

开发人员真的能在本地部署 Qwen3.5-397B-A17B 吗?简短回答:在消费级硬件上以全精度运行是不可能的。这个拥有 4034 亿参数的巨大多模态 MoE 模型在 BF16 精度下需要 793GB VRAM,使其稳稳落在企业级集群领域。对于大多数开发者来说,Novita Severless API 是实用的替代方案——无需硬件设置。
快速解答:完整 BF16 需要 10×H100 GPU(在 Novita AI 上每小时 25.9 美元)。实际部署建议使用 4 位量化在 2×H100 80GB 上运行。如果你正在构建生产应用,请从 Novita AI 的 API 开始,每百万 token 收费 0.60/3.60 美元。

Qwen3.5-397B-A17B 的 VRAM 需求
| 精度 | 所需 VRAM/RAM |
|---|---|
| BF16(完整) | 793GB |
| Q8_0 | 422 GB |
| Q4_K_S | 228 GB |
| Q3_K_S | 164 GB |
Qwen3.5-397B-A17B 推荐的 GPU 配置
| 配置 | 精度 | 成本(Novita AI) | 最适合 |
|---|---|---|---|
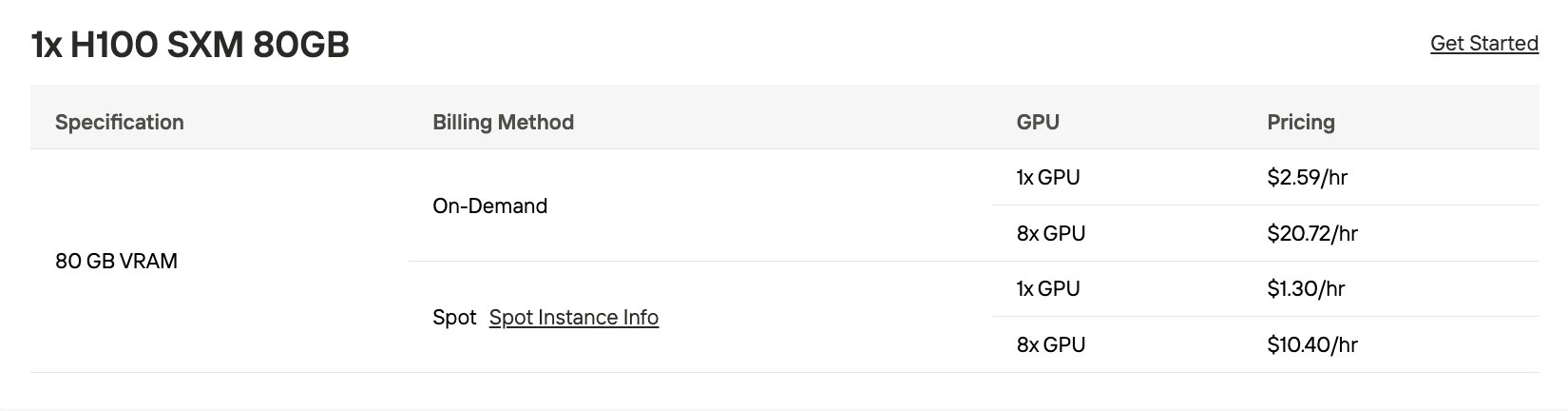
| 10×H100 SXM 80GB | BF16 | 按需 25.9 美元/小时,竞价 13 美元/小时 | 高吞吐量生产(每天 1M+ token) |
| 6×H100 SXM 80GB | Q8_0 | 按需 15.54 美元/小时,竞价 7.8 美元/小时 | 中等规模应用(每天 10 万-50 万 token) |
多 GPU 设置要求
多 GPU 部署必须使用张量并行。除了原始 VRAM 之外,你还需要以下内容:
