

Entwickler, die nächste Generation von GPUs evaluieren, haben oft Schwierigkeiten zu bestimmen, ob die RTX 5090 gegenüber der RTX 4090 bei echten KI-Workloads, Infrastrukturbeschränkungen und Kosten sinnvolle Vorteile bietet.
Dieser Artikel begegnet dieser Unsicherheit, indem er drei zentrale Dimensionen untersucht:
- Leistungsgewinne bei LLM-Inferenz, Diffusion und multimodaler Generierung, ermöglicht durch die Blackwell-Architektur, FP8-Beschleunigung und 32 GB VRAM;
- auf Plattformebene erforderliche Upgrades, um eine RTX 5090 sicher und zuverlässig zu betreiben;
- Entwicklerprofile, die am meisten von dem Upgrade profitieren, im Vergleich zu denen, für die eine 4090 oder Cloud-GPU kosteneffektiver ist.
Die Analyse ordnet die RTX 5090 außerdem in praktische Bereitstellungspfade ein, indem sie die Linux- vs. Windows-Unterstützung bewertet und das kostengünstige Zugangsmodell von Novita AI hervorhebt. Zusammen bieten diese Dimensionen Entwicklern einen klaren, evidenzbasierten Rahmen, um zu entscheiden, wann die RTX 5090 die richtige Investition ist.
Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
Nehmen Sie an Ihrer Build Month teil!
Wie stark verbessert die RTX 5090 KI-Workloads tatsächlich?
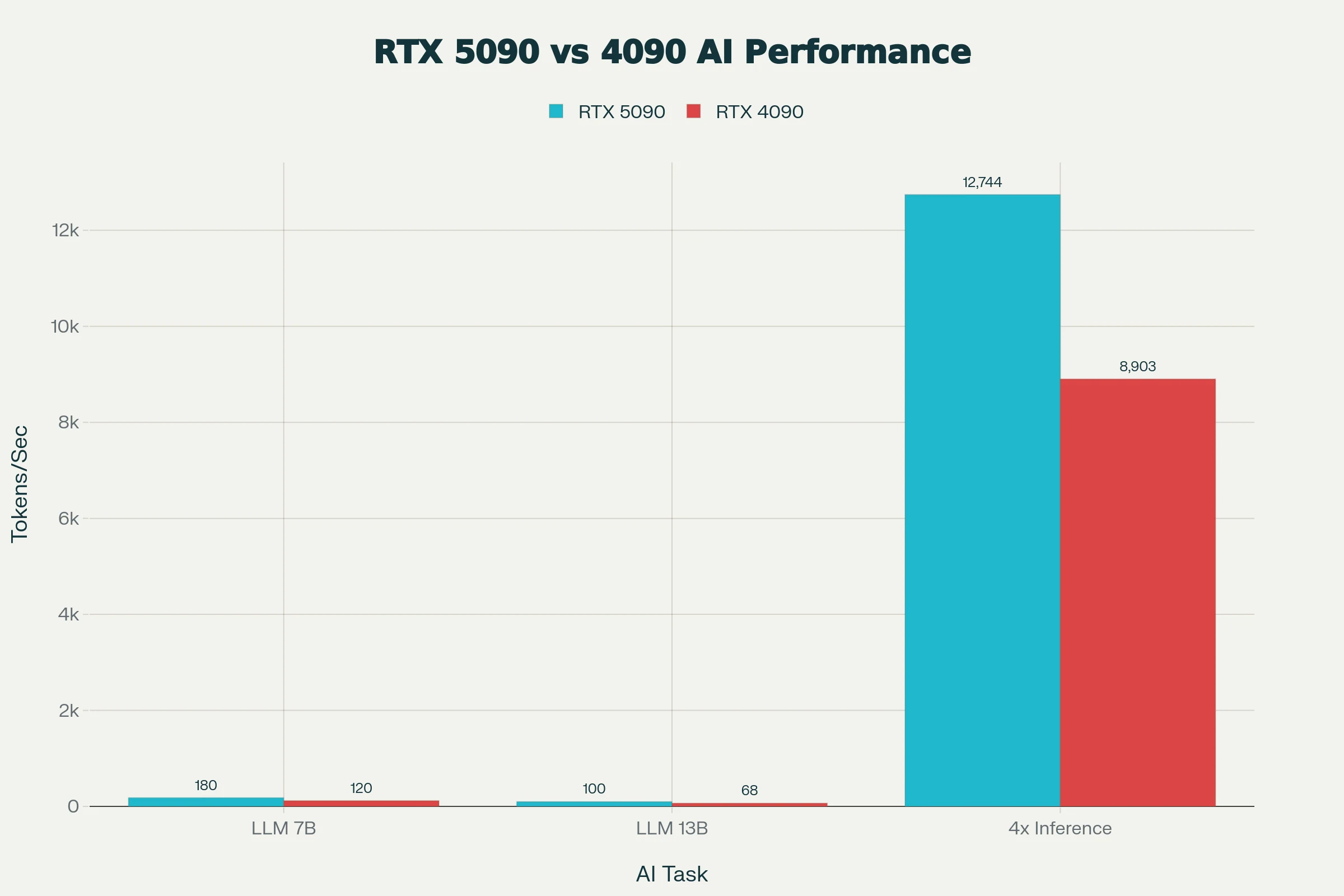
Die RTX 5090 bietet etwa 50 % schnellere LLM-Inferenz als die RTX 4090 bei 7B–13B-Modellen, wobei die FP8/FP16-Beschleunigung bis zu 3.000 Token/s in vLLM für phi-4 ermöglicht.
Von AIGPUValue
Ist 32 GB VRAM ein Durchbruch?
