

يواجه المطورون الذين يقيمون وحدات معالجة الرسومات من الجيل التالي صعوبة في تحديد ما إذا كان RTX 5090 يقدم مزايا ذات معنى مقارنة بـ RTX 4090 عبر أحمال عمل الذكاء الاصطناعي الفعلية، وقيود البنية التحتية، والتكلفة.
يتناول هذا المقال هذا الغموض من خلال فحص ثلاثة أبعاد أساسية: (1) مكاسب الأداء في استدلال LLM، والتوليد الانتشاري، والتوليد متعدد الوسائط التي تمكّنها بنية Blackwell، وتسريع FP8، وذاكرة VRAM سعة 32 جيجابايت؛ (2) متطلبات الترقية على مستوى المنصة المطلوبة لتشغيل RTX 5090 بشكل آمن وموثوق؛ (3) ملفات المطورين الذين يستفيدون أكثر من الترقية مقابل أولئك الذين يكون خيار 4090 أو وحدة معالجة الرسومات السحابية أكثر فعالية من حيث التكلفة بالنسبة لهم.
يضع التحليل RTX 5090 في سياق مسارات النشر العملية من خلال تقييم دعم لينكس مقابل ويندوز وتسليط الضوء على نموذج الوصول منخفض التكلفة لـ Novita AI. معًا، توفر هذه الأبعاد للمطورين إطارًا واضحًا قائمًا على الأدلة لاتخاذ قرار متى يكون الاستثمار في RTX 5090 هو الخيار الصحيح.
تقوم Novita AI بإطلاق حملة “شهر البناء” الخاصة بها، حيث تقدم للمطورين حافزًا حصريًا يصل إلى خصم 20% على جميع المنتجات الرئيسية!
ما مقدار التحسن الفعلي الذي يقدمه RTX 5090 لأحمال عمل الذكاء الاصطناعي؟
يقدم RTX 5090 سرعة استدلال LLM تزيد بنسبة 50% تقريبًا مقارنة بـ RTX 4090 في نماذج 7B-13B، مع تسريع FP8/FP16 يتيح سرعة تصل إلى 3 آلاف رمز/ثانية في vLLM لنموذج phi-4.
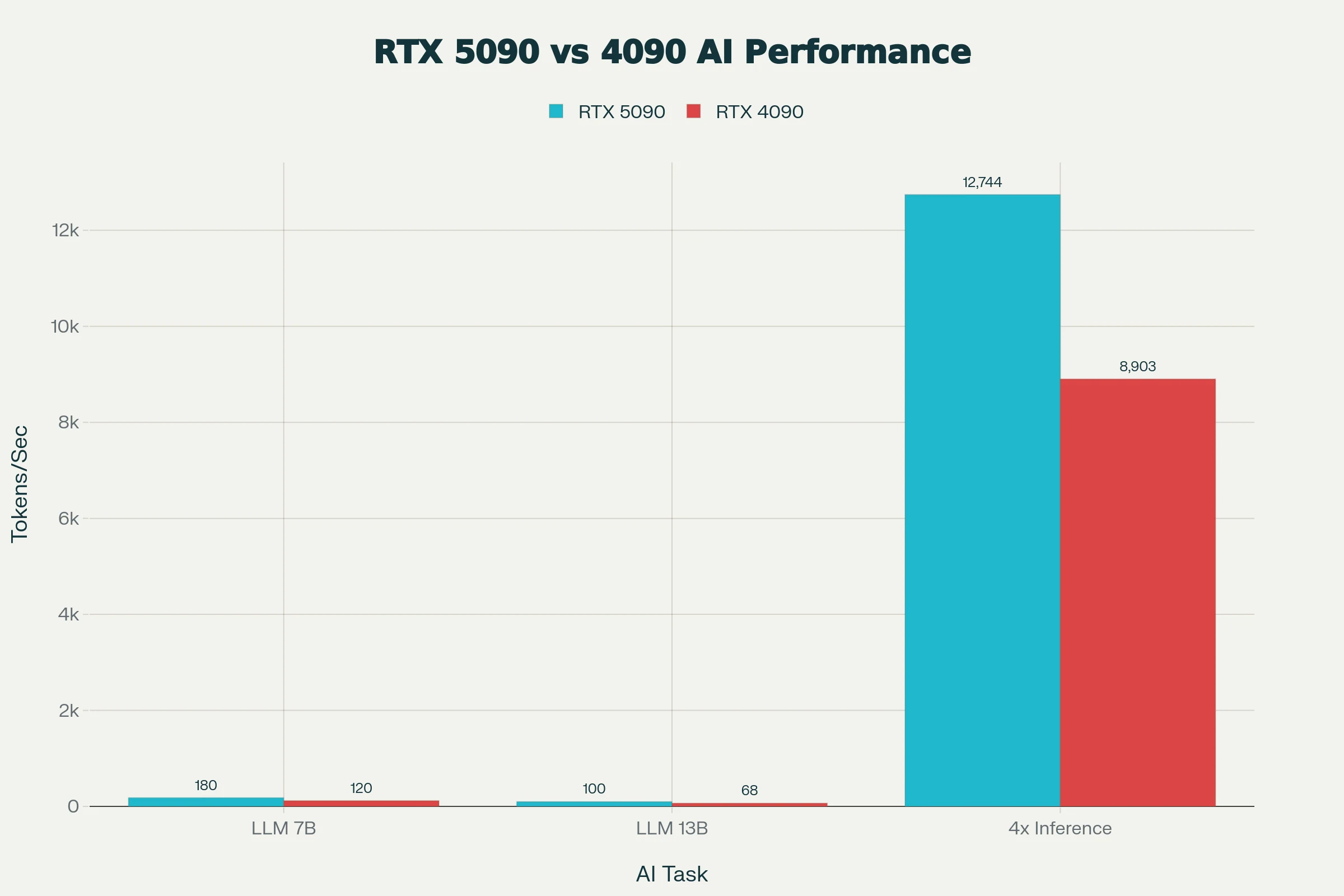
من AIGPUValue
هل تعتبر ذاكرة VRAM سعة 32 جيجابايت اختراقًا؟
تتيح ذاكرة VRAM سعة 32 جيجابايت الخاصة به تحميل نماذج LLM المكممة سعة 49B بالكامل، وهو قفزة نوعية من سعة 24 جيجابايت في 4090 للنماذج الانتشارية الأكبر أو نماذج 70B Q4 بسرعات عملية.
