

El Gemma 4 de Google ya está disponible en Novita AI. Los dos modelos más grandes — 31B y 26B A4B — están activos en la API de Modelos. Los cuatro tamaños, incluyendo los E2B y E4B para dispositivos, se pueden implementar a través de GPU Application: el producto de implementación de modelos con un solo clic de Novita AI donde eliges un modelo, lanzas una instancia y ya está funcionando.
Este artículo cubre qué es realmente Gemma 4, en qué se diferencian las arquitecturas y para qué está diseñado cada tamaño, para que puedas elegir la ruta de acceso correcta antes de empezar a construir.
¿Qué es Gemma 4?
Gemma 4 es la familia de modelos abiertos de cuarta generación de Google, construida sobre tres arquitecturas diferentes optimizadas para distintos objetivos de memoria y rendimiento. La gama cubre desde inferencia en dispositivos hasta despliegues a nivel de servidor, con cada arquitectura diseñada en torno a objetivos específicos de huella de memoria y rendimiento.
Los cuatro tamaños de modelo son:
| Modelo | Arquitectura | Parámetros | Contexto | Modalidades |
|---|---|---|---|---|
| Gemma 4 E2B | Densa (pequeña) | 2.3B efectivos, 5.1B con embeddings | 128K | Texto, Visión, Audio |
| Gemma 4 E4B | Densa (pequeña) | 4.5B efectivos, 7.9B con embeddings | 128K | Texto, Visión, Audio |
| Gemma 4 26B A4B | MoE | 4B activos / 26B total | 256K | Texto, Visión |
| Gemma 4 31B | Densa | 31B | 256K | Texto, Visión |
Los cuatro tamaños incluyen variantes ajustadas con instrucciones (-it) junto con los puntos de control preentrenados base.
Cómo funcionan las tres arquitecturas
Arquitectura densa (31B): diseñada para calidad de contexto largo
El modelo 31B es la arquitectura densa insignia. Amplía la base de Gemma con cambios arquitectónicos que mejoran la eficiencia y la calidad en contextos largos.
Arquitectura MoE (26B A4B): alta capacidad, huella de memoria fija
El modelo 26B A4B utiliza un diseño de Mixture of Experts (MoE) con 128 expertos en total — una cantidad elevada de expertos pequeños — más un experto compartido único que siempre está activo. Solo se activan 8 expertos por paso forward, lo que da 3.8B parámetros activos de 26.8B total.
El diseño apunta a huellas de memoria que puedan ejecutarse en laptops de gama alta y arquitecturas de servidor con cuantización aplicada. Se proporcionan puntos de control con entrenamiento consciente de cuantización (QAT) — Q3-2, Q3-0 y Q4-0 — permitiendo inferencia de alta calidad con huellas de memoria reducidas.
Arquitectura pequeña (E2B y E4B): en dispositivo con rendimiento real
Los modelos E2B y E4B están diseñados específicamente para inferencia en dispositivo. El diseño parte de la base densa de Gemma 4 y añade innovaciones seleccionadas de Gemma 3n para aumentar los tokens por segundo, reducir el tiempo de prefill y ampliar la compatibilidad entre dispositivos, frameworks y runtimes.