- NVLink/NVSwitch: 在 H100/A100 设置中实现高效的跨 GPU 通信是必需的。仅使用 PCIe 的配置无论 GPU 数量多少,都会受限于每秒 15-20 token 的瓶颈。
- vLLM 或 TGI: 使用 vLLM 的张量并行(
--tp 8)或 Hugging Face Text Generation Inference 实现自动模型分片。 - 处理超长文本: Qwen3.5 原生支持最大 262,144 token 的上下文长度。对于总长度(包括输入和输出)超过此限制的长时任务,我们建议使用 RoPE 缩放技术来有效处理长文本,例如 YaRN。YaRN 目前被多种推理框架支持,如 transformers、vllm 和 sglang。您可以通过修改
config.json中的rope_parameters字段来启用它:{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144} - 至少 512GB 系统内存: 用于模型加载、KV 缓存和多模态预处理(图像/视频 tokenization)。
Qwen3.5-397B-A17B 部署指南
第 1 步:注册账户
通过我们的网站创建您的 Novita AI 账户。注册后,导航到左侧边栏的“探索”部分,查看我们的 GPU 产品 并开始您的 AI 开发之旅。

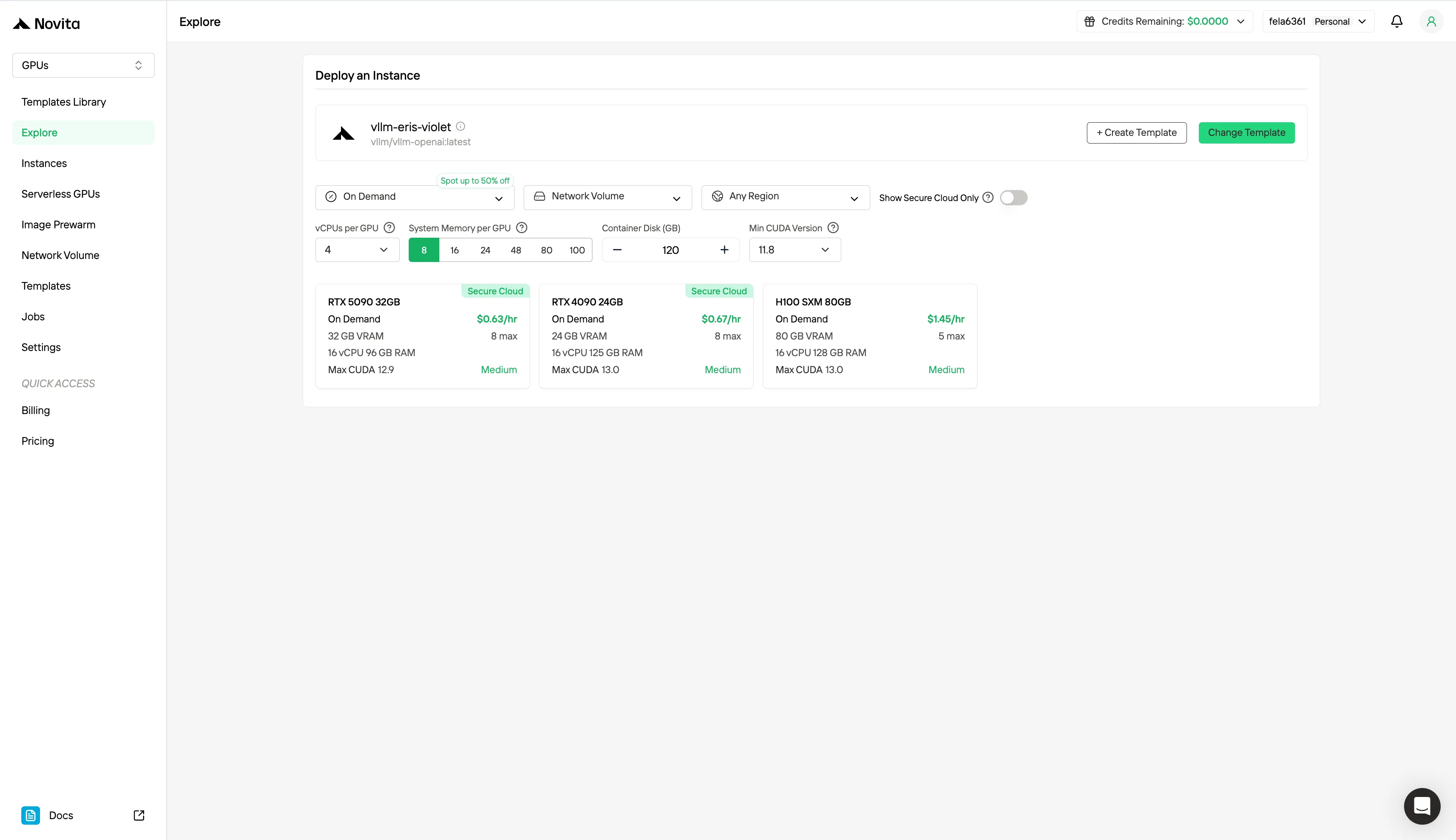
第 2 步:探索模板和 GPU 服务器
从 PyTorch、TensorFlow 或 CUDA 等模板中选择适合您项目需求的模板。然后选择您首选的 GPU 配置——选项包括强大的 GPU,每个配置具有不同的 VRAM、RAM 和存储规格。
第 3 步:定制您的部署
通过选择首选操作系统和配置选项来定制您的环境,确保针对您的特定 AI 工作负载和开发需求获得最佳性能。