| المواصفات | RTX 5090 | RTX 4090 |
|---|---|---|
| البنية التحتية | Blackwell | Ada Lovelace |
| ذاكرة الوصول العشوائي (VRAM) | 32 جيجابايت GDDR7 | 24 جيجابايت GDDR6X |
| عرض نطاق الذاكرة | 1792 جيجابايت/ثانية | 1008 جيجابايت/ثانية |
| أنوية CUDA | 21760 | 16384 |
| أنوية Tensor | 680 | 512 |
| استهلاك الطاقة التصميمي (TDP) | 575 واط | 450 واط |
| السعر الموصى به من الشركة المصنعة (MSRP) | 1999 دولار | 1599 دولار |
ما الذي تتيحه سعة 32 جيجابايت:
- تشغيل نماذج LLM سعة 70B مع تكميم عدواني
- سير عمل الفيديو الانتشاري عالي الدقة (4K–8K)
- تدريب النماذج متوسطة الحجم دون التحقق من التدرج
| وحدة معالجة الرسومات (GPU) | الصور/الدقيقة | التحسن |
|---|---|---|
| RTX 5090 | 35 | +59% |
| RTX 4090 | 22 | القيمة الأساسية |
ما الذي لا تتيحه حتى الآن:
- تدريب نموذج 70B بدقة كاملة
- توليد فيديو عالي الدقة لعدة ساعات دون تخفيف حراري
ما الذي يجب على المطورين ترقيته لتشغيل 5090 بشكل آمن؟
إن RTX 5090 ليس بديلاً يمكن تركيبه مباشرة؛ فاستهلاكه للطاقة التصميمي البالغ 575 واط وواجهة PCIe 5.0 يتطلبان ترقيات على مستوى المنصة بدلاً من مجرد استبدال مكونات بسيطة. تتطلب أحمال عمل الذكاء الاصطناعي المستقرة طويلة المدة عادةً مصدر طاقة أعلى سعة، وحلول تبريد معززة، وهيكل chassis محسّن لتدفق الهواء والدعم الهيكلي، وعرض نطاق كافٍ لمسار البيانات. تفتقر البطاقة أيضًا إلى تقنية NVLink، مما يعني أن جميع الاتصالات بين وحدات معالجة الرسومات تعتمد حصريًا على PCIe، مما يحد من كفاءة التوسع للتدريب ويزيد من مشكلة التكدس الحراري في البيئات متعددة وحدات معالجة الرسومات.
