

Разработчики, оценивающие графические процессоры нового поколения, часто сталкиваются с трудностями при определении того, обеспечивает ли RTX 5090 значительные преимущества над RTX 4090 при выполнении реальных рабочих нагрузок ИИ, с учетом ограничений инфраструктуры и стоимости.
В этой статье мы развеем эту неопределенность, рассмотрев три ключевых аспекта: (1) прирост производительности при инференсе LLM, генерации изображений и мультимодальной генерации, обеспечиваемый архитектурой Blackwell, ускорением FP8 и 32 ГБ видеопамяти; (2) требования к обновлению платформы, необходимые для безопасной и стабильной работы с RTX 5090; (3) категории разработчиков, которые получат наибольшую выгоду от обновления, и те, для кого 4090 или облачный GPU будет более рентабельным.
Анализ также рассматривает RTX 5090 в контексте практических путей развертывания, оценивая поддержку Linux и Windows и выделяя модель низкостоимостного доступа Novita AI. Вместе эти аспекты предоставляют разработчикам четкую, основанную на доказательствах основу для принятия решения о том, когда инвестиции в RTX 5090 являются оправданными.
Novita AI запускает кампанию «Месяц разработки», предлагая разработчикам эксклюзивную скидку до 20% на все основные продукты!
Участвуйте в «Месяце разработки»!
Насколько RTX 5090 действительно ускоряет рабочие нагрузки ИИ?
RTX 5090 обеспечивает примерно на 50% более быстрый инференс LLM по сравнению с RTX 4090 для моделей 7B–13B, а ускорение FP8/FP16 позволяет достигать скорости до 3k токенов/с в vLLM для phi-4.
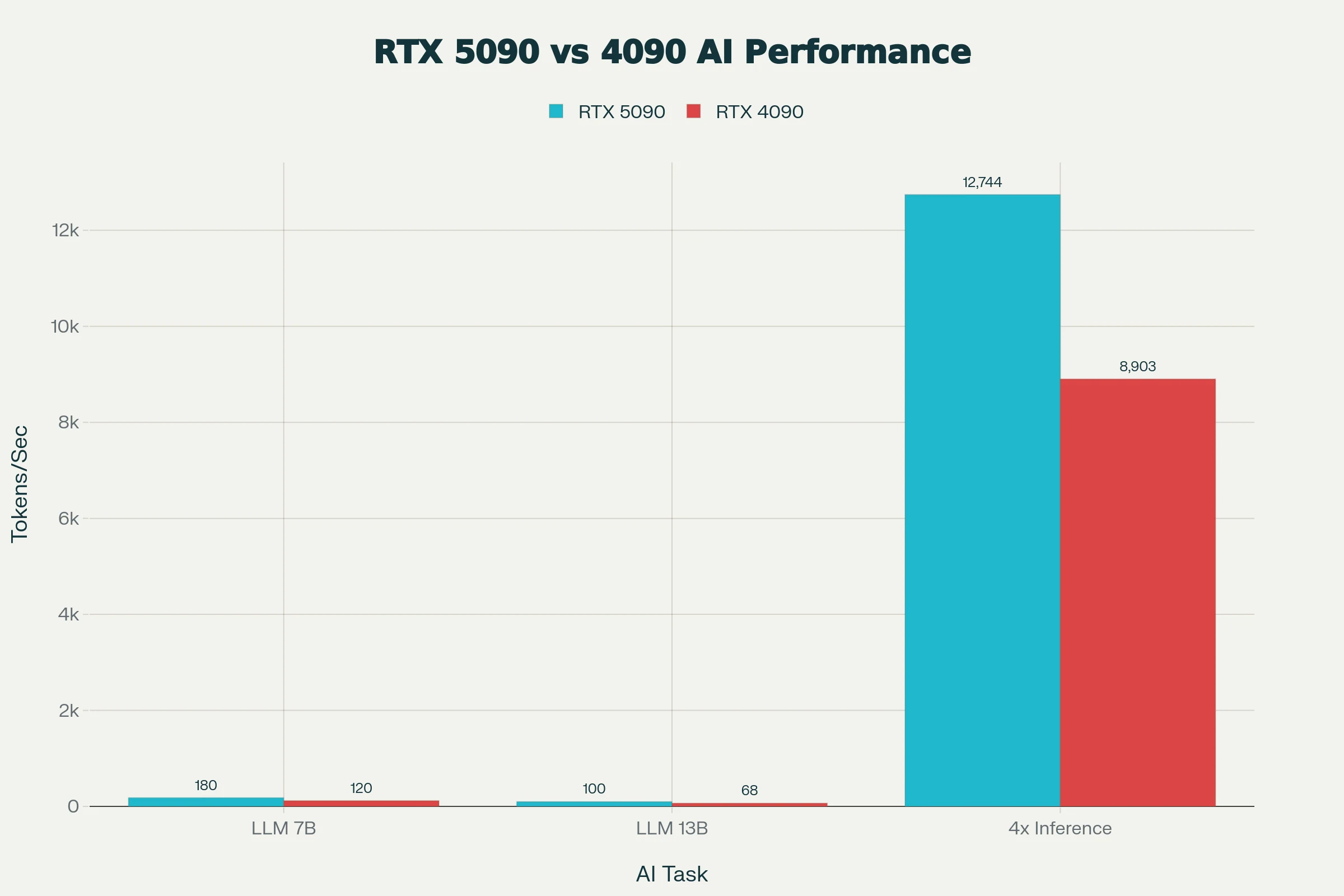
Из AIGPUValue
Является ли 32 ГБ видеопамяти прорывом?