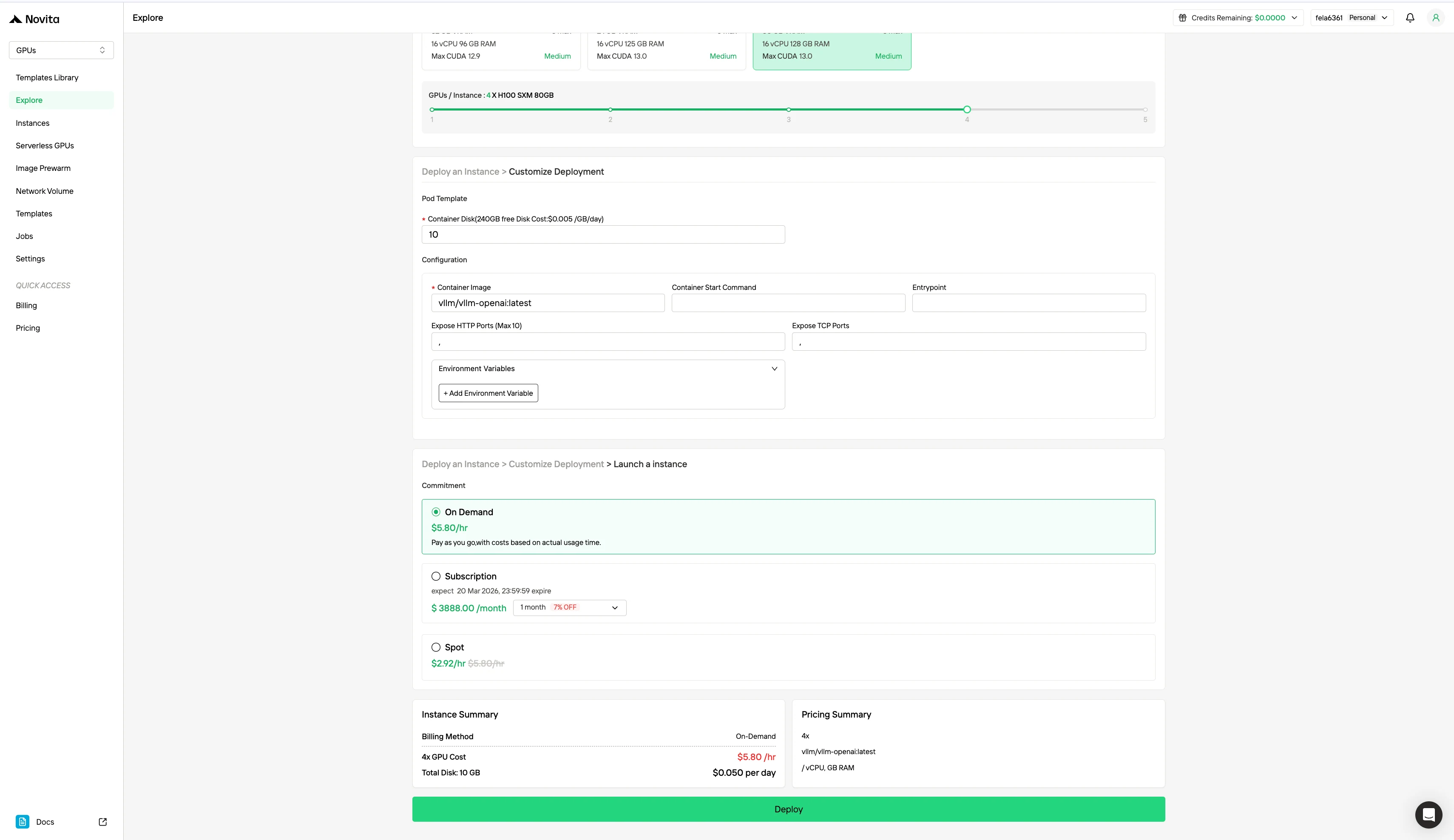
除了标准的按需定价模式外,Novita AI 还提供 Spot 模式,这是一种专为成本敏感型工作负载设计的显著更便宜的 GPU 选项。与为稳定、连续使用预留专用硬件的按需实例不同,Spot 实例是可中断的——如果 GPU 被系统回收,您的任务可能会被暂停或终止。由于 Spot 模式重新分配原本未使用的 GPU 资源,其价格通常比按需定价低 40-60%。
常见部署陷阱
1. 上下文长度溢出
问题: 原生的 262k 上下文对于长篇文档 RAG 或视频分析通常不足。超出会导致质量下降。
解决方案: 启用 YaRN RoPE 缩放以扩展到 1M+ token:
YaRN 目前被多种推理框架支持,例如 transformers、vllm、ktransformers 和 sglang。通常,有两种方法可以在受支持的框架上启用 YaRN:
- 修改模型配置文件:在
config.json文件中,更改text_config中的rope_parameters字段为:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}
- 传递命令行参数:
对于 vllm,您可以使用:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000
对于 sglang 和 ktransformers,您可以使用:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 1010000
2. 量化陷阱
问题: 3 位 GGUF 可能会损失多模态保真度——视觉-语言任务会明显退化。
解决方案: 使用 INT4 GPTQ/AWQ 以获得更好的平衡。在部署前,务必在量化后运行视觉基准测试。