الأجهزة التي يجب ترقيتها
- مصدر طاقة (PSU) سعة 1000–1200 واط (معيار ATX 3.1 / PCIe 5.1، موصل 12V-2x6)
- نظام تبريد عالي السعة (مراوح هواء كبيرة أو تبريد سائل)
- هيكل chassis مع فتحات PCIe معززة وتدفق هواء قوي
- فتحة PCIe 5.0 ×16 الأساسية على اللوحة الأم
- ذاكرة وصول عشوائي (RAM) DDR5 سعة 64–128 جيجابايت لأحمال عمل LLM مع التحميل الخارجي
- قرص SSD NVMe من الجيل الرابع/الخامس لتخزين النماذج
1. متطلبات توصيل الطاقة
يوصى بمصدر طاقة سعة 1000–1200 واط لاستيعاب الأحمال العالية المستمرة والذروات العابرة. تساعد تصنيفات الكفاءة 80+ الذهبية أو البلاتينية على تقليل الحرارة وتكلفة التشغيل على المدى الطويل. يجب تثبيت موصل 12V-2x6 مع تخفيف الضغط، حيث أن حرارة الموصل والضغط الميكانيكي من المخاوف الشائعة، خاصة في تركيبات وحدات معالجة الرسومات العمودية.

2. تكامل التبريد والهيكل
يتطلب طراز 5090 إما مبرد ثنائي أو ثلاثي الفتحات كبير أو تبريد سائل. تزداد الكثافة الحرارية بشكل حاد في التكوينات متعددة وحدات معالجة الرسومات، لذا غالبًا ما تصبح علب الأبراج الاستهلاكية غير كافية. يفضل الهياكل chassis ذات الألواح الشبكية، وفتحات وحدات معالجة الرسومات المعززة، ومسارات تدفق هواء قوية. يوصى باستخدام علب الخوادم أو محطات العمل لمجموعات 2× أو 4× من طراز 5090.

