

Desenvolvedores que avaliam GPUs de próxima geração muitas vezes têm dificuldade em determinar se o RTX 5090 oferece vantagens significativas em relação ao RTX 4090 em cargas de trabalho reais de IA, restrições de infraestrutura e custo.
Este artigo resolve essa incerteza examinando três dimensões principais:
(1) ganhos de desempenho em inferência de LLM, difusão e geração multimodal habilitados pela arquitetura Blackwell, aceleração FP8 e 32 GB de VRAM; (2) requisitos de atualização em nível de plataforma necessários para executar um RTX 5090 com segurança e confiabilidade; (3) os perfis de desenvolvedores que mais se beneficiam da atualização versus aqueles para os quais um 4090 ou GPU em nuvem é mais custo-efetivo.
A análise ainda contextualiza o RTX 5090 em caminhos de implantação práticos, avaliando o suporte a Linux versus Windows e destacando o modelo de acesso de baixo custo da Novita AI. Juntas, essas dimensões fornecem aos desenvolvedores uma estrutura clara e baseada em evidências para decidir quando o RTX 5090 é o investimento correto.
A Novita AI está lançando sua campanha “Build Month”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
Quanto o RTX 5090 Realmente Melhora as Cargas de Trabalho de IA?
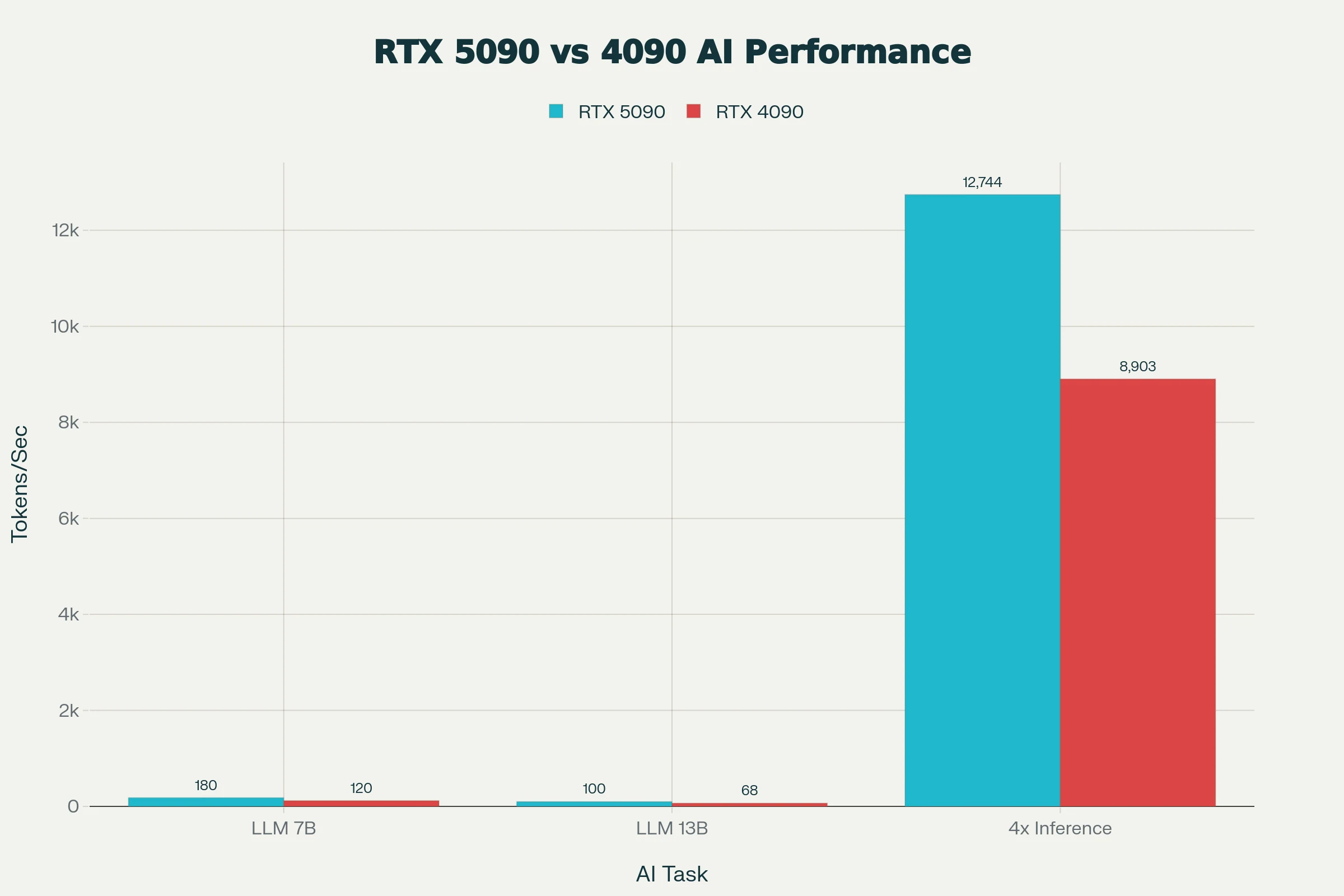
O RTX 5090 oferece inferência de LLM cerca de 50% mais rápida que o RTX 4090 em modelos de 7B a 13B, com aceleração FP8/FP16 permitindo até 3k tokens/s no vLLM para o phi-4.
