

Le Gemma 4 de Google est désormais disponible sur Novita AI. Les deux plus grands modèles — 31B et 26B A4B — sont actifs sur la Model API. Les quatre tailles, y compris les modèles embarqués E2B et E4B, sont déployables via GPU Application : le produit de déploiement en un clic de Novita AI où vous choisissez un modèle, lancez une instance, et le tour est joué.
Cet article explique ce qu’est réellement Gemma 4, en quoi les architectures diffèrent et à quoi chaque taille est destinée — afin que vous puissiez choisir la bonne voie d’accès avant de commencer à construire.
Essayez Gemma 4 31B maintenant
Essayez Gemma 4 26B A4B maintenant
Qu’est-ce que Gemma 4 ?
Gemma 4 est la quatrième génération de la famille de modèles ouverts de Google, construite sur trois architectures différentes optimisées pour des cibles de mémoire et de performance variées. La gamme couvre tout, de l’inférence sur appareil aux déploiements de niveau serveur, chaque architecture étant conçue pour des empreintes mémoire et des objectifs de performance spécifiques.
Les quatre tailles de modèle sont :
| Modèle | Architecture | Paramètres | Contexte | Modalités |
|---|---|---|---|---|
| Gemma 4 E2B | Dense (petite) | 2,3B effectifs, 5,1B avec embeddings | 128K | Texte, Vision, Audio |
| Gemma 4 E4B | Dense (petite) | 4,5B effectifs, 7,9B avec embeddings | 128K | Texte, Vision, Audio |
| Gemma 4 26B A4B | MoE | 4B actifs / 26B total | 256K | Texte, Vision |
| Gemma 4 31B | Dense | 31B | 256K | Texte, Vision |
Les quatre tailles incluent des variantes ajustées par instruction (-it) en plus des checkpoints de pré-entraînement de base.
Comment fonctionnent les trois architectures
Architecture dense (31B) : conçue pour la qualité sur contexte long
Le modèle 31B est l’architecture dense phare. Il étend la base Gemma avec des modifications architecturales qui améliorent l’efficacité et la qualité sur contexte long.
Architecture MoE (26B A4B) : haute capacité, empreinte mémoire fixe
Le modèle 26B A4B utilise une conception Mixture of Experts (MoE) avec 128 experts au total — un nombre élevé de petits experts — plus un expert partagé unique toujours actif. Seuls 8 experts sont activés par passage avant, ce qui donne 3,8B paramètres actifs sur un total de 26,8B.
La conception vise des empreintes mémoire pouvant fonctionner sur des ordinateurs portables haut de gamme et des architectures serveur avec quantification appliquée. Des checkpoints d’entraînement sensible à la quantification (QAT) — Q3-2, Q3-0 et Q4-0 — sont fournis, permettant une inférence de haute qualité avec une empreinte mémoire réduite.
Petite architecture (E2B et E4B) : sur appareil avec un débit réel
Les modèles E2B et E4B sont spécialement conçus pour l’inférence sur appareil. La conception part de la base dense de Gemma 4 et ajoute des innovations sélectionnées de Gemma 3n pour augmenter les tokens par seconde, réduire le temps de préremplissage et élargir la compatibilité avec les appareils, frameworks et environnements d’exécution.