3. متطلبات التخزين
تساعد أقراص SSD NVMe عالية السرعة (من الجيل الرابع/الخامس، فئة ~7 جيجابايت/ثانية) على تسريع تحميل النموذج الأولي وخلط مجموعات البيانات. لا تؤثر سرعة التخزين على عدد الرموز في الثانية ولكنها تحسن بشكل كبير استجابة سير العمل لعمليات تحميل النماذج المتكررة.

هل الأطر البرمجية جاهزة لـ 5090؟
1. إذا كان هدفك هو تطوير الذكاء الاصطناعي، أو التدريب، أو استدلال النماذج الكبيرة، استخدم لينكس
- أسرع إصدارات برامج تشغيل CUDA وأكثرها استقرارًا
- أفضل توافق مع PyTorch / TensorFlow / JAX / vLLM / TensorRT-LLM
- تصل تحسينات FP8 و BF16 و Blackwell أولاً إلى لينكس
- دعم ROCm و oneAPI هو الأقوى أيضًا على لينكس
- توسيع نطاق وحدات معالجة الرسومات المتعددة، وإدارة مسارات PCIe، وبدائل NVLink أكثر موثوقية
2. إذا كان هدفك هو سطح المكتب العام + استدلال الذكاء الاصطناعي + الراحة، استخدم ويندوز 11
- أسهل تثبيت (برامج التشغيل، التطبيقات، واجهة المستخدم)
- دعم CUDA الأصلي القوي
- واجهات المستخدم الرسومية التابعة لجهات خارجية (LM Studio, ComfyUI, A1111, إصدار ويندوز من Ollama) تعمل بسلاسة
- ممتاز للمستخدمين الذين لا يقومون بتطوير على مستوى البحث
القيود مقارنة بلينكس:
- تأتي تحديثات TensorRT-LLM، وتحسينات FP8، والنوى المتقدمة لاحقًا
