

评估下一代 GPU 的开发者常常难以判断,RTX 5090 在实际 AI 工作负载、基础设施限制和成本方面,是否比 RTX 4090 具有显著优势。
本文从三个核心维度来解答这一不确定性:
(1) Blackwell 架构、FP8 加速和 32GB VRAM 在 LLM 推理、扩散模型和多模态生成中带来的性能提升;
(2) 安全稳定运行 RTX 5090 所需的平台级升级要求;
(3) 哪些开发者画像从升级中获益最大,而哪些情况下 4090 或云端 GPU 更具成本效益。
此外,本文还通过评估 Linux 与 Windows 的支持情况,并重点介绍 Novita AI 的低成本访问模式,将 RTX 5090 置于实际部署路径中。综合这些维度,为开发者提供清晰、基于证据的决策框架,判断何时投资 RTX 5090 是明智之举。
Novita AI 正在推出“Build Month”活动,为开发者提供所有主要产品最高 20% 折扣的专属优惠!
RTX 5090 在实际 AI 工作负载中有多大提升?
在 7B-13B 模型中,RTX 5090 的 LLM 推理速度比 RTX 4090 快约 50%,借助 FP8/FP16 加速,在 vLLM 中运行 phi-4 可达约 3k 令牌/秒。
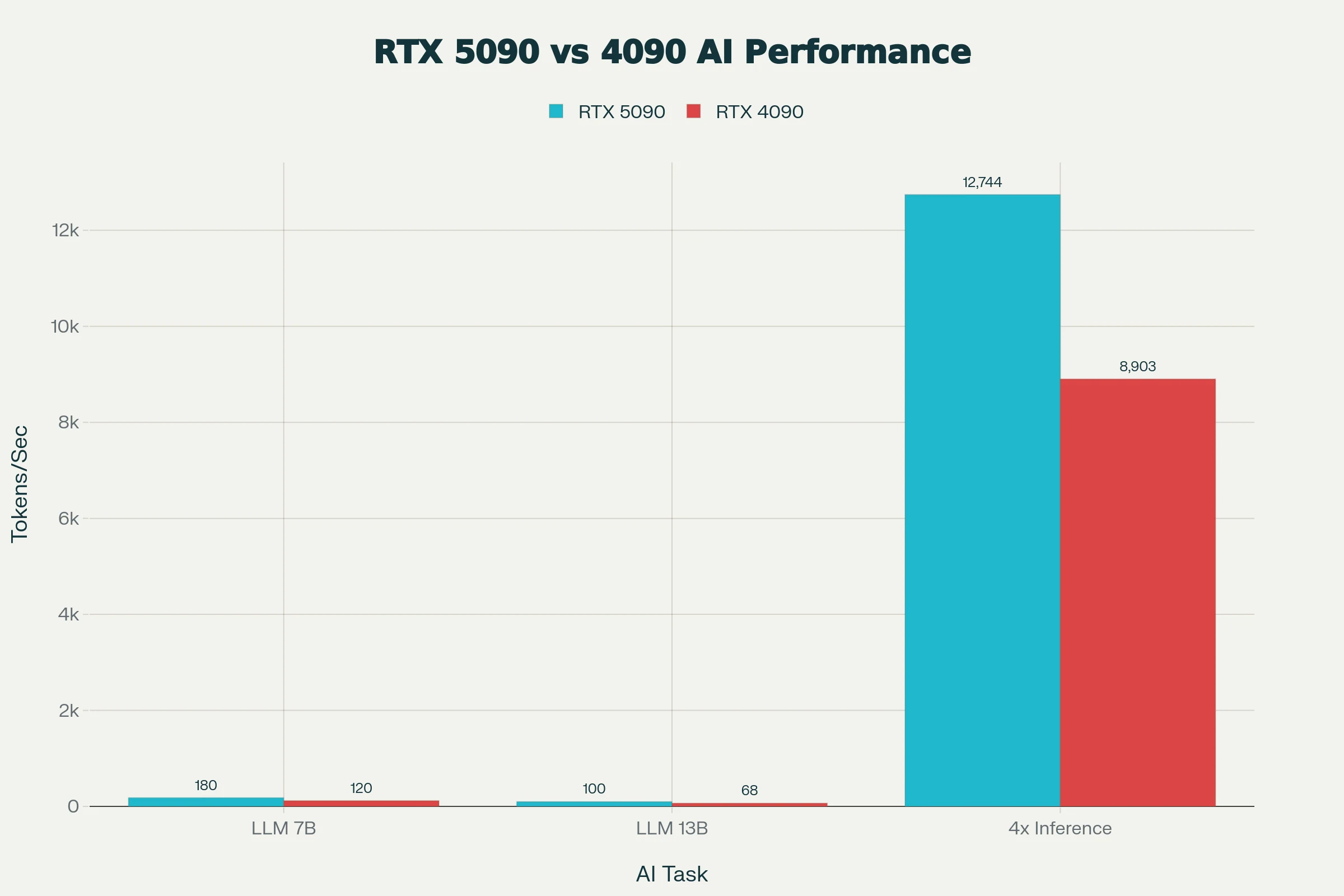
数据来源:AIGPUValue
32GB VRAM 是一项突破吗?