De AIGPUValue
32 GB de VRAM é um Avanço Revolucionário?
Seus 32 GB de VRAM carregam LLMs quantizados de 49B completamente, um salto qualitativo em relação aos 24 GB do 4090 para modelos de difusão maiores ou LLMs de 70B Q4 em velocidades práticas.
| Especificação | RTX 5090 | RTX 4090 |
|---|---|---|
| Arquitetura | Blackwell | Ada Lovelace |
| VRAM | 32 GB GDDR7 | 24 GB GDDR6X |
| Largura de Banda de Memória | 1.792 GB/s | 1.008 GB/s |
| Núcleos CUDA | 21.760 | 16.384 |
| Núcleos Tensor | 680 | 512 |
| TDP | 575 W | 450 W |
| Preço Sugerido pelo Fabricante | US$ 1.999 | US$ 1.599 |
O que 32 GB de VRAM permite:
- Executar LLMs de 70B com quantização agressiva
- Fluxos de trabalho de vídeo de difusão em alta resolução (4K a 8K)
- Treinamento de modelos em escala média sem checkpoint de gradiente
| GPU | Imagens/Minuto | Melhoria |
|---|---|---|
| RTX 5090 | 35 | +59% |
| RTX 4090 | 22 | linha de base |
O que ainda não permite:
- Treinamento de LLMs de 70B em precisão total
- Geração de vídeo em alta resolução por várias horas sem throttling térmico
O Que os Desenvolvedores Precisam Atualizar para Executar um 5090 com Segurança?
O RTX 5090 não é uma substituição direta; sua potência de projeto térmico de 575 W e interface PCIe 5.0 exigem atualizações em nível de plataforma, em vez de trocas simples de componentes. Cargas de trabalho de IA estáveis de longa duração geralmente exigem uma fonte de alimentação de maior capacidade, soluções de resfriamento reforçadas, um chassi otimizado para fluxo de ar e suporte estrutural, e largura de banda de caminho de dados suficiente. A placa também não possui NVLink, o que significa que toda a comunicação entre GPUs depende exclusivamente do PCIe, limitando a eficiência de escalonamento para treinamento e exacerbando o empilhamento térmico em ambientes com múltiplas GPUs.
Hardware Que Deve Ser Atualizado
- Fonte de alimentação (PSU) de 1000 a 1200 W (ATX 3.1 / PCIe 5.1, 12V-2x6)
- Sistema de resfriamento de alta capacidade (coolers de ar grandes ou resfriamento líquido)
- Chassi com slots PCIe reforçados e fluxo de ar forte
- Slot primário PCIe 5.0 x16 na placa-mãe
- 64 a 128 GB de RAM DDR5 para cargas de trabalho de LLM com offloading
- SSD NVMe Gen4/Gen5 para armazenamento de modelos
1.Requisitos de Entrega de Energia
Recomenda-se uma fonte de alimentação de 1000 a 1200 W para acomodar cargas altas sustentadas e picos transitórios. Classificações de eficiência 80+ Gold ou Platinum ajudam a reduzir o calor e o custo operacional a longo prazo. O conector 12V-2x6 deve ser instalado com alívio de tensão, já que o superaquecimento do conector e o estresse mecânico são preocupações comuns, especialmente em montagens verticais de GPU.

2.Integração de Resfriamento e Chassi
O 5090 requer um cooler grande de slot duplo ou triplo, ou resfriamento líquido. A densidade térmica aumenta drasticamente em configurações com múltiplas GPUs, então gabinetes tower de consumo geralmente se tornam inadequados. Chassis com painéis de malha, slots de GPU reforçados e caminhos de fluxo de ar fortes são preferidos. Gabinetes de servidor ou workstation são recomendados para arrays de 2x ou 4x 5090.

3.Requisitos de Armazenamento
SSDs NVMe de alta velocidade (classe Gen4/Gen5, ~7 GB/s) aceleram o carregamento inicial de modelos e o embaralhamento de conjuntos de dados. A velocidade de armazenamento não afeta os tokens por segundo, mas melhora significativamente a responsividade do fluxo de trabalho para carregamentos repetidos de modelos.

Os Frameworks Estão Prontos para o 5090?