- إعدادات وحدات معالجة الرسومات المتعددة أقل استقرارًا بسبب اختلافات برامج التشغيل
- أداء أقل في الحالات الحدية (اختناقات الإدخال/الإخراج، تشبع PCIe)
| حالة الاستخدام الخاصة بك | أفضل نظام | السبب |
|---|---|---|
| نماذج لغة كبيرة (LLM) كبيرة (30B–70B)، خطوط أنابيب FP8، تدريب، vLLM | لينكس | أسرع CUDA، أفضل استقرار، الأولوية للنظام البيئي |
| استدلال على وحدة معالجة رسومات واحدة، انتشار مستقر (Stable Diffusion)، أدوات واجهة المستخدم الرسومية | ويندوز | الأسهل، دعم واجهة المستخدم الرسومية الأوسع |
| سير عمل مختلط (برمجة + ذكاء اصطناعي ثقيل من وقت لآخر) | ويندوز + WSL2 | راحة + أداء جيد |
| محطة عمل متعددة وحدات معالجة الرسومات (2× أو 4× 5090) | لينكس | استقرار برامج التشغيل وإدارة PCIe |
أي المطورين يستفيدون أكثر من طراز 5090؟
| الفئة | هل يجب عليك شراء RTX 5090؟ | السبب الرئيسي |
|---|---|---|
| توليد الفيديو / متعدد الوسائط | نعم بقوة | FP8 + عرض النطاق = uplift هائل |
| انتشار (SDXL, Flux) | نعم بقوة | دقة عالية + توسيع دفعات |
| تدريب متوسطة الحجم (≤20B) | نعم بقوة | تكرار أسرع، تدريب على وحدة معالجة رسومات واحدة قابل للتطبيق |
| استدلال الشركات المحلي | نعم بقوة | مزيد من النسخ، إنتاجية أعلى |