Ihre 32 GB VRAM laden quantisierte 49B-LLMs vollständig, ein qualitativer Sprung gegenüber den 24 GB der 4090 für größere Diffusions- oder 70B Q4-Modelle bei praktikablen Geschwindigkeiten.
| Spezifikation | RTX 5090 | RTX 4090 |
|---|---|---|
| Architektur | Blackwell | Ada Lovelace |
| VRAM | 32 GB GDDR7 | 24 GB GDDR6X |
| Speicherbandbreite | 1.792 GB/s | 1.008 GB/s |
| CUDA-Kerne | 21.760 | 16.384 |
| Tensor-Kerne | 680 | 512 |
| TDP | 575 W | 450 W |
| UVP | 1.999 $ | 1.599 $ |
Was 32 GB ermöglichen:
- Ausführen von 70B-LLMs mit aggressiver Quantisierung
- Hochauflösende (4K–8K) Diffusions-Video-Workflows
- Mittelgroßes Modelltraining ohne Gradienten-Checkpointing
| GPU | Bilder/Minute | Verbesserung |
|---|---|---|
| RTX 5090 | 35 | +59 % |
| RTX 4090 | 22 | Referenz |
Was es noch nicht ermöglicht:
- Vollpräzises Training von 70B-Modellen
- Mehrstündige hochauflösende Videogenerierung ohne thermische Drosselung
Was müssen Entwickler upgraden, um eine 5090 sicher zu betreiben?
Die RTX 5090 ist kein einfacher Ersatz; ihre thermische Leistungsaufnahme von 575 W und die PCIe-5.0-Schnittstelle erfordern Upgrades auf Plattformebene statt einfacher Komponententausche. Stabile, langandauernde KI-Workloads erfordern in der Regel ein Netzteil mit höherer Leistung, verstärkte Kühllösungen, ein für Luftstrom und strukturelle Unterstützung optimiertes Gehäuse sowie ausreichende Datenpfadbandbreite. Die Karte verfügt außerdem nicht über NVLink, sodass die gesamte GPU-übergreifende Kommunikation ausschließlich über PCIe läuft. Dies schränkt die Skalierungseffizienz für Trainings ein und verschärft die thermische Überlappung in Multi-GPU-Umgebungen.