Его 32 ГБ видеопамяти позволяют полностью загружать квантованные LLM объемом 49Б, что является качественным скачком по сравнению с 24 ГБ у 4090 для более крупных моделей генерации изображений или 70Б Q4 моделей при практических скоростях работы.
| Спецификация | RTX 5090 | RTX 4090 |
|---|---|---|
| Архитектура | Blackwell | Ada Lovelace |
| Объем видеопамяти | 32 ГБ GDDR7 | 24 ГБ GDDR6X |
| Пропускная способность памяти | 1 792 ГБ/с | 1 008 ГБ/с |
| Ядра CUDA | 21 760 | 16 384 |
| Тензорные ядра | 680 | 512 |
| TDP | 575 Вт | 450 Вт |
| Рекомендуемая розничная цена | $1 999 | $1 599 |
Что обеспечивает 32 ГБ:
- Запуск 70Б LLM с агрессивным квантованием
- Рабочие процессы генерации видео в высоком разрешении (4K–8K) с помощью диффузионных моделей
- Среднемасштабное обучение моделей без использования градиентного чекпоинтинга
| GPU | Изображений в минуту | Прирост |
|---|---|---|
| RTX 5090 | 35 | +59% |
| RTX 4090 | 22 | базовый уровень |
Что это пока не позволяет:
- Обучение 70Б моделей в полной точности
- Многомодельная генерация видео в высоком разрешении в течение нескольких часов без теплового троттлинга
Что необходимо обновить разработчикам для безопасной работы с 5090?
RTX 5090 не является заменой «в лоб»: его тепловыделение 575 Вт и интерфейс PCIe 5.0 требуют обновления платформы, а не простой замены компонентов. Стабильные длительные рабочие нагрузки ИИ обычно требуют блока питания большей мощности, усиленных систем охлаждения, корпуса, оптимизированного для воздушного потока и структурной поддержки, а также достаточной пропускной способности пути данных. В карте также отсутствует NVLink, поэтому вся коммуникация между несколькими GPU осуществляется исключительно через PCIe, что ограничивает эффективность масштабирования при обучении и усугубляет тепловое накопление в многографических конфигурациях.