| استدلال نماذج LLM المكممة فقط | ربما لا | ميزة ضئيلة مقارنة بـ 4090 |
| أولئك الذين يزيدون من الميزانية | ربما لا | 4090 / سحابة أفضل عائد استثمار |
| مستخدمو التدريب متعدد وحدات معالجة الرسومات | ربما لا | يحتاج إلى ذاكرة + اتصال بيني، وليس قوة بطاقة واحدة خام |
كيف تشغل RTX 5090 بسعر منخفض جدًا؟
توفر Novita AI منصة سحابية مع مثيلات لوحدات معالجة الرسومات عالية الأداء. بفضل وحدات معالجة الرسومات القوية، تضمن أداءً فعالاً للمهام المعقدة، وتعزيز إمكانية الوصول للنشر عبر أجهزة مختلفة، وتقدم حلاً فعالاً من حيث التكلفة مقارنة بالحفاظ على الأجهزة المحلية لنشرات الذكاء الاصطناعي واسعة النطاق.
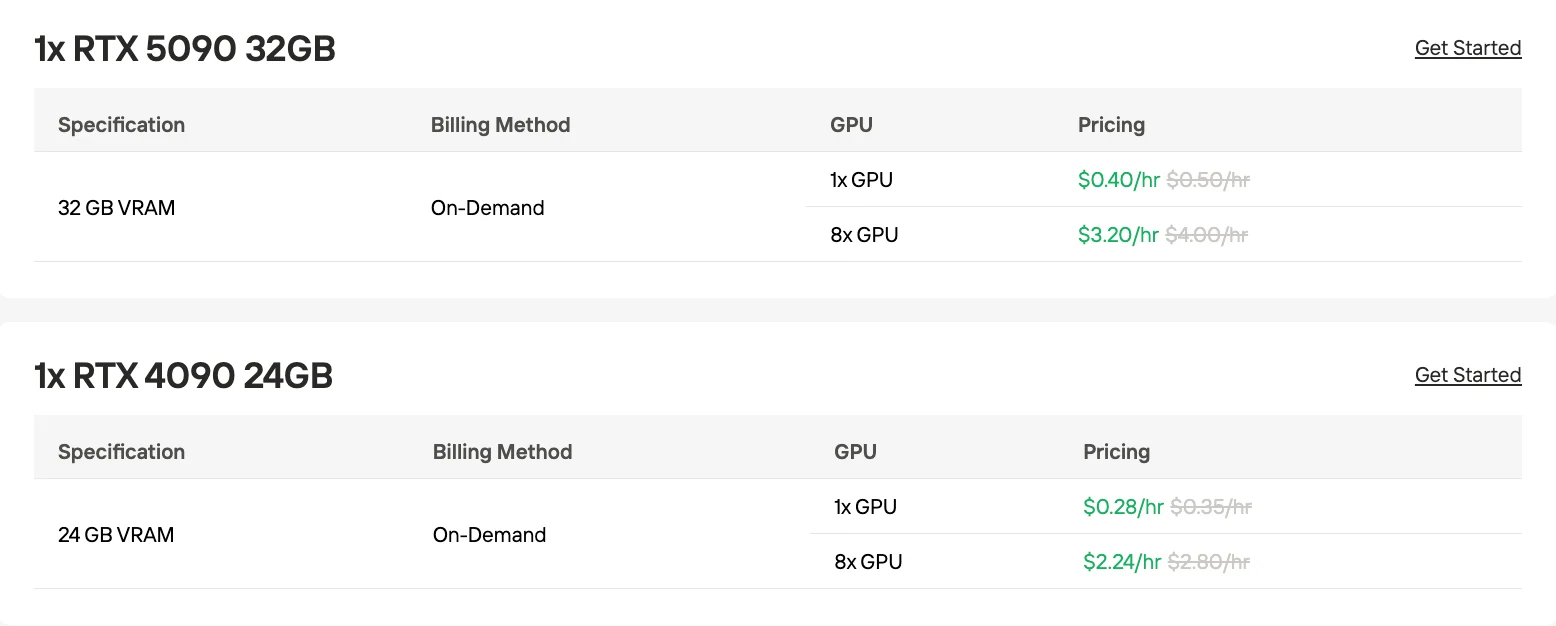
1x RTX4090 GPU: 0.28 دولار/ساعة
8x RTX4090 GPU: 2.24 دولار/ساعة
1x RTX4090 GPU: 0.40 دولار/ساعة
8x RTX4090 GPU: 3.20 دولار/ساعة
تقوم Novita AI بإطلاق حملة “شهر البناء” الخاصة بها، حيث تقدم للمطورين حافزًا حصريًا يصل إلى خصم 20% على جميع المنتجات الرئيسية!
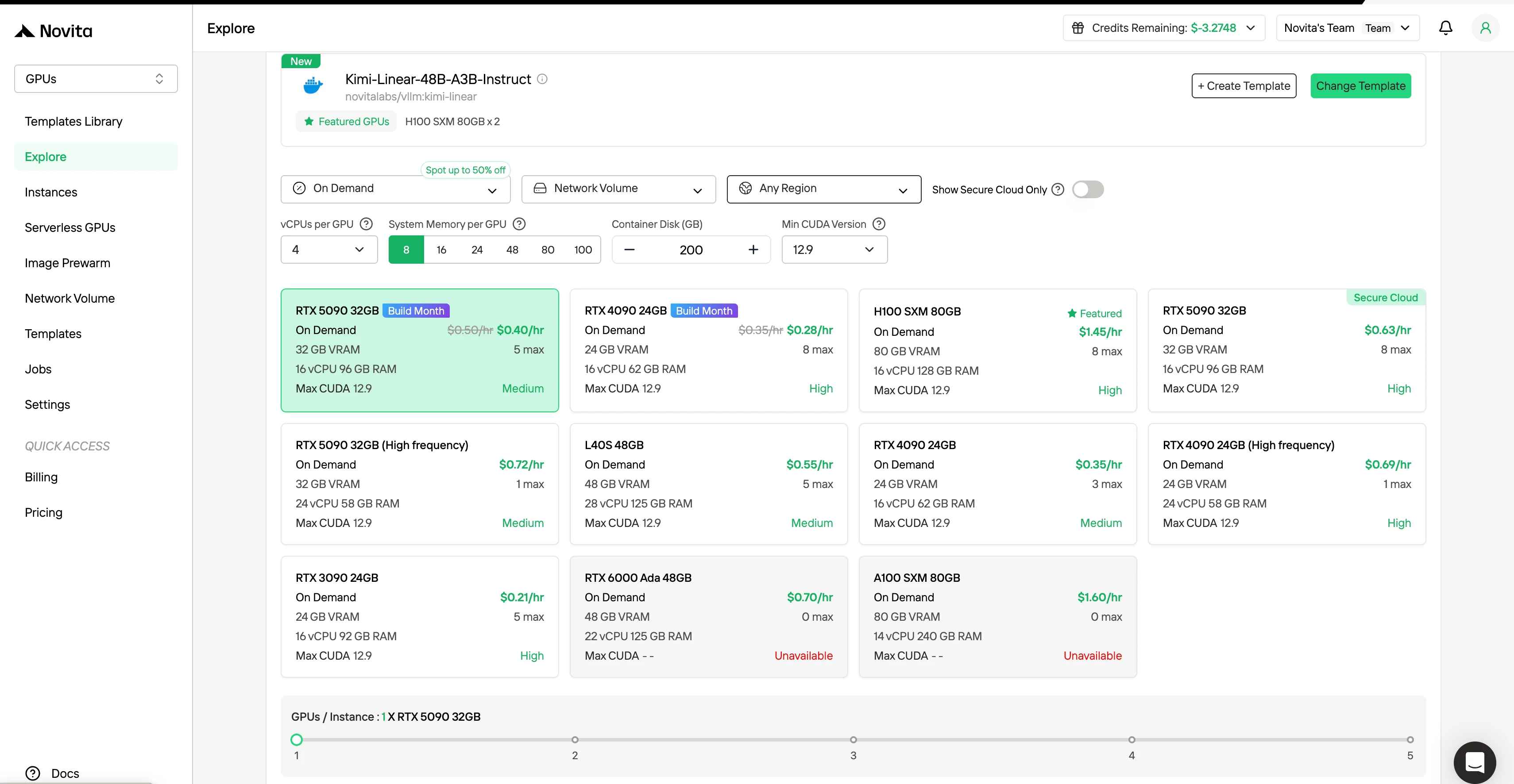
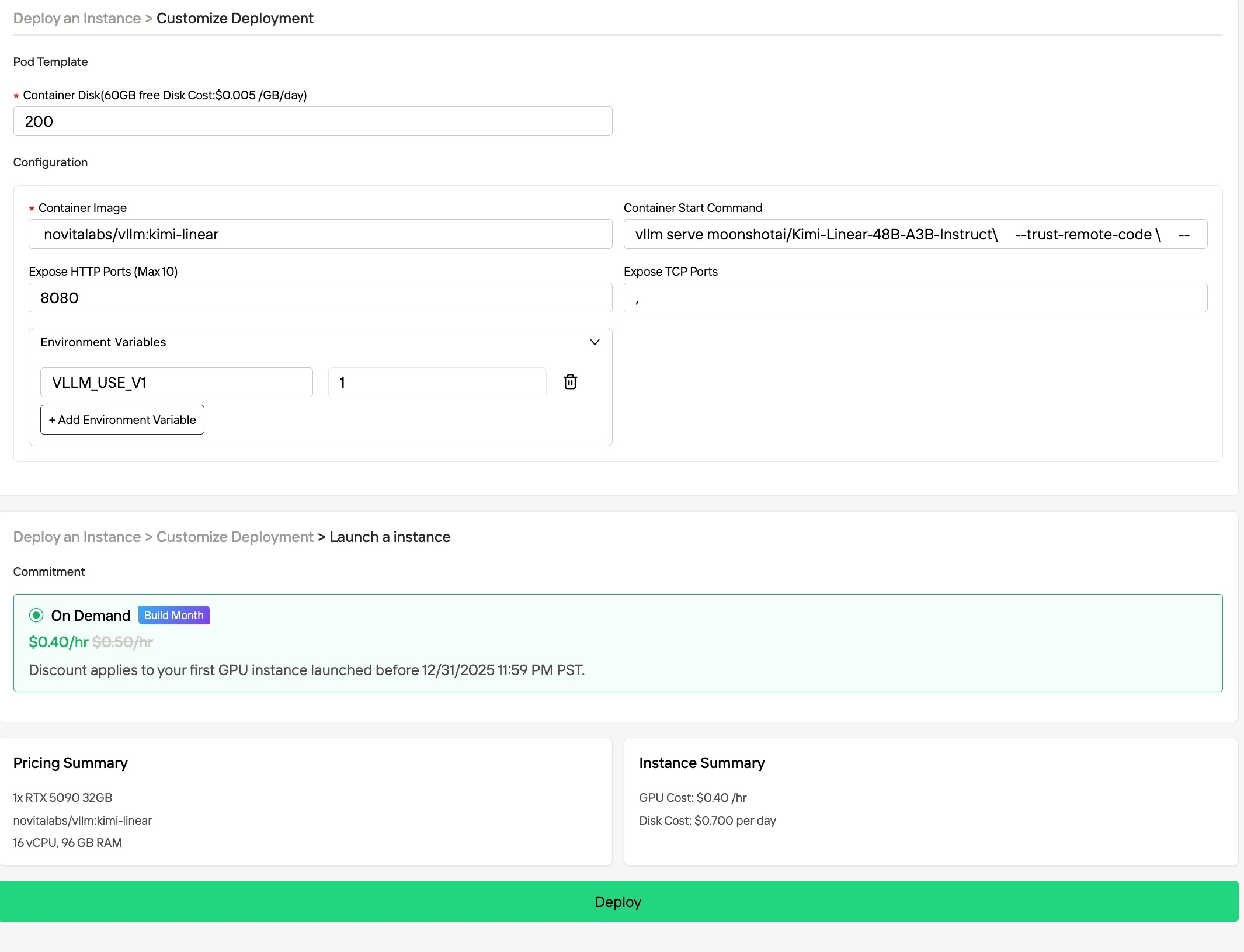
الخطوة 1: إنشاء حساب أنشئ حساب Novita AI الخاص بك عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض وحدات معالجة الرسومات الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي الخاصة بك.