3. NVLink 瓶颈
问题: 没有 NVLink 的多 GPU 设置会达到 PCIe 带宽限制(每秒 15-20 token 上限)。
解决方案: 使用带 NVSwitch 的 H100/A100 可获得 45+ token/秒的吞吐量。避免在生产多 GPU 设置中使用消费级 GPU。
如果你想在本地运行 Qwen3.5-397B-A17B: 10×H100 80GB 带 NVLink(按需 25.9 美元/小时)
如果太贵: 使用 Novita AI 的 API,每百万 token 仅需 0.60/3.60 美元,零运维开销。
结论
在本地运行 Qwen3.5-397B-A17B 在技术上是可行的,但硬件门槛极高——BF16 下 793GB VRAM 使其牢牢属于企业级集群。对于大多数开发者和团队来说,Novita AI API 以极低的成本提供同样的前沿性能,且无需基础设施开销。无论你是在构建智能体管道、运行大规模推理,还是仅仅探索模型的能力,API 路径都能让你更快到达目标。
常见问题解答
我能在单个 RTX 4090 上运行 Qwen3.5-397B-A17B 吗?
不能。即使使用 3 位量化,模型也需要 165GB+ VRAM——RTX 4090 的 24GB 差了一个数量级。
生产部署的最低 GPU 配置是什么?
10×H100 80GB BF16 可实现完整保真度,或 6×H100 INT8 用于成本优化的生产环境。更小的配置可能会在多模态任务上导致吞吐量瓶颈或质量下降。
运行 Qwen3.5-397B-A17B 处理 100 万个 token 需要多少成本?
Novita AI API:每百万 token 4.20 美元(混合输入+输出)。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