Dos características clave provienen de Gemma 3n:
- Per-Layer Embeddings (PLE): mantenido de Gemma 3n
- KV-Cache Sharing: reduce tanto el tiempo de prefill como el tamaño de memoria del KV-cache con un impacto mínimo en la calidad
Capacidades clave
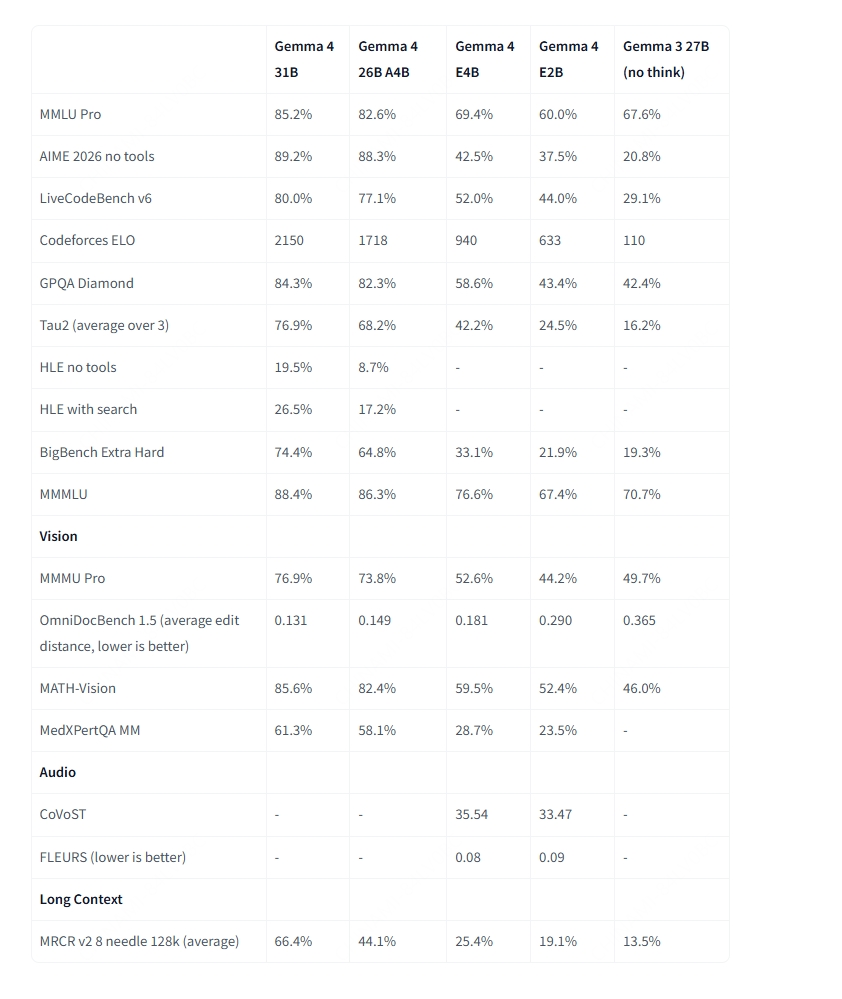
Más allá de las diferencias arquitectónicas, todos los tamaños de Gemma 4 comparten un conjunto sólido de capacidades integradas:
- Pensamiento — Un modo de razonamiento incorporado que permite al modelo pensar paso a paso antes de responder.
- Contexto largo — 128K tokens para E2B y E4B, y 256K tokens para 26B A4B y 31B.
- Comprensión de imágenes — Detección de objetos, análisis de documentos y PDF, comprensión de pantallas e interfaces de usuario, comprensión de gráficos, OCR, reconocimiento de escritura a mano y señalización.
- Comprensión de video — Analiza video procesando secuencias de fotogramas.
- Entrada multimodal intercalada — Texto e imágenes se pueden mezclar libremente en una sola instrucción.
- Llamada a funciones — Soporte nativo para uso estructurado de herramientas y flujos de trabajo agentivos.
- Codificación — Generación, completado y corrección de código.
- Multilingüe — Soporte inmediato para más de 35 idiomas, preentrenado en más de 140 idiomas.
- Audio (solo E2B y E4B) — Reconocimiento automático del habla (ASR) y conversión de voz a texto traducido en múltiples idiomas.
Capacidades multimodales: Visión y Audio
Visión: los cuatro tamaños, relación de aspecto nativa
Los cuatro tamaños de Gemma 4 admiten entrada de visión. Las imágenes se procesan en su relación de aspecto nativa utilizando procesamiento de resolución mixta — sin recorte panorámico ni redimensionamiento forzado a cuadrado.
Audio: solo E2B y E4B
La entrada de audio es compatible únicamente en los modelos pequeños E2B y E4B. El 26B A4B y el 31B no admiten audio.
El modelo de audio admite:
- Reconocimiento automático del habla (ASR) — Transcribe el habla a texto en el idioma de origen.
- Traducción automática del habla (AST) — Transcribe el habla en un idioma de origen y traduce la salida a un idioma de destino.