Hardware, die aufgerüstet werden muss
- 1000–1200 W Netzteil (ATX 3.1 / PCIe 5.1, 12V-2x6)
- Hochleistungskühlsystem (große Luftkühler oder Flüssigkühlung)
- Gehäuse mit verstärkten PCIe-Slots und starkem Luftstrom
- PCIe-5.0-x16-Hauptsteckplatz auf dem Motherboard
- 64–128 GB DDR5-RAM für LLM-Workloads mit Offloading
- Gen4/Gen5-NVMe-SSD zur Modellspeicherung
1. Anforderungen an die Stromversorgung
Ein 1000–1200 W Netzteil wird empfohlen, um dauerhafte hohe Lasten und transienten Spitzen zu bewältigen. Effizienzklassen von 80+ Gold oder Platinum helfen, Wärme und langfristige Betriebskosten zu senken. Der 12V-2x6-Stecker muss mit Zugentlastung installiert werden, da Steckerhitze und mechanische Belastung häufige Probleme sind, insbesondere bei vertikalen GPU-Montagen.

2. Kühlung und Gehäuseintegration
Die 5090 erfordert entweder einen großen Dual- oder Triple-Slot-Kühler oder Flüssigkühlung. Die thermische Dichte steigt bei Multi-GPU-Konfigurationen stark an, sodass Consumer-Tower-Gehäuse oft unzureichend sind. Gehäuse mit Mesh-Blenden, verstärkten GPU-Slots und starken Luftstrompfaden werden bevorzugt. Für 2× oder 4× 5090-Arrays werden Server- oder Workstation-Gehäuse empfohlen.

3. Speicheranforderungen
Hochgeschwindigkeits-NVMe-SSDs (Gen4/Gen5, Klasse ~7 GB/s) beschleunigen das anfängliche Laden von Modellen und das Mischen von Datensätzen. Die Speichergeschwindigkeit beeinflusst nicht die Token pro Sekunde, verbessert aber die Workflow-Reaktionsfähigkeit bei wiederholtem Modellladen deutlich.

Sind Frameworks bereit für die 5090?
1. Wenn Ihr Ziel KI-Entwicklung, Training oder Inferenz von großen Modellen ist, verwenden Sie Linux
- Schnellste und stabilste CUDA-Treiberveröffentlichungen
- Beste Kompatibilität mit PyTorch / TensorFlow / JAX / vLLM / TensorRT-LLM
- FP8-, BF16- und Blackwell-Optimierungen erscheinen zuerst auf Linux
- ROCm- und oneAPI-Unterstützung ist ebenfalls am stärksten auf Linux
- Multi-GPU-Skalierung, PCIe-Lane-Verwaltung und NVLink-Alternativen sind zuverlässiger
2. Wenn Ihr Ziel allgemeiner Desktop + KI-Inferenz + Komfort ist, verwenden Sie Windows 11
- Einfachste Installation (Treiber, Apps, UI)
- Starke native CUDA-Unterstützung
- Drittanbieter-GUIs (LM Studio, ComfyUI, A1111, Ollama Windows-Build) laufen reibungslos
- Ideal für Benutzer, die keine entwicklungsbezogene Forschung betreiben
Einschränkungen im Vergleich zu Linux:
- Updates für TensorRT-LLM, FP8-Optimierungen und erweiterte Kernel kommen später
- Multi-GPU-Setups sind aufgrund von Treiberunterschieden weniger stabil
- Niedrigere Leistung bei Sonderfällen (I/O-Engpässe, PCIe-Sättigung)
| Ihr Anwendungsfall | Bestes System | Warum |
|---|---|---|
| Große LLMs (30B–70B), FP8-Pipelines, Training, vLLM | Linux | Schnellstes CUDA, beste Stabilität, Ökosystem zuerst |
| Einzel-GPU-Inferenz, Stable Diffusion, GUI-Tools | Windows | Einfachste, breiteste GUI-Unterstützung |
| Gemischter Workflow (Programmierung + gelegentlich anspruchsvolle KI) | Windows + WSL2 | Komfort + akzeptable Leistung |
| Multi-GPU-Workstation (2× oder 4× 5090) | Linux | Treiberstabilität und PCIe-Verwaltung |
Welche Entwickler profitieren am meisten von einer 5090?