其 32GB VRAM 可完全加载 49B 量化 LLM,与 4090 的 24GB 相比,在处理更大规模的扩散模型或 70B Q4 模型时,实现了质的飞跃,且速度实用。
| 规格 | RTX 5090 | RTX 4090 |
|---|---|---|
| 架构 | Blackwell | Ada Lovelace |
| 显存 | 32GB GDDR7 | 24GB GDDR6X |
| 显存带宽 | 1,792 GB/s | 1,008 GB/s |
| CUDA 核心数 | 21,760 | 16,384 |
| Tensor 核心数 | 680 | 512 |
| TDP | 575W | 450W |
| 建议零售价 | $1,999 | $1,599 |
32GB 开启的能力:
- 运行高度量化的 70B LLM
- 高分辨率(4K–8K)扩散视频工作流
- 无需梯度检查点的中规模模型训练
| GPU | 图像/分钟 | 提升幅度 |
|---|---|---|
| RTX 5090 | 35 | +59% |
| RTX 4090 | 22 | 基准 |
目前尚未 实现的能力:
- 全精度 70B 训练
- 无热节流的多小时高分辨率视频生成
运行 RTX 5090 需要升级哪些硬件?
RTX 5090 并非简单的即插即用替代品;其 575W 热设计功耗和 PCIe 5.0 接口要求平台级升级,而非仅更换组件。稳定的长时间 AI 工作负载通常需要更大功率的电源、强化散热方案、优化气流和结构支撑的机箱,以及充足的数据通道带宽。该显卡还缺少 NVLink,因此所有 GPU 间通信仅依赖 PCIe,这会限制训练时的扩展效率,并在多 GPU 环境中加剧散热问题。
必须升级的硬件
- 1000–1200 W 电源(ATX 3.1 / PCIe 5.1,12V-2x6 接口)
- 大容量散热系统(大型风冷或水冷)
- 带有加固 PCIe 插槽和良好气流的机箱
- 主板上的 PCIe 5.0 ×16 主插槽
- 64–128 GB DDR5 内存(用于带卸载的 LLM 工作负载)
- Gen4/Gen5 NVMe SSD(用于模型存储)
- 供电要求
建议使用 1000–1200 W 电源,以应对持续高负载和瞬时峰值。80+ Gold 或 Platinum 能效等级有助于减少热量和长期运行成本。必须安装 12V-2x6 连接器并做好应力消除,因为连接器发热和机械应力是常见问题,尤其是在垂直 GPU 安装中。

- 散热与机箱集成
RTX 5090 需要大型双槽或三槽风冷或水冷。在多 GPU 配置中,热密度急剧增加,因此消费级塔式机箱往往力不从心。优选带有网状面板、加固 GPU 插槽和良好气流路径的机箱。对于 2× 或 4× 5090 阵列,建议使用服务器或工作站机箱。

- 存储要求
高速 NVMe SSD(Gen4/Gen5,约 7 GB/s 级别)可加速初始模型加载和数据集混洗。存储速度不影响每秒令牌数,但能显著提高重复加载模型时的工作流响应速度。

框架是否已为 RTX 5090 做好准备?
1. 如果你的目标是 AI 开发、训练或大型模型推理,请使用 Linux
- 最快且最稳定的 CUDA 驱动发布
- 与 PyTorch / TensorFlow / JAX / vLLM / TensorRT-LLM 的最佳兼容性
- FP8、BF16 和 Blackwell 优化首先在 Linux 上实现
- ROCm 和 oneAPI 支持同样在 Linux 上最强
- 多 GPU 扩展、PCIe 通道管理和 NVLink 替代方案更可靠
2. 如果你的目标是通用桌面 + AI 推理 + 便利性,请使用 Windows 11
- 安装最简单(驱动、应用、界面)
- 强大的原生 CUDA 支持
- 第三方 GUI(LM Studio、ComfyUI、A1111、Ollama Windows 版本)运行流畅
- 非常适合不从事研究级开发的用户
与 Linux 相比的局限性:
- TensorRT-LLM、FP8 优化和高级内核的更新较晚
- 多 GPU 设置因驱动差异而不够稳定
- 在边缘情况(I/O 瓶颈、PCIe 饱和)下性能较低
| 你的用例 | 最佳系统 | 原因 |
|---|---|---|
| 大型 LLM(30B–70B)、FP8 流水线、训练、vLLM | Linux | 最快的 CUDA、最佳稳定性、生态系统优先 |
| 单 GPU 推理、Stable Diffusion、GUI 工具 | Windows | 最简单、最广泛的 GUI 支持 |
| 混合工作流(编码 + 偶尔的重度 AI) | Windows + WSL2 | 便利性 + 良好性能 |
| 多 GPU 工作站(2× 或 4× 5090) | Linux | 驱动稳定性和 PCIe 管理 |
哪些开发者从 RTX 5090 中获益最多?