Deux caractéristiques clés sont reprises de Gemma 3n :
- Per-Layer Embeddings (PLE) : conservé de Gemma 3n
- KV-Cache Sharing : réduit à la fois le temps de préremplissage et la taille de la mémoire du cache KV avec un impact minimal sur la qualité
Capacités clés
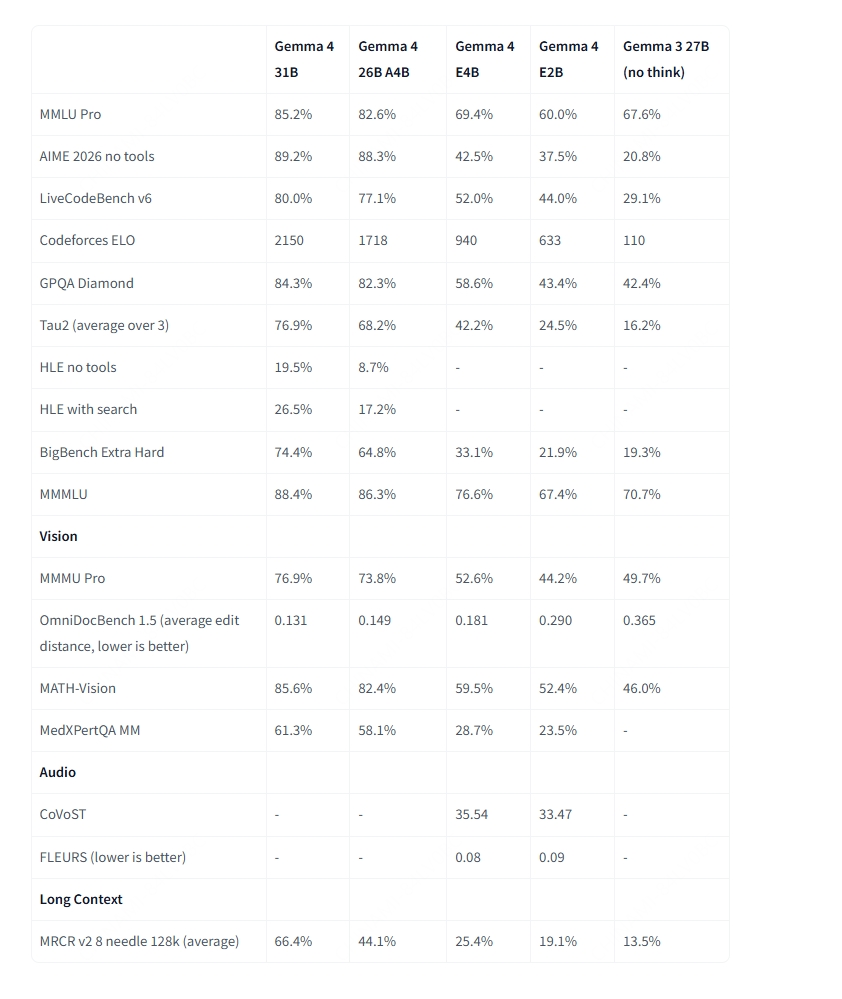
Au-delà des différences architecturales, toutes les tailles de Gemma 4 partagent un ensemble solide de capacités intégrées :
- Réflexion — Un mode de raisonnement intégré qui permet au modèle de réfléchir étape par étape avant de répondre.
- Contexte long — 128K tokens pour E2B et E4B, et 256K tokens pour 26B A4B et 31B.
- Compréhension d’images — Détection d’objets, analyse de documents et PDF, compréhension d’écran et d’interface utilisateur, compréhension de graphiques, OCR, reconnaissance d’écriture manuscrite et pointage.
- Compréhension vidéo — Analyse de vidéos en traitant des séquences d’images.
- Entrée multimodale entrelacée — Texte et images peuvent être librement mélangés dans une même invite.
- Appel de fonction — Prise en charge native des outils structurés et des flux de travail agentiques.
- Codage — Génération, complétion et correction de code.
- Multilingue — Prise en charge immédiate de plus de 35 langues, pré-entraîné sur plus de 140 langues.
- Audio (E2B et E4B uniquement) — Reconnaissance automatique de la parole (ASR) et synthèse vocale en texte traduit dans plusieurs langues.
Capacités multimodales : Vision et Audio
Vision : les quatre tailles, rapport hauteur/largeur natif
Les quatre tailles de Gemma 4 prennent en charge l’entrée visuelle. Les images sont traitées dans leur rapport hauteur/largeur natif en utilisant un traitement en résolution mixte — pas de recadrage panoramique ni de redimensionnement carré forcé.
Audio : E2B et E4B uniquement
L’entrée audio est prise en charge uniquement sur les petits modèles E2B et E4B. Les modèles 26B A4B et 31B ne prennent pas en charge l’audio.
Le modèle audio prend en charge :
- Automatic Speech Recognition (ASR) — Transcrit la parole en texte dans la langue source.
- Automatic Speech Translation (AST) — Transcrit la parole dans une langue source et traduit le résultat dans une langue cible.
Paramètres d’échantillonnage recommandés
Configuration d’échantillonnage standardisée de Google pour les cas d’utilisation de Gemma 4 :
| Paramètre | Valeur |
|---|---|
| temperature | 1,0 |
| top_p | 0,95 |
| top_k | 64 |
Utilisez ces paramètres comme configuration de base pour tous les cas d’utilisation de Gemma 4.