| Kategorie | Sollten Sie eine RTX 5090 kaufen? | Hauptgrund |
|---|---|---|
| Video / multimodale Generierung | Deutlich Ja | FP8 + Bandbreite = riesiger Leistungsschub |
| Diffusion (SDXL, Flux) | Deutlich Ja | Hohe Auflösung + Batch-Skalierung |
| Mittelgroßes Training (≤20B) | Deutlich Ja | Schnellere Iteration, praktikables Einzel-GPU-Training |
| Enterprise-On-Premise-Inferenz | Deutlich Ja | Mehr Instanzen, höherer Durchsatz |
| Nur quantisierte LLM-Inferenz | Wahrscheinlich Nein | Minimaler Vorteil gegenüber der 4090 |
| Budget-Bewusste | Wahrscheinlich Nein | 4090 / Cloud hat bessere ROI |
| Multi-GPU-Trainingsbenutzer | Wahrscheinlich Nein | Benötigt Speicher + Interconnect, keine rohe Einzelkartenleistung |
Probieren Sie die RTX 5090 jetzt aus!
Wie Sie die RTX 5090 zu einem sehr niedrigen Preis nutzen können?
Novita AI bietet eine cloudbasierte Plattform mit leistungsstarken GPU-Instanzen. Mit leistungsfähigen GPUs gewährleistet sie effiziente Leistung für komplexe Aufgaben, verbessert die Zugänglichkeit für die Bereitstellung auf unterschiedlicher Hardware und bietet eine kosteneffektive Lösung im Vergleich zur Wartung lokaler Hardware für groß angelegte KI-Bereitstellungen.
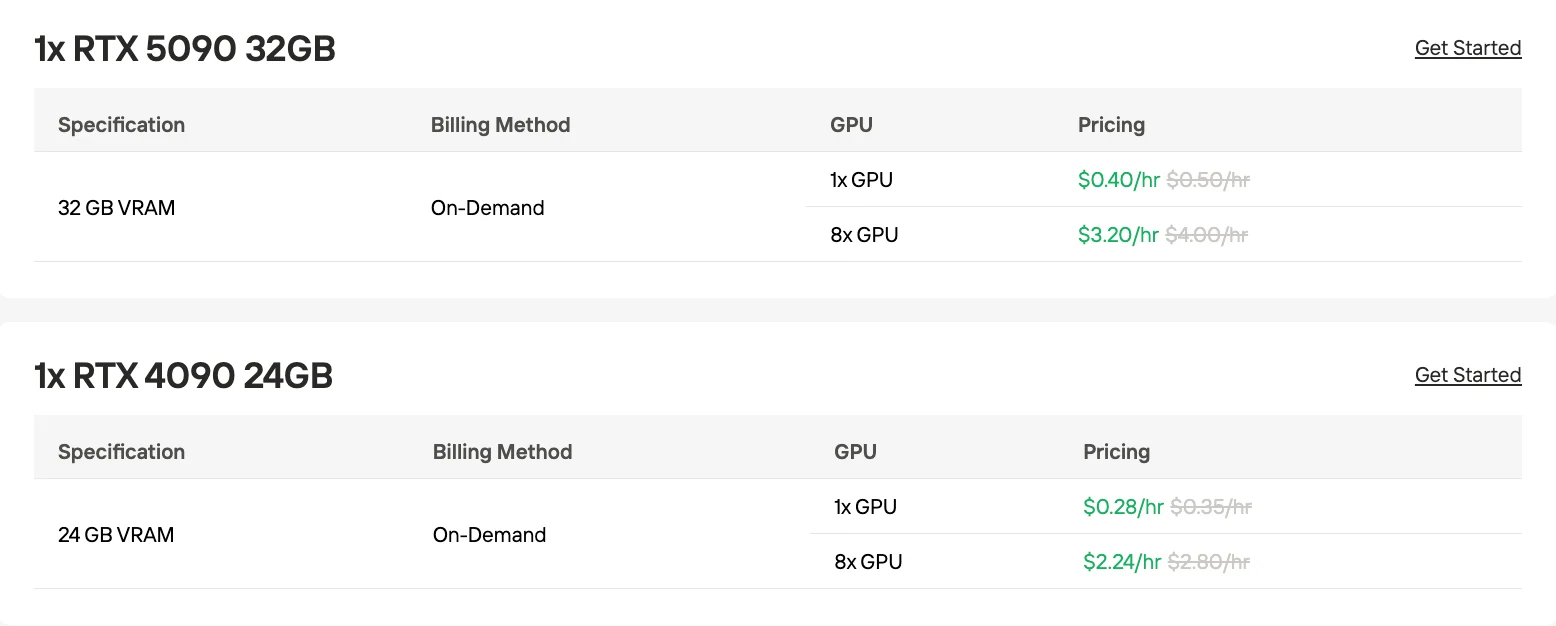
1x RTX4090 GPU: 0,28 $/h
8x RTX4090 GPU: 2,24 $/h
1x RTX4090 GPU: 0,40 $/h
8x RTX4090 GPU: 3,20 $/h
Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
Nehmen Sie an Ihrer Build Month teil!