1. Se seu objetivo é desenvolvimento de IA, treinamento ou inferência de modelos grandes, use Linux
- Lançamentos de drivers CUDA mais rápidos e estáveis
- Melhor compatibilidade com PyTorch / TensorFlow / JAX / vLLM / TensorRT-LLM
- Otimizações FP8, BF16 e Blackwell chegam primeiro no Linux
- O suporte a ROCm e oneAPI também é mais forte no Linux
- Escalonamento com múltiplas GPUs, gerenciamento de lanes PCIe e alternativas ao NVLink são mais confiáveis
2. Se seu objetivo é desktop geral + inferência de IA + conveniência,Use Windows 11
- Instalação mais fácil (drivers, aplicativos, interface)
- Suporte nativo forte a CUDA
- GUIs de terceiros (LM Studio, ComfyUI, A1111, compilação Windows do Ollama) funcionam sem problemas
- Ótimo para usuários que não fazem desenvolvimento em nível de pesquisa
Limitações vs Linux:
- Atualizações para TensorRT-LLM, otimizações FP8 e kernels avançados chegam mais tarde
- Configurações com múltiplas GPUs são menos estáveis devido a diferenças de drivers
- Desempenho menor em casos extremos (gargalos de E/S, saturação de PCIe)
| Seu Caso de Uso | Melhor Sistema | Por Quê |
|---|---|---|
| LLMs grandes (30B a 70B), pipelines FP8, treinamento, vLLM | Linux | CUDA mais rápido, melhor estabilidade, prioridade no ecossistema |
| Inferência com GPU única, Stable Diffusion, ferramentas GUI | Windows | Mais fácil, suporte GUI mais amplo |
| Fluxo de trabalho misto (programação + IA pesada ocasional) | Windows + WSL2 | Conveniência + desempenho decente |
| Workstation com múltiplas GPUs (2x ou 4x 5090) | Linux | Estabilidade de drivers e gerenciamento de PCIe |
Quais Desenvolvedores Mais se Beneficiam de um 5090?
| Categoria | Você Deve Comprar o RTX 5090? | Motivo Principal |
|---|---|---|
| Geração de vídeo / multimodal | SIM, fortemente | FP8 + largura de banda = ganho enorme |
| Difusão (SDXL, Flux) | SIM, fortemente | Alta resolução + escalonamento de lote |
| Treinamento em escala média (≤20B) | SIM, fortemente | Iteração mais rápida, treinamento viável com GPU única |
| Inferência empresarial local | SIM, fortemente | Mais instâncias, maior vazão |
| Apenas inferência de LLM quantizado | PROVAVELMENTE NÃO | Vantagem mínima em comparação com o 4090 |
| Maximizadores de orçamento | PROVAVELMENTE NÃO | 4090 / nuvem com melhor ROI |
| Usuários de treinamento com múltiplas GPUs | PROVAVELMENTE NÃO | Precisa de memória + interconexão, não apenas poder bruto de uma única placa |
Como Executar o RTX 5090 por um Preço Muito Baixo?
A Novita AI oferece uma plataforma baseada em nuvem com instâncias de GPU de alto desempenho. Com GPUs poderosas, garante desempenho eficiente para tarefas complexas, aumenta a acessibilidade para implantação em diferentes hardwares e oferece uma solução custo-efetiva em comparação com a manutenção de hardware local para implantações de IA em larga escala.
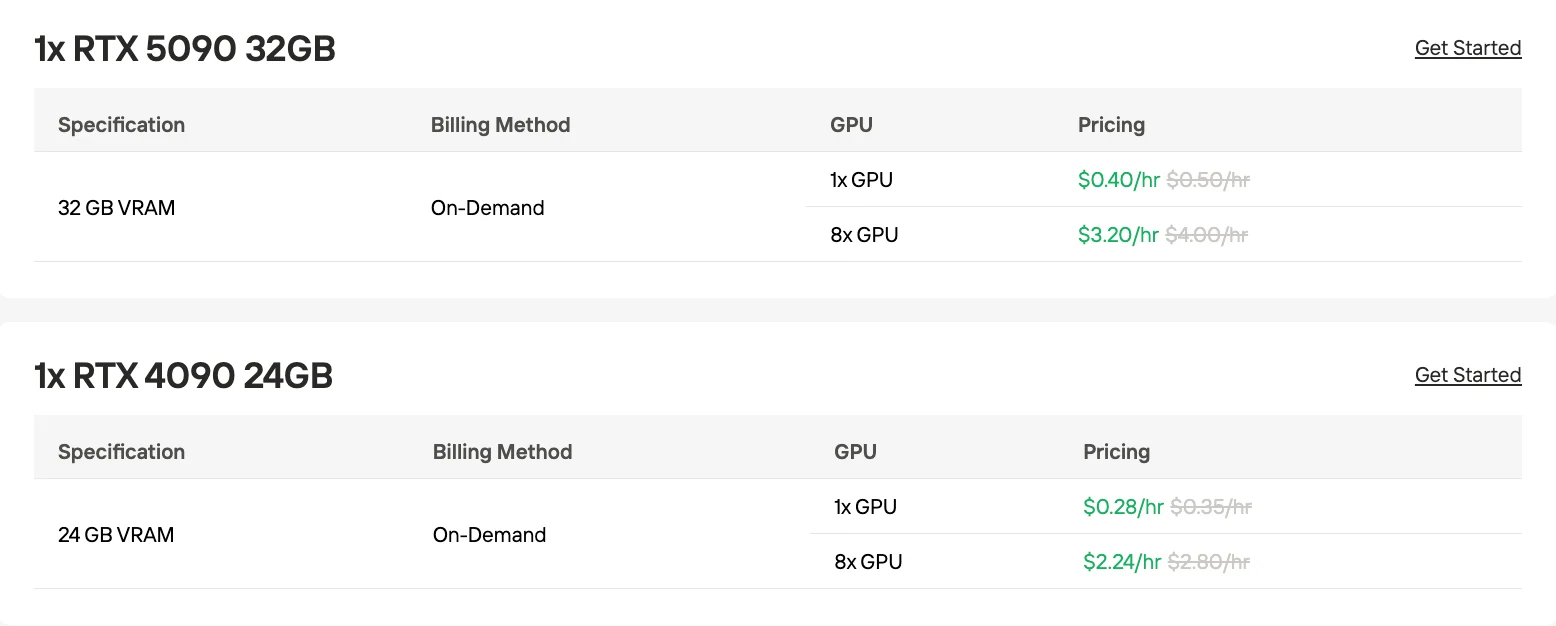
1x GPU RTX4090: US$ 0,28/h
8x GPU RTX4090: US$ 2,24/h
1x GPU RTX4090: US$ 0,40/h
