projetado para metas de memória limitada com suporte a QAT, e modelos pequenos E2B/E4B desenvolvidos especificamente para inferência em dispositivo. A entrada de visão está disponível em todos os quatro tamanhos, enquanto o áudio (ASR e AST) é suportado apenas nos modelos E2B e E4B. Todos os tamanhos incluem nativamente as funcionalidades de pensamento, chamada de funções, suporte multilíngue e compreensão de vídeo.
Na Novita AI, os modelos 31B e 26B A4B já estão disponíveis na API de Modelos — compatível com OpenAI e pronto para uso. Todos os quatro tamanhos, incluindo os modelos pequenos, estão disponíveis via GPU Application para implantação com um clique.
Experimente o Gemma 4 31B agora
Experimente o Gemma 4 26B A4B agora
Perguntas frequentes
Qual a diferença entre o Gemma 4 31B e o Gemma 4 26B A4B?
O 31B é um modelo denso — todos os seus 31,3B de parâmetros estão ativos em cada forward pass, otimizado para qualidade em contexto longo. O 26B A4B é um modelo Mixture of Experts com 26,8B de parâmetros no total, mas apenas 3,8B ativos no momento da inferência, projetado para implantações com memória limitada e suporte a quantização.
Todos os tamanhos do Gemma 4 suportam visão e áudio?
A visão é suportada em todos os quatro tamanhos. O áudio é suportado apenas nos modelos E2B e E4B — os modelos 26B A4B e 31B aceitam entrada de texto e imagem, mas não de áudio.
Quais formatos de quantização estão disponíveis para o Gemma 4?
São fornecidos checkpoints baseados em QAT para a variante MoE (26B A4B): Q3-2, Q3-0 e Q4-0.
O que é o GPU Application da Novita AI?
O GPU Application é um produto de implantação de modelos com um clique da Novita AI. Escolha em uma biblioteca de aplicativos de modelos pré-configurados e prontos para uso — LLM, imagem, áudio e vídeo —, selecione um modelo, inicie uma instância e ele já está rodando. Nenhuma configuração de contêiner ou infraestrutura é necessária. Todos os quatro tamanhos do Gemma 4 estão disponíveis lá.
A Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações agenticas com alto desempenho, confiabilidade e eficiência de custos.



