

Googles Gemma 4 ist jetzt auf Novita AI verfügbar. Die beiden größeren Modelle — 31B und 26B A4B — sind bereits über die Model API live. Alle vier Größen, einschließlich der On-Device-Modelle E2B und E4B, können über die GPU Application bereitgestellt werden: Novita AIs One-Click-Modellbereitstellung, bei der du ein Modell auswählst, eine Instanz startest und es sofort läuft.
Dieser Artikel erklärt, was Gemma 4 genau ist, wie sich die Architekturen unterscheiden und wofür jede Größe entwickelt wurde — damit du den richtigen Zugriffspfad wählst, bevor du mit der Entwicklung beginnst.
Jetzt Gemma 4 31B ausprobieren
Jetzt Gemma 4 26B A4B ausprobieren
Was ist Gemma 4?
Gemma 4 ist Googles Open-Modell-Familie der vierten Generation, die auf drei verschiedenen Architekturen basiert, die für unterschiedliche Speicher- und Leistungsziele optimiert sind. Die Reihe reicht von On-Device-Inferenz bis hin zu Server-Bereitstellungen, wobei jede Architektur auf spezifische Speicherbedarfe und Leistungsziele abgestimmt ist.
Die vier Modellgrößen sind:
| Modell | Architektur | Parameter | Kontext | Modalitäten |
|---|---|---|---|---|
| Gemma 4 E2B | Dense (klein) | 2,3B effektiv, 5,1B mit Einbettungen | 128K | Text, Vision, Audio |
| Gemma 4 E4B | Dense (klein) | 4,5B effektiv, 7,9B mit Einbettungen | 128K | Text, Vision, Audio |
| Gemma 4 26B A4B | MoE | 4B aktiv / 26B gesamt | 256K | Text, Vision |
| Gemma 4 31B | Dense | 31B | 256K | Text, Vision |
Alle vier Größen sind neben den vortrainierten Basis-Checkpoints auch als instruction-tuned (-it) Varianten verfügbar.
Wie die drei Architekturen funktionieren
Dense-Architektur (31B): Entwickelt für Long-Context-Qualität
Das 31B-Modell ist die Flaggschiff-Dense-Architektur. Sie erweitert die Gemma-Basislinie um architektonische Änderungen, die Effizienz und Long-Context-Qualität verbessern.
MoE-Architektur (26B A4B): Hohe Leistungsfähigkeit, feste Speichergröße
Das 26B A4B-Modell verwendet ein Mixture of Experts (MoE)-Design mit insgesamt 128 Experten — einer hohen Anzahl kleiner Experten — plus einem einzelnen gemeinsamen Experten, der immer aktiv ist. Pro Forward-Pass werden nur 8 Experten aktiviert, was 3,8B aktive Parameter bei insgesamt 26,8B Parametern ergibt.
Das Design zielt auf Speichergrößen ab, die auf High-End-Laptops und Server-Architekturen mit angewendeter Quantisierung lauffähig sind. Es werden Checkpoints für quantisierungsbewusstes Training (QAT) — Q3-2, Q3-0 und Q4-0 — bereitgestellt, die eine hochwertige Inferenz bei reduziertem Speicherbedarf ermöglichen.
Kleine Architektur (E2B und E4B): On-Device mit hohem Durchsatz
Die E2B- und E4B-Modelle sind speziell für On-Device-Inferenz entwickelt. Das Design basiert auf der Dense-Basis von Gemma 4 und fügt ausgewählte Innovationen von Gemma 3n hinzu, um die Anzahl der Tokens pro Sekunde zu erhöhen, die Prefill-Zeit zu reduzieren und die Kompatibilität über Geräte, Frameworks und Runtimes hinweg zu erweitern.