Schritt 1: Registrieren Sie ein Konto Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken“ in der linken Seitenleiste, um unsere GPU-Angebote anzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
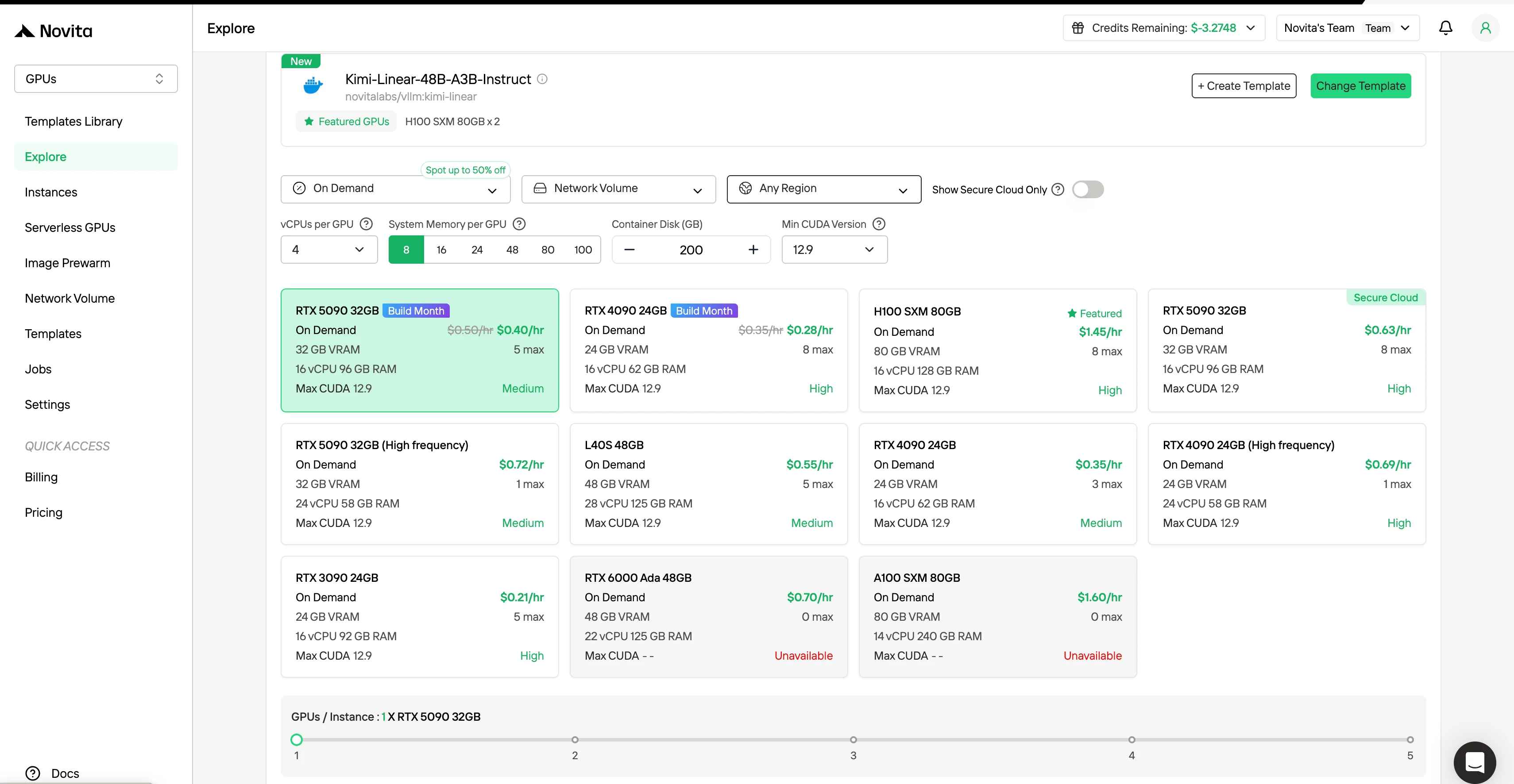
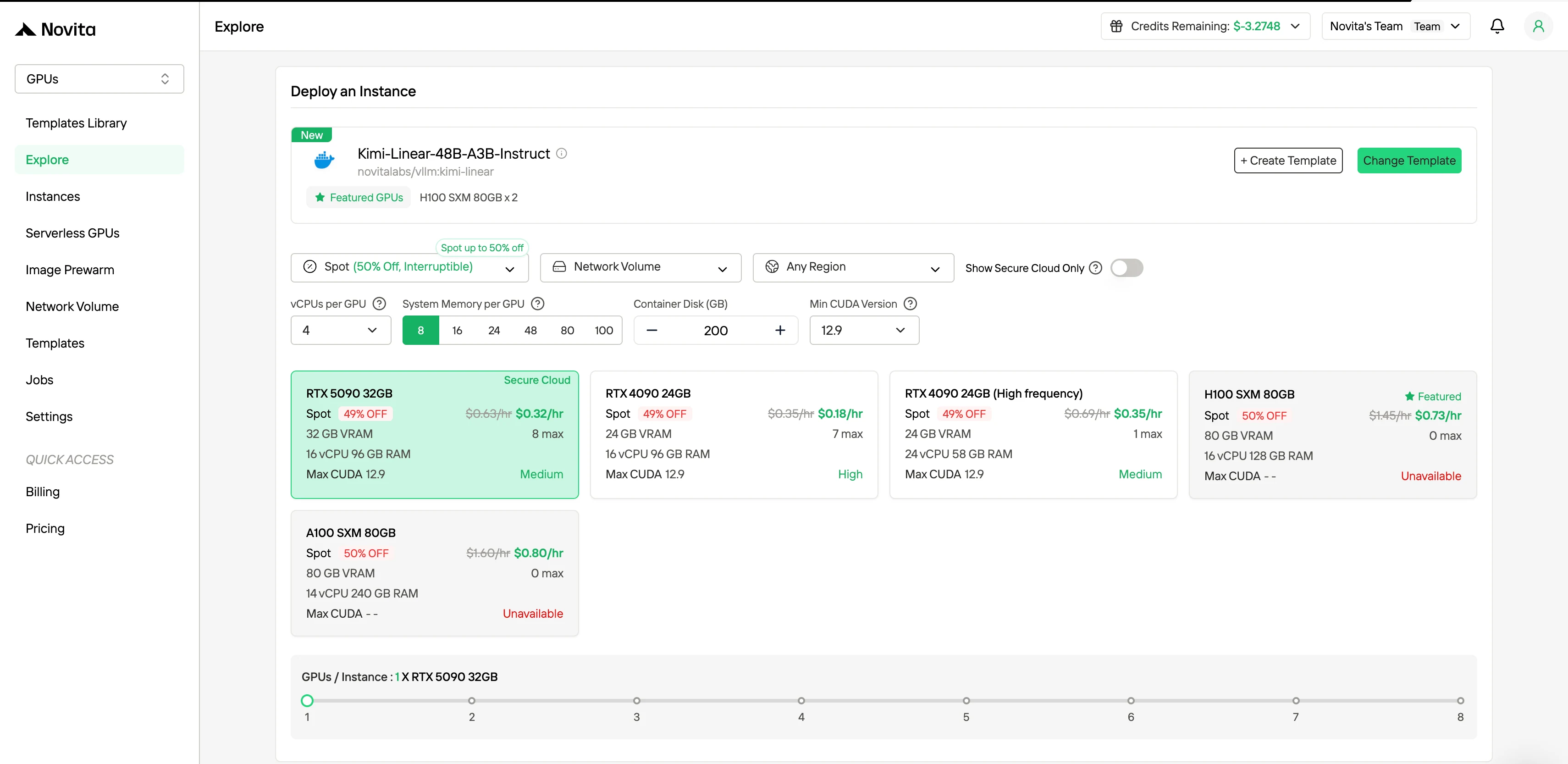
In der rechten Seitenleiste unter Filter können Sie die Abrechnungsmethode von „On-Demand“ zu „Spot“ ändern, um rabattierte Preise zu sehen. Die Oberfläche aktualisiert sich sofort, um die 50 % Ersparnis deutlich hervorzuheben. Diese Transparenz stellt sicher, dass Sie genau wissen, was Sie vor der Bereitstellung zahlen.
Spot-Instanzen unterstützen:
- 1 Stunde Schutzzeit garantiert
- Bis zu 50 % Kosteneinsparungen aktiviert
- 1 Stunde Vorankündigung bei Unterbrechung konfiguriert
- Vorinstallierte KI-Frameworks bereit
Schritt 3: Passen Sie Ihre Bereitstellung an und starten Sie eine Instanz Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten. Danach ist Ihre leistungsstarke GPU-Umgebung innerhalb von Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