الخطوة 2: استكشاف القوالب وخوادم وحدات معالجة الرسومات اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم اختر تكوين وحدة معالجة الرسومات المفضل لديك - تشمل الخيارات L40S القوي، أو RTX 4090 أو A100 SXM4، كل منها بذاكرة VRAM وذاكرة RAM وتخزين مختلف.
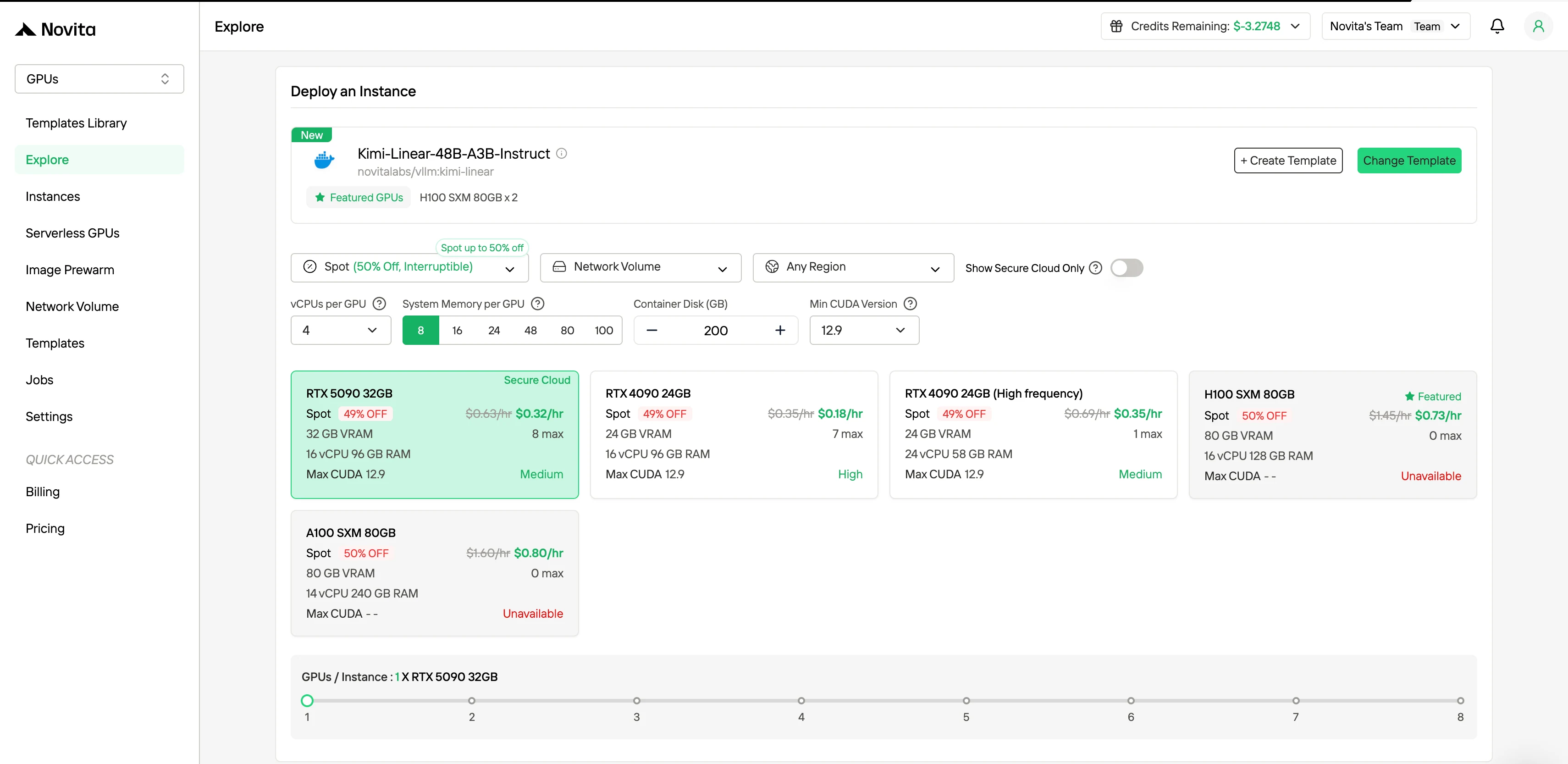
في الشريط الجانبي الأيمن تحت قسم “تصفية”، يمكنك تغيير طريقة الفوترة من “عند الطلب” إلى “Spot” لرؤية الأسعار المخفضة. يقوم الواجهة بالتحديث فورًا لإظهار توفير 50% مميز بوضوح. تضمن هذه الشفافية أنك تعرف بالضبط ما تدفعه قبل النشر.