Оборудование, которое необходимо обновить
- Блок питания 1000–1200 Вт (ATX 3.1 / PCIe 5.1, разъем 12V-2x6)
- Система охлаждения высокой мощности (большие воздушные кулеры или жидкостное охлаждение)
- Корпус с усиленными слотами PCIe и эффективной циркуляцией воздуха
- Первичный слот PCIe 5.0 ×16 на материнской плате
- 64–128 ГБ оперативной памяти DDR5 для рабочих нагрузок LLM с выгрузкой в оперативную память
- SSD NVMe Gen4/Gen5 для хранения моделей
1. Требования к системе питания
Рекомендуется использовать блок питания мощностью 1000–1200 Вт, чтобы обеспечить стабильную работу при длительных высоких нагрузках и пиковых скачках потребления. Классы эффективности 80+ Gold или Platinum помогают снизить выделение тепла и долгосрочные эксплуатационные расходы. Разъем 12V-2x6 должен быть установлен с защитой от натяжения, поскольку перегрев разъема и механические нагрузки являются распространенными проблемами, особенно при вертикальном монтаже GPU.

2. Интеграция охлаждения и корпуса
Для 5090 требуется либо большой двух- или трехслотовый кулер, либо жидкостное охлаждение. Тепловая плотность резко возрастает в конфигурациях с несколькими GPU, поэтому потребительские настольные корпуса часто оказываются недостаточными. Предпочтительны корпуса с сетчатыми панелями, усиленными слотами для GPU и эффективными путями циркуляции воздуха. Для массивов из 2× или 4× 5090 рекомендуется использовать серверные корпуса или корпуса для рабочих станций.

3. Требования к хранилищу
Высокоскоростные SSD NVMe (Gen4/Gen5, класс ~7 ГБ/с) ускоряют начальную загрузку моделей и перемешивание наборов данных. Скорость хранилища не влияет на количество токенов в секунду, но значительно улучшает отзывчивость рабочего процесса при повторной загрузке моделей.

Готовы ли фреймворки к работе с 5090?
1. Если ваша цель — разработка ИИ, обучение моделей или инференс крупных моделей, используйте Linux
- Самые быстрые и стабильные релизы драйверов CUDA
- Лучшая совместимость с PyTorch / TensorFlow / JAX / vLLM / TensorRT-LLM
- Оптимизации для FP8, BF16 и архитектуры Blackwell появляются на Linux первыми
- Поддержка ROCm и oneAPI также наиболее развита на Linux
- Масштабирование на нескольких GPU, управление линиями PCIe и альтернативы NVLink работают более надежно
2. Если ваша цель — обычная настольная работа + инференс ИИ + удобство, используйте Windows 11
- Самая простая установка (драйверы, приложения, пользовательский интерфейс)
- Сильная нативная поддержка CUDA
- Сторонние графические интерфейсы (LM Studio, ComfyUI, A1111, сборка Ollama для Windows) работают стабильно
- Идеально подходит для пользователей, не занимающихся исследовательской разработкой
Ограничения по сравнению с Linux:
- Обновления для TensorRT-LLM, оптимизации FP8 и продвинутые ядра выходят позже
- Конфигурации с несколькими GPU менее стабильны из-за различий в драйверах
- Более низкая производительность в крайних случаях (узкие места ввода-вывода, насыщение PCIe)
|Ваш вариант использования|Лучшая система|Почему|—|—|—| |Крупные LLM (30Б–70Б), конвейеры FP8, обучение, vLLM|Linux|Самый быстрый CUDA, лучшая стабильность, приоритет в экосистеме| |Инференс на одном GPU, Stable Diffusion, инструменты с GUI|Windows|Самый простой, широкая поддержка GUI| |Смешанный рабочий процесс (программирование + периодические тяжелые задачи ИИ)|Windows + WSL2|Удобство + приемлемая производительность| |Многографическая рабочая станция (2× или 4× 5090)|Linux|Стабильность драйверов и управление PCIe|
Какие разработчики получат наибольшую выгоду от 5090?