| 类别 | 是否应购买 RTX 5090? | 主要原因 |
|---|---|---|
| 视频 / 多模态生成 | 强烈推荐 | FP8 + 带宽 = 巨大提升 |
| 扩散模型(SDXL、Flux) | 强烈推荐 | 高分辨率 + 批量扩展 |
| 中规模训练(≤20B) | 强烈推荐 | 更快的迭代,可行的单 GPU 训练 |
| 企业级本地推理 | 强烈推荐 | 更多实例,更高吞吐量 |
| 仅量化 LLM 推理 | 可能不需要 | 相比 4090 优势很小 |
| 预算最大化用户 | 可能不需要 | 4090 / 云 GPU 回报率更高 |
| 多 GPU 训练用户 | 可能不需要 | 需要内存 + 互连,而非原始单卡算力 |
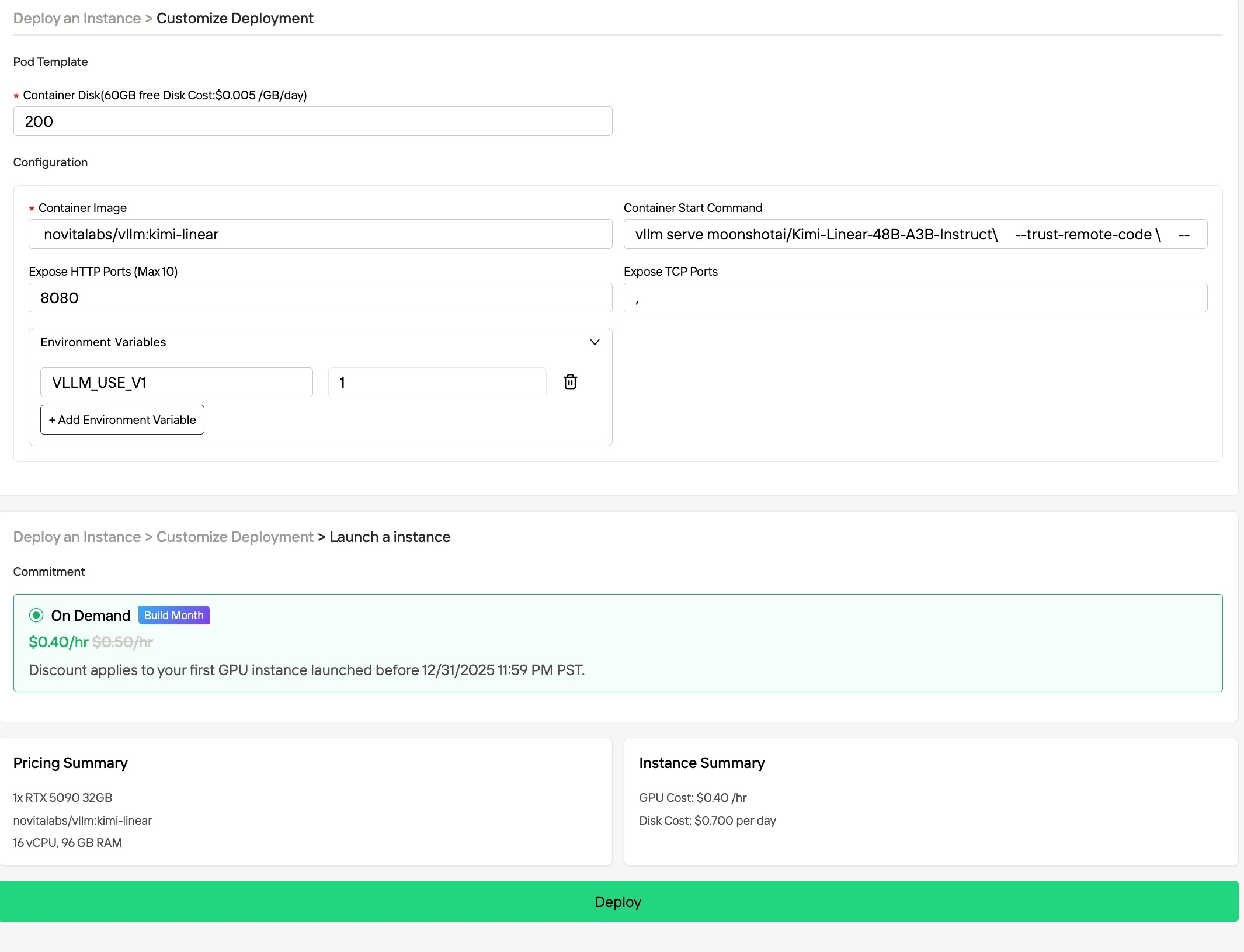
如何以极低价格运行 RTX 5090?