يدعم مثيل Spot:
- فترة حماية لمدة ساعة واحدة مضمونة
- توفير في التكاليف يصل إلى 50% مفعل
- إشعار انقطاع مسبق لمدة ساعة واحدة مُعد
- أطر ذكاء اصطناعي مثبتة مسبقًا جاهزة
الخطوة 3: تخصيص النشر الخاص بك وإطلاق مثيل قم بتخصيص بيئتك عن طريق اختيار نظام التشغيل المفضل لديك وخيارات التكوين لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير. وبعد ذلك ستكون بيئة وحدة معالجة الرسومات عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي، أو العرض، أو الحساب الخاصة بك.
يمثل RTX 5090 قفزة بنوية كبيرة إلى الأمام، حيث يقدم إنتاجية FP8 أقوى، وعرض نطاق ذاكرة أعلى بشكل ملحوظ، وقفزة عملية إلى ذاكرة VRAM سعة 32 جيجابايت تتيح نماذج LLM مكممة أكبر، وسير عمل انتشاري عالي الدقة، وتدريب متوسطة الحجم. تعتمد مزاياه، مع ذلك، على ترقيات مطابقة في توصيل الطاقة، والتبريد، ودعم الهيكل، وعرض نطاق PCIe 5.0. بالنسبة للمطورين الذين يركزون على توليد الفيديو ومتعدد الوسائط، أو الانتشار SDXL/Flux، أو تدريب البحث على وحدة معالجة رسومات واحدة، يقدم طراز 5090 قيمة واضحة وفورية. بالنسبة للمستخدمين الذين يعطون الأولوية لاستدلال نماذج LLM المكممة، أو التوسع متعدد وحدات معالجة الرسومات، أو الكفاءة الصارمة من حيث التكلفة، يظل خيار RTX 4090 أو النشر السحابي أكثر ملاءمة. مع عروض Novita AI لمثيلات سحابية مخفضة، يمكن للمطورين تقييم أداء RTX 5090 دون استثمار مبدئي كبير.
الأسئلة الشائعة
ما مقدار السرعة التي يقدمها RTX 5090 مقارنة بـ RTX 4090 في أحمال العمل الفعلية يوفر RTX 5090 سرعة استدلال LLM تزيد بنسبة 50% تقريبًا مقارنة بـ RTX 4090 في نماذج 7B–13B، ويصل إلى سرعة تصل إلى ~3 آلاف رمز/ثانية في vLLM لنموذج phi-4 باستخدام تسريع FP8/FP16.
هل تغير ذاكرة VRAM سعة 32 جيجابايت في RTX 5090 من النماذج التي يمكن للمطورين تشغيلها؟ نعم. يمكن لـ RTX 5090 تحميل نماذج LLM سعة 49B وحتى 70B Q4 بسرعات قابلة للاستخدام، بينما يقتصر RTX 4090 على ذاكرة VRAM سعة 24 جيجابايت الخاصة به لهذه الأحمال العمل.
ما هي أحمال العمل التي تستفيد أكثر من RTX 5090؟ يظهر توليد الفيديو/متعدد الوسائط، والانتشار SDXL/Flux، والتدريب متوسطة الحجم ≤20B، واستدلال الشركات المحلي مكاسب كبيرة على RTX 5090 مقارنة بـ RTX 4090.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومات بأسعار معقولة وموثوقة للبناء والتوسع.
قراءات موصى بها