Parámetros de muestreo recomendados
Configuración de muestreo estandarizada por Google para casos de uso de Gemma 4:
| Parámetro | Valor |
|---|---|
| temperature | 1.0 |
| top_p | 0.95 |
| top_k | 64 |
Usa estos valores como configuración de muestreo base para casos de uso de Gemma 4.
Comparación de modelos
| Modelo | Contexto | Audio | Acceso |
|---|---|---|---|
| Gemma 4 31B | 256K | No | API de Modelos o GPU Application |
| Gemma 4 26B A4B | 256K | No | API de Modelos o GPU Application |
| Gemma 4 E4B | 128K | Sí | GPU Application |
| Gemma 4 E2B | 128K | Sí | GPU Application |
Ejecuta Gemma 4 en Novita AI
Novita AI ofrece dos formas de ejecutar Gemma 4, dependiendo de si prefieres una API gestionada o control total sobre tu instancia.
API de Modelos: 31B y 26B A4B
Gemma 4 31B y Gemma 4 26B A4B están disponibles en la API de Modelos de Novita AI — compatible con OpenAI, pago por token y sin compromiso mensual.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
No se necesitan cambios en el SDK si ya estás usando un cliente compatible con OpenAI. Cambia base_url y api_key, actualiza la cadena del modelo, y ya está funcionando.
GPU Application: los cuatro tamaños
Los cuatro modelos de Gemma 4 — E2B, E4B, 26B A4B y 31B — están disponibles a través de GPU Application de Novita AI. GPU Application es una biblioteca de despliegues de modelos preconfigurados y listos para ejecutar: elige un modelo, lanza una instancia y se ejecuta con un solo clic. Sin configuración de infraestructura ni configuración manual de contenedores.
Lanza Gemma 4 mediante GPU Application →
Conclusión
Gemma 4 reúne tres arquitecturas distintas en una sola familia de modelos: un modelo denso de 31B para calidad en contextos largos, un modelo MoE de 26B A4B diseñado para objetivos de memoria restringida con soporte QAT, y modelos pequeños E2B/E4B diseñados específicamente para inferencia en dispositivo. La entrada de visión está disponible en los cuatro tamaños, mientras que el audio (ASR y AST) solo es compatible con E2B y E4B. Todos los tamaños incluyen pensamiento, llamada a funciones, soporte multilingüe y comprensión de video integrados.
En Novita AI, los modelos 31B y 26B A4B están activos en la API de Modelos — compatible con OpenAI y listos para usar. Los cuatro tamaños, incluidos los modelos pequeños, están disponibles a través de GPU Application para un despliegue con un solo clic.
Preguntas frecuentes
¿Cuál es la diferencia entre Gemma 4 31B y Gemma 4 26B A4B?
El 31B es un modelo denso: los 31.3B parámetros están activos en cada paso forward, optimizado para calidad en contextos largos. El 26B A4B es un modelo de Mixture of Experts con 26.8B parámetros totales pero solo 3.8B activos en tiempo de inferencia, diseñado para despliegues con memoria restringida y soporte de cuantización.
¿Todos los tamaños de Gemma 4 admiten visión y audio?
La visión es compatible en los cuatro tamaños. El audio solo es compatible en E2B y E4B — el 26B A4B y el 31B aceptan entrada de texto e imágenes, pero no de audio.
¿Qué formatos de cuantización están disponibles para Gemma 4?
Se proporcionan puntos de control basados en QAT para la variante MoE (26B A4B): Q3-2, Q3-0 y Q4-0.
¿Qué es GPU Application de Novita AI?
GPU Application es un producto de implementación de modelos con un solo clic en Novita AI. Elige entre una biblioteca de aplicaciones de modelo preconfiguradas y listas para ejecutar — LLM, imagen, audio y video — selecciona un modelo, lanza una instancia y ya está funcionando. Sin configuración de contenedores ni infraestructura. Los cuatro tamaños de Gemma 4 están disponibles allí.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, implementar y escalar modelos y aplicaciones agentivas con alto rendimiento, fiabilidad y eficiencia de costos.