|Категория|Стоит ли покупать RTX 5090?|Ключевая причина|—|—|—| |Генерация видео / мультимодальная генерация|Однозначно да|FP8 + пропускная способность = огромный прирост| |Диффузионные модели (SDXL, Flux)|Однозначно да|Высокое разрешение + масштабирование пакетов| |Среднемасштабное обучение (≤20Б)|Однозначно да|Более быстрая итерация, возможность обучения на одном GPU| |Корпоративный инференс на локальном оборудовании|Однозначно да|Больше инстансов, более высокая пропускная способность| |Инференс квантованных LLM только|Вероятно, нет|Незначительное преимущество по сравнению с 4090| |Пользователи с ограниченным бюджетом|Вероятно, нет|4090 / облачные решения дают лучшую рентабельность инвестиций| |Пользователи, занимающиеся обучением на нескольких GPU|Вероятно, нет|Требуется память + интерконнект, а не сырая мощность одной карты|
Как использовать RTX 5090 по очень низкой цене?
Novita AI предоставляет облачную платформу с высокопроизводительными GPU-инстансами. Мощные GPU обеспечивают эффективную производительность для сложных задач, повышают доступность для развертывания на различном оборудовании и предлагают рентабельное решение по сравнению с обслуживанием локального оборудования для крупномасштабных развертываний ИИ.
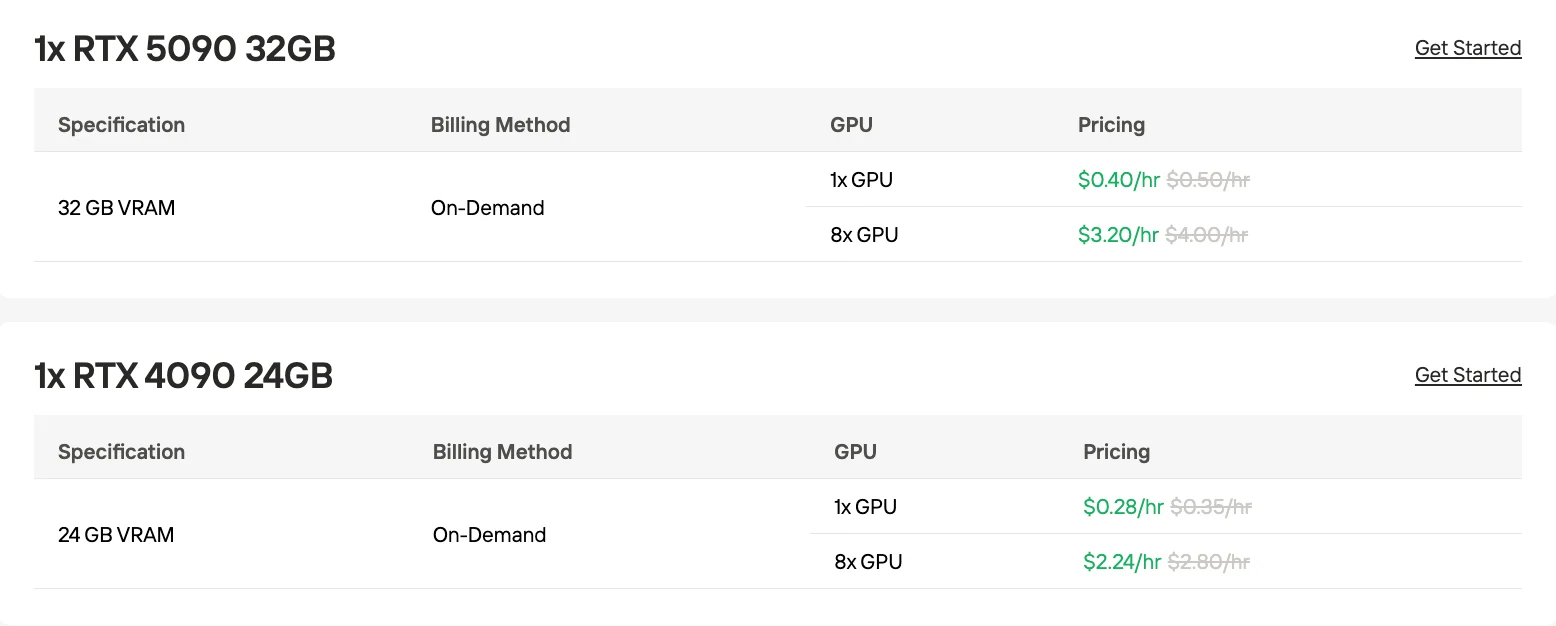
1x RTX 4090 GPU: $0.28/час
8x RTX 4090 GPU: $2.24/час
1x RTX 4090 GPU: $0.40/час
8x RTX 4090 GPU: $3.20/час
Novita AI запускает кампанию «Месяц разработки», предлагая разработчикам эксклюзивную скидку до 20% на все основные продукты!