Zwei wichtige Funktionen wurden von Gemma 3n übernommen:
- Per-Layer-Embeddings (PLE): Übernommen von Gemma 3n
- KV-Cache-Sharing: Reduziert sowohl die Prefill-Zeit als auch die KV-Cache-Speichergröße mit minimalem Qualitätsverlust
Hauptfunktionen
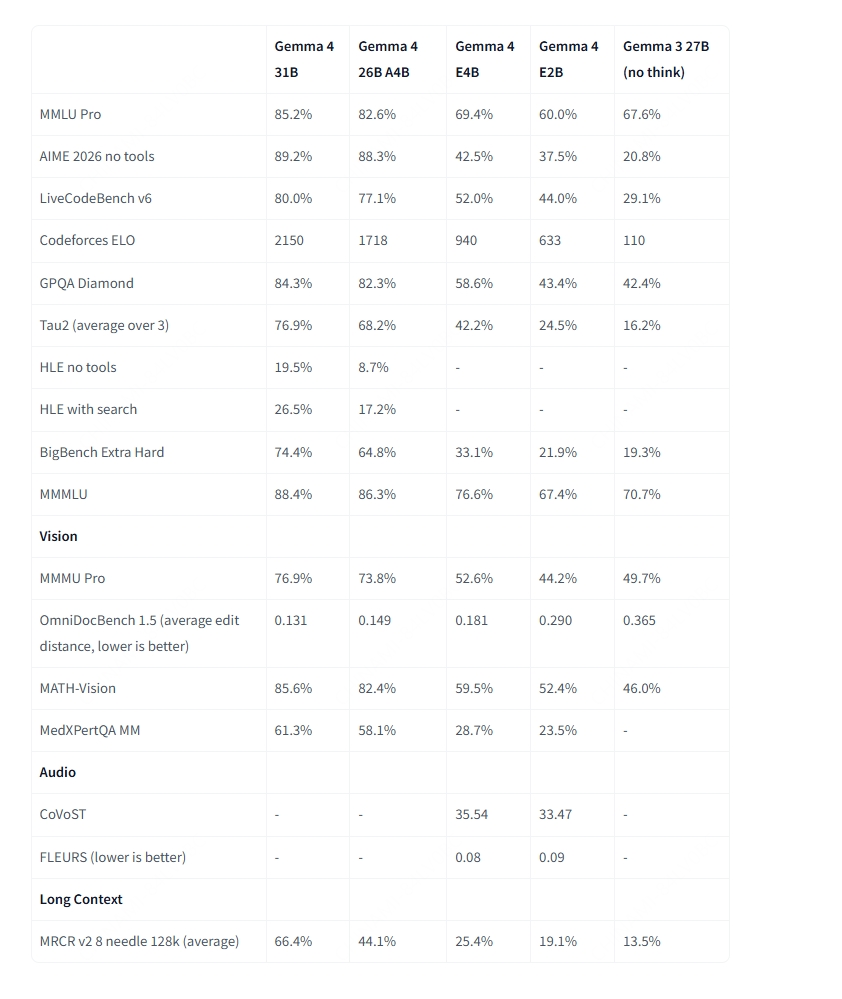
Abgesehen von den Architekturunterschieden verfügen alle Gemma 4-Größen über eine Reihe leistungsstarker integrierter Funktionen:
- Thinking — Ein integrierter Reasoning-Modus, der es dem Modell ermöglicht, Schritt für Schritt zu denken, bevor es antwortet.
- Long Context — 128K Tokens für E2B und E4B, 256K Tokens für 26B A4B und 31B.
- Bildverständnis — Objekterkennung, Dokument- und PDF-Parsing, Bildschirm- und UI-Verständnis, Diagrammverständnis, OCR, Handschrifterkennung und Zeigen.
- Videoverständnis — Analyse von Videos durch Verarbeitung von Bildsequenzen.
- Verschachtelte multimodale Eingabe — Text und Bilder können frei in einem Prompt kombiniert werden.
- Funktionsaufruf — Native Unterstützung für strukturierte Tool-Nutzung und agentische Workflows.
- Codierung — Codegenerierung, Vervollständigung und Korrektur.
- Mehrsprachig — Out-of-the-Box-Unterstützung für über 35 Sprachen, vortrainiert auf über 140 Sprachen.
- Audio (nur E2B und E4B) — Automatische Spracherkennung (ASR) und Sprache-in-übersetzten-Text über mehrere Sprachen hinweg.
Multimodale Funktionen: Vision und Audio
Vision: Alle vier Größen, natives Seitenverhältnis
Alle vier Gemma 4-Größen unterstützen Vision-Eingabe. Bilder werden in ihrem nativen Seitenverhältnis mittels Mixed-Resolution-Verarbeitung verarbeitet — es gibt kein Zuschneiden nach Pan-and-Scan und keine erzwungene quadratische Größenänderung.
Audio: Nur E2B und E4B
Audio-Eingabe wird nur auf den kleinen E2B- und E4B-Modellen unterstützt. Die 26B A4B und 31B unterstützen kein Audio.
Das Audio-Modell unterstützt:
- Automatische Spracherkennung (ASR) — Transkribiert Sprache in Text in der Ausgangssprache.
- Automatische Sprachübersetzung (AST) — Transkribiert Sprache in einer Ausgangssprache und übersetzt die Ausgabe in eine Zielsprache.