Comparaison des modèles
| Modèle | Contexte | Audio | Accès |
|---|---|---|---|
| Gemma 4 31B | 256K | Non | Model API ou GPU Application |
| Gemma 4 26B A4B | 256K | Non | Model API ou GPU Application |
| Gemma 4 E4B | 128K | Oui | GPU Application |
| Gemma 4 E2B | 128K | Oui | GPU Application |
Exécutez Gemma 4 sur Novita AI
Novita AI propose deux façons d’exécuter Gemma 4, selon que vous souhaitiez une API gérée ou un contrôle total sur votre instance.
Model API : 31B et 26B A4B
Gemma 4 31B et Gemma 4 26B A4B sont disponibles sur la Model API de Novita AI — compatible OpenAI, paiement par token, et sans engagement mensuel.
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "Vous êtes un assistant utile."},
{"role": "user", "content": "Bonjour, comment allez-vous ?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Aucun changement de SDK n’est nécessaire si vous utilisez déjà un client compatible OpenAI. Remplacez base_url et api_key, mettez à jour la chaîne du modèle, et c’est parti.
GPU Application : les quatre tailles
Les quatre modèles Gemma 4 — E2B, E4B, 26B A4B et 31B — sont disponibles via GPU Application de Novita AI. GPU Application est une bibliothèque de déploiements de modèles préconfigurés et prêts à l’emploi : choisissez un modèle, lancez une instance, et tout fonctionne en un clic. Pas de configuration d’infrastructure ni de configuration manuelle de conteneur.
Lancez Gemma 4 via GPU Application →
Conclusion
Gemma 4 rassemble trois architectures distinctes sous une même famille de modèles : un modèle dense 31B pour la qualité sur contexte long, un modèle MoE 26B A4B conçu pour des cibles mémoire contraintes avec prise en charge QAT, et des petits modèles E2B/E4B spécialement conçus pour l’inférence sur appareil. L’entrée visuelle est disponible sur les quatre tailles, tandis que l’audio (ASR et AST) est pris en charge uniquement sur E2B et E4B. Toutes les tailles sont livrées avec la réflexion, l’appel de fonction, le support multilingue et la compréhension vidéo intégrés.
Sur Novita AI, les modèles 31B et 26B A4B sont disponibles sur la Model API — compatible OpenAI et prêt à l’emploi. Les quatre tailles, y compris les petits modèles, sont disponibles via GPU Application pour un déploiement en un clic.
Essayez Gemma 4 31B maintenant
Essayez Gemma 4 26B A4B maintenant
Foire aux questions
Quelle est la différence entre Gemma 4 31B et Gemma 4 26B A4B ?
Le 31B est un modèle dense — les 31,3B paramètres sont actifs à chaque passage avant, optimisé pour la qualité sur contexte long. Le 26B A4B est un modèle Mixture of Experts avec 26,8B paramètres totaux mais seulement 3,8B actifs lors de l’inférence, conçu pour des déploiements à mémoire contrainte avec support de quantification.
Toutes les tailles de Gemma 4 prennent-elles en charge la vision et l’audio ?
La vision est prise en charge sur les quatre tailles. L’audio est pris en charge uniquement sur E2B et E4B — le 26B A4B et le 31B acceptent les entrées de texte et d’image mais pas l’audio.
Quels formats de quantification sont disponibles pour Gemma 4 ?
Des checkpoints basés sur QAT sont fournis pour la variante MoE (26B A4B) : Q3-2, Q3-0 et Q4-0.
Qu’est-ce que GPU Application de Novita AI ?
GPU Application est un produit de déploiement de modèles en un clic sur Novita AI. Choisissez parmi une bibliothèque d’applications de modèles préconfigurées et prêtes à l’emploi — LLM, image, audio et vidéo — sélectionnez un modèle, lancez une instance, et tout fonctionne. Aucune configuration de conteneur ou d’infrastructure requise. Les quatre tailles de Gemma 4 y sont disponibles.
Novita AI est une plateforme cloud IA et agent qui aide les développeurs et les startups à construire, déployer et passer à l’échelle des modèles et applications agentiques avec des performances élevées, fiabilité et efficacité des coûts.