Участвуйте в «Месяце разработки»!
Шаг 1: Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел «Обзор» в левой боковой панели, чтобы ознакомиться с нашими предложениями GPU и начать свой путь в разработке ИИ.

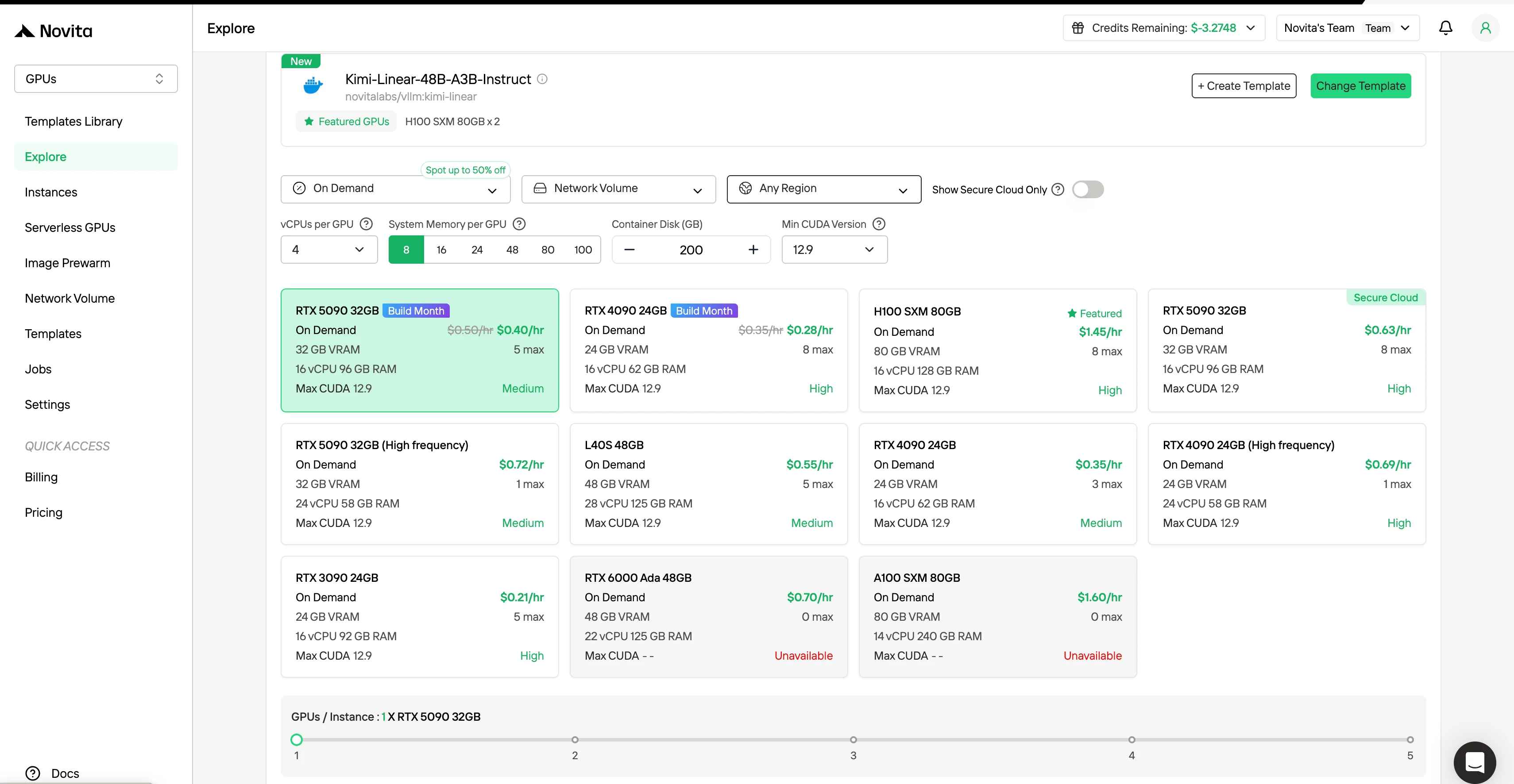
Шаг 2: Изучите шаблоны и GPU-серверы**
Выберите подходящие для вашего проекта шаблоны, такие как PyTorch, TensorFlow или CUDA. Затем выберите предпочитаемую конфигурацию GPU — доступны мощные L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками объемов видеопамяти, оперативной памяти и хранилища.