Empfohlene Sampling-Parameter
Googles standardisierte Sampling-Konfiguration für alle Gemma 4-Anwendungsfälle:
| Parameter | Wert |
|---|---|
| temperature | 1,0 |
| top_p | 0,95 |
| top_k | 64 |
Nutze diese als Baseline-Sampling-Konfiguration für alle Gemma 4-Anwendungsfälle.
Modellvergleich
| Modell | Kontext | Audio | Zugriff |
|---|---|---|---|
| Gemma 4 31B | 256K | Nein | Model API oder GPU Application |
| Gemma 4 26B A4B | 256K | Nein | Model API oder GPU Application |
| Gemma 4 E4B | 128K | Ja | GPU Application |
| Gemma 4 E2B | 128K | Ja | GPU Application |
Gemma 4 auf Novita AI ausführen
Novita AI bietet zwei Möglichkeiten, Gemma 4 auszuführen, je nachdem, ob du eine verwaltete API oder volle Kontrolle über deine Instanz haben möchtest.
Model API: 31B und 26B A4B
Gemma 4 31B und Gemma 4 26B A4B sind über die Novita AI Model API verfügbar — OpenAI-kompatibel, Pay-per-Token und ohne monatliche Verpflichtung.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Es sind keine SDK-Änderungen erforderlich, wenn du bereits einen OpenAI-kompatiblen Client verwendest. Tausche einfach base_url und api_key aus, aktualisiere den Modell-String und schon läuft es.
GPU Application: Alle vier Größen
Alle vier Gemma 4-Modelle — E2B, E4B, 26B A4B und 31B — sind über die Novita AI GPU Application verfügbar. GPU Application ist eine Bibliothek vorkonfigurierter, einsatzbereiter Modellbereitstellungen: Wähle ein Modell, starte eine Instanz und es läuft mit einem Klick. Keine Infrastruktur-Einrichtung und keine manuelle Container-Konfiguration erforderlich.
Gemma 4 über GPU Application starten →
Fazit
Gemma 4 vereint drei unterschiedliche Architekturen in einer Modellfamilie: Ein 31B-Dense-Modell für Long-Context-Qualität, ein 26B A4B-MoE-Modell, das für speicherbegrenzte Ziele mit QAT-Unterstützung entwickelt wurde, sowie kleine E2B/E4B-Modelle, die speziell für On-Device-Inferenz konzipiert sind. Vision-Eingabe ist für alle vier Größen verfügbar, während Audio (ASR und AST) nur auf E2B und E4B unterstützt wird. Alle Größen verfügen über integrierte Funktionen wie Thinking, Funktionsaufruf, Mehrsprachigkeit und Videoverständnis.
Auf Novita AI sind das 31B und 26B A4B bereits über die Model API verfügbar — OpenAI-kompatibel und sofort einsatzbereit. Alle vier Größen, einschließlich der kleinen Modelle, sind über die GPU Application zur Ein-Klick-Bereitstellung verfügbar.
Jetzt Gemma 4 31B ausprobieren
Jetzt Gemma 4 26B A4B ausprobieren
Häufig gestellte Fragen
Was ist der Unterschied zwischen Gemma 4 31B und Gemma 4 26B A4B?
Das 31B ist ein Dense-Modell — alle 31,3B Parameter sind bei jedem Forward-Pass aktiv, optimiert für Long-Context-Qualität. Das 26B A4B ist ein Mixture of Experts-Modell mit insgesamt 26,8B Parametern, von denen jedoch nur 3,8B zur Inferenzzeit aktiv sind, entwickelt für speicherbegrenzte Bereitstellungen mit Quantisierungsunterstützung.
Unterstützen alle Gemma 4-Größen Vision und Audio?
Vision wird für alle vier Größen unterstützt. Audio wird nur auf E2B und E4B unterstützt — die 26B A4B und 31B akzeptieren Text- und Bildeingabe, aber kein Audio.
Welche Quantisierungsformate sind für Gemma 4 verfügbar?
Für die MoE-Variante (26B A4B) werden QAT-basierte Checkpoints bereitgestellt: Q3-2, Q3-0 und Q4-0.
Was ist die Novita AI GPU Application?
GPU Application ist ein One-Click-Modellbereitstellungsprodukt auf Novita AI. Wähle aus einer Bibliothek vorkonfigurierter, einsatzbereiter Modell-Apps — LLM, Bild, Audio und Video — ein Modell aus, starte eine Instanz und es läuft. Keine Container-Einrichtung oder Infrastruktur-Konfiguration erforderlich. Alle vier Gemma 4-Größen sind dort verfügbar.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu entwickeln, bereitzustellen und zu skalieren.