8x GPU RTX4090: US$ 3,20/h
A Novita AI está lançando sua campanha “Build Month”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
Passo 1:Crie uma conta
Crie sua conta na Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2:Explorando Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida – as opções incluem as poderosas L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
Na barra lateral direita, em Filtro, você pode alterar o Método de Cobrança de “Sob Demanda” para “Spot” para ver preços com desconto. A interface atualiza imediatamente para mostrar os 50% de economia claramente destacados. Essa transparência garante que você saiba exatamente o que está pagando antes da implantação.
Instâncias Spot oferecem:
- Período de proteção de 1 hora garantido
- Até 50% de economia de custos ativada
- Aviso de interrupção com 1 hora de antecedência configurado
- Frameworks de IA pré-instalados prontos para uso
Passo 3:Personalize Sua Implantação e Lance uma Instância
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA específicas e necessidades de desenvolvimento. Em seguida, seu ambiente de GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computacionais.
O RTX 5090 representa um avanço arquitetônico substancial, oferecendo maior vazão FP8, largura de banda de memória significativamente maior e um salto prático para 32 GB de VRAM que possibilita LLMs quantizados maiores, fluxos de trabalho de difusão em alta resolução e treinamento em escala média. Seus benefícios, no entanto, dependem de atualizações correspondentes na entrega de energia, resfriamento, suporte de chassi e largura de banda PCIe 5.0. Para desenvolvedores focados em geração de vídeo e multimodal, difusão SDXL/Flux ou treinamento de pesquisa com GPU única, o 5090 oferece valor claro e imediato. Para usuários que priorizam inferência de LLM quantizado, escalonamento com múltiplas GPUs ou eficiência de custo rigorosa, um RTX 4090 ou implantação em nuvem continua sendo mais apropriado. Com a Novita AI oferecendo instâncias de nuvem com desconto, os desenvolvedores podem avaliar o desempenho do RTX 5090 sem um investimento inicial elevado.
Perguntas Frequentes
Quão mais rápido é o RTX 5090 que o RTX 4090 em cargas de trabalho reais
O RTX 5090 oferece inferência de LLM aproximadamente 50% mais rápida que o RTX 4090 em modelos de 7B a 13B e atinge até ~3k tokens/s no vLLM para o phi-4 usando aceleração FP8/FP16.
Os 32 GB de VRAM do RTX 5090 mudam quais modelos os desenvolvedores podem executar?
Sim. O RTX 5090 pode carregar LLMs de 49B e até 70B Q4 em velocidades utilizáveis, enquanto o RTX 4090 é limitado por seus 24 GB de VRAM nessas cargas de trabalho.
Quais cargas de trabalho mais se beneficiam do RTX 5090?
Geração de vídeo/multimodal, difusão SDXL/Flux, treinamento em escala média de até 20B e inferência empresarial local apresentam ganhos significativos no RTX 5090 em comparação com o RTX 4090.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.
Leituras Recomendadas