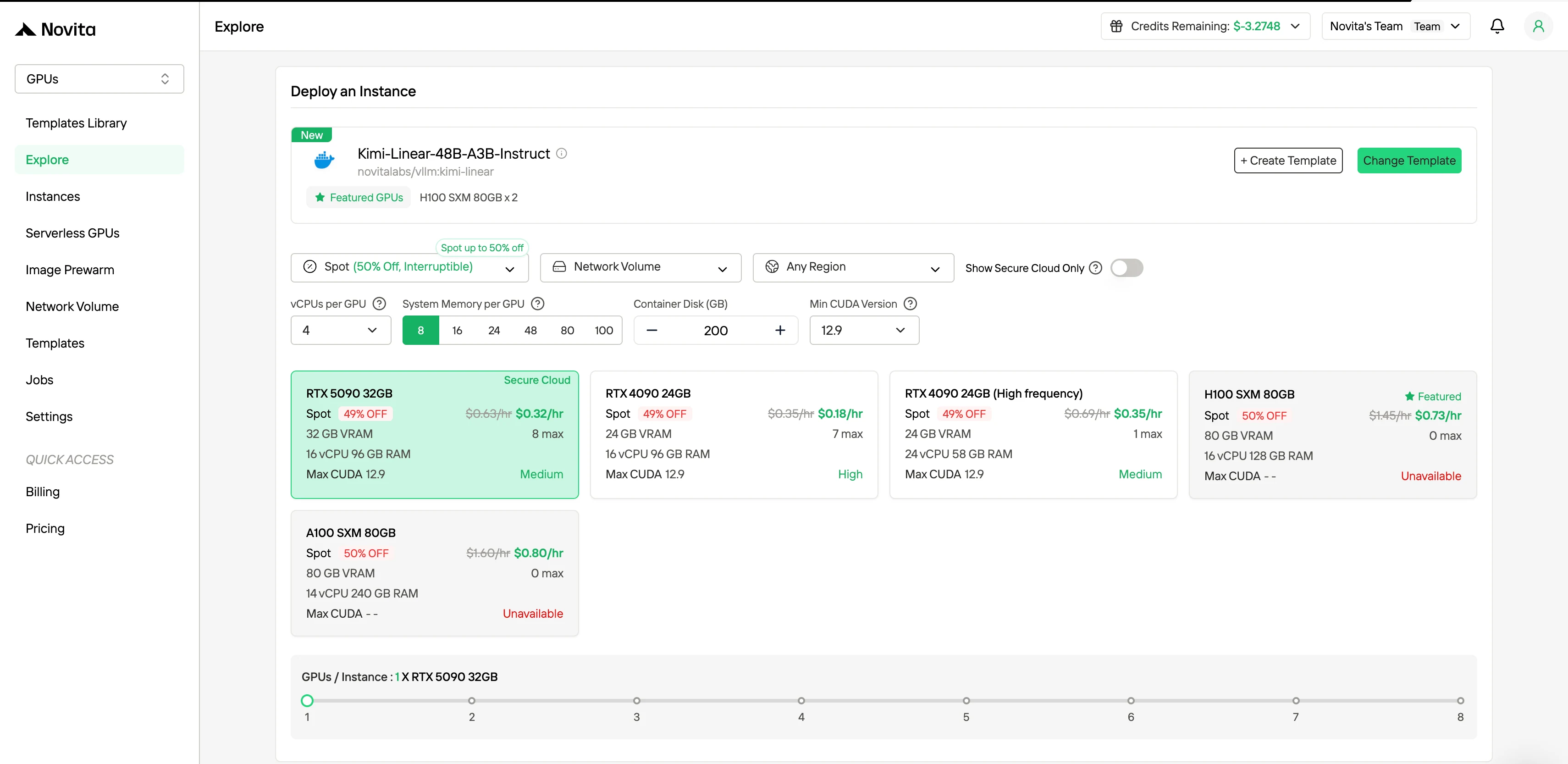
В правой боковой панели в разделе «Фильтр» вы можете изменить метод оплаты с «По требованию» на «Spot», чтобы увидеть цены со скидкой. Интерфейс сразу обновляется, чтобы четко показать экономию в 50%. Эта прозрачность гарантирует, что вы точно знаете, сколько будет стоить развертывание, перед его запуском.
Spot-инстансы поддерживают:
- Гарантированный период защиты 1 час
- Активация экономии до 50%
- Настроенное уведомление о прерывании за 1 час заранее
- Предустановленные фреймворки ИИ готовы к использованию
Шаг 3: Настройте развертывание и запустите инстанс
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей разработки. После этого ваше высокопроизводительное GPU-окружение будет готово в течение нескольких минут, и вы сможете сразу начать работу над проектами машинного обучения, рендеринга или вычислительными проектами.
RTX 5090 представляет собой существенный архитектурный шаг вперед, обеспечивая более высокую пропускную способность FP8, значительно более высокую пропускную способность памяти и практический скачок до 32 ГБ видеопамяти, который открывает доступ к более крупным квантованным LLM, рабочим процессам генерации изображений в высоком разрешении и среднемасштабному обучению. Однако его преимущества зависят от соответствующих обновлений системы питания, охлаждения, поддержки корпусом и пропускной способности PCIe 5.0. Для разработчиков, занимающихся генерацией видео и мультимодальной генерацией, диффузионными моделями SDXL/Flux или исследовательским обучением на одном