Probieren Sie die RTX 5090 jetzt aus!
Die RTX 5090 stellt einen erheblichen architektonischen Fortschritt dar, mit stärkerem FP8-Durchsatz, deutlich höherer Speicherbandbreite und einem praktischen Sprung auf 32 GB VRAM, der größere quantisierte LLMs, hochauflösende Diffusions-Workflows und mittelgroßes Training ermöglicht. Ihre Vorteile hängen jedoch von passenden Upgrades bei Stromversorgung, Kühlung, Gehäuseunterstützung und PCIe-5.0-Bandbreite ab. Für Entwickler, die sich auf Video- und multimodale Generierung, SDXL/Flux-Diffusion oder Einzel-GPU-Forschungstraining konzentrieren, bietet die 5090 einen klaren und sofortigen Mehrwert. Für Benutzer, die quantisierte LLM-Inferenz, Multi-GPU-Skalierung oder strenge Kosteneffizienz priorisieren, bleibt eine RTX 4090 oder Cloud-Bereitstellung geeigneter. Mit den von Novita AI angebotenen rabattierten Cloud-Instanzen können Entwickler die Leistung der RTX 5090 ohne hohe Vorabinvestitionen bewerten.
Häufig gestellte Fragen
Wie viel schneller ist die RTX 5090 als die RTX 4090 bei echten Workloads? Die RTX 5090 bietet etwa 50 % schnellere LLM-Inferenz als die RTX 4090 bei 7B–13B-Modellen und erreicht bis zu ~3.000 Token/s in vLLM für phi-4 bei Verwendung von FP8/FP16-Beschleunigung.
Ändert der 32 GB VRAM der RTX 5090, welche Modelle Entwickler ausführen können? Ja. Die RTX 5090 kann 49B und sogar 70B Q4 LLMs mit nutzbaren Geschwindigkeiten laden, während die RTX 4090 bei diesen Workloads durch ihren 24 GB VRAM begrenzt ist.
Welche Workloads profitieren am meisten von der RTX 5090? Video/multimodale Generierung, SDXL/Flux-Diffusion, mittelgroßes ≤20B-Training und Enterprise-On-Premise-Inferenz zeigen alle deutliche Leistungsgewinne auf der RTX 5090 im Vergleich zur RTX 4090.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Empfohlene Lektüre