GPU, 5090 предлагает явную и немедленную ценность. Для пользователей, для которых приоритетом является инференс квантованных LLM, масштабирование на нескольких GPU или строгая экономическая эффективность, более подходящим вариантом останется RTX 4090 или облачное развертывание. С предложением Novita AI дисконтных облачных инстансов разработчики могут оценить производительность RTX 5090 без крупных первоначальных инвестиций.
Часто задаваемые вопросы
Насколько быстрее RTX 5090 по сравнению с RTX 4090 в реальных рабочих нагрузках?
RTX 5090 обеспечивает примерно на 50% более быстрый инференс LLM по сравнению с RTX 4090 для моделей 7Б–13Б и достигает скорости до ~3k токенов/с в vLLM для phi-4 при использовании ускорения FP8/FP16.
Изменяет ли 32 ГБ видеопамяти на RTX 5090 набор моделей, которые могут запускать разработчики?
Да. RTX 5090 может загружать LLM объемом 49Б и даже 70Б Q4 на рабочих скоростях, тогда как RTX 4090 ограничен своим объемом видеопамяти 24 ГБ для этих рабочих нагрузок.
Какие рабочие нагрузки получают наибольшую выгоду от RTX 5090?
Генерация видео/мультимодальная генерация, диффузионные модели SDXL/Flux, среднемасштабное обучение моделей ≤20Б и корпоративный инференс на локальном оборудовании демонстрируют значительный прирост производительности на RTX 5090 по сравнению с RTX 4090.
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развертывания моделей ИИ с использованием нашего простого API, а также доступное и надежное облако GPU для создания и масштабирования решений.
Рекомендуемые материалы для чтения