Novita AI 提供基于云的平台,配备高性能 GPU 实例。借助强大的 GPU,确保复杂任务的高效性能,增强跨多种硬件部署的可访问性,并且与维护大规模 AI 部署的本地硬件相比,具有成本效益。
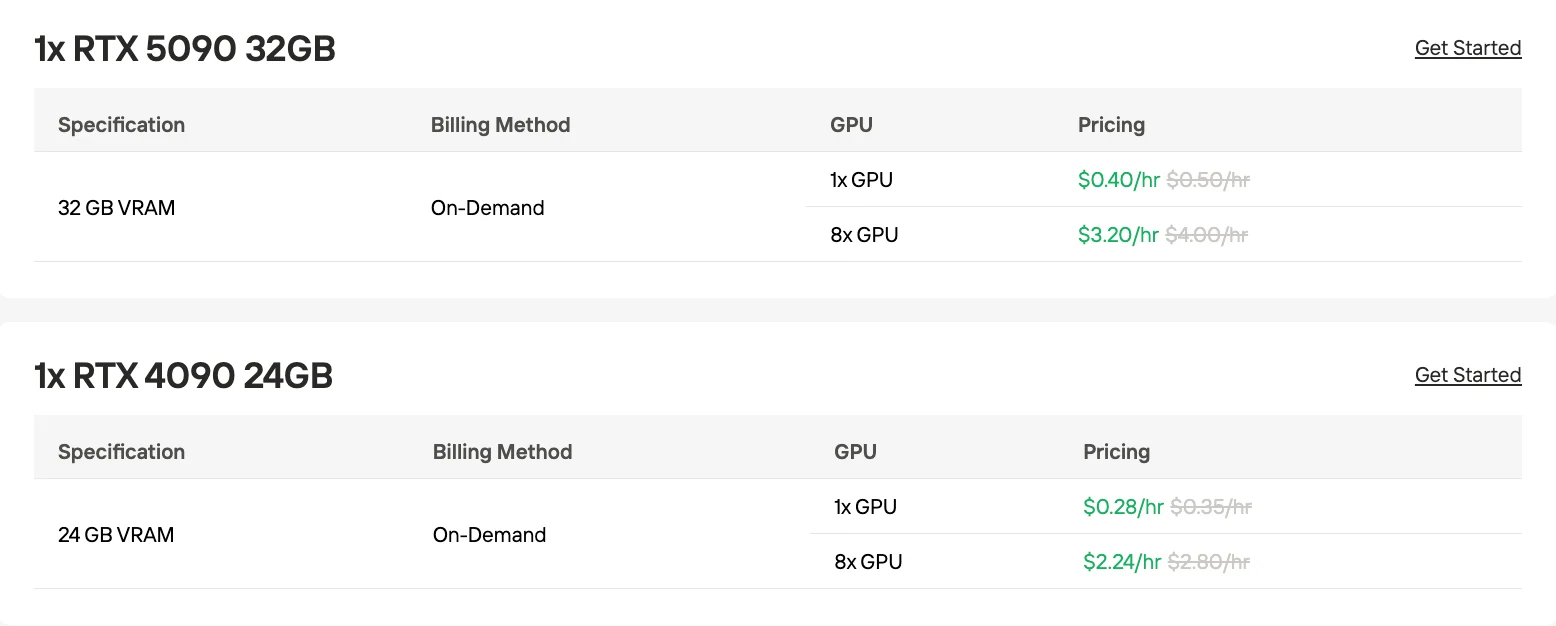
1x RTX4090 GPU:$0.28/小时
8x RTX4090 GPU:$2.24/小时
1x RTX4090 GPU:$0.40/小时
8x RTX4090 GPU:$3.20/小时
Novita AI 正在推出“Build Month”活动,为开发者提供所有主要产品最高 20% 折扣的专属优惠!
第一步:注册账号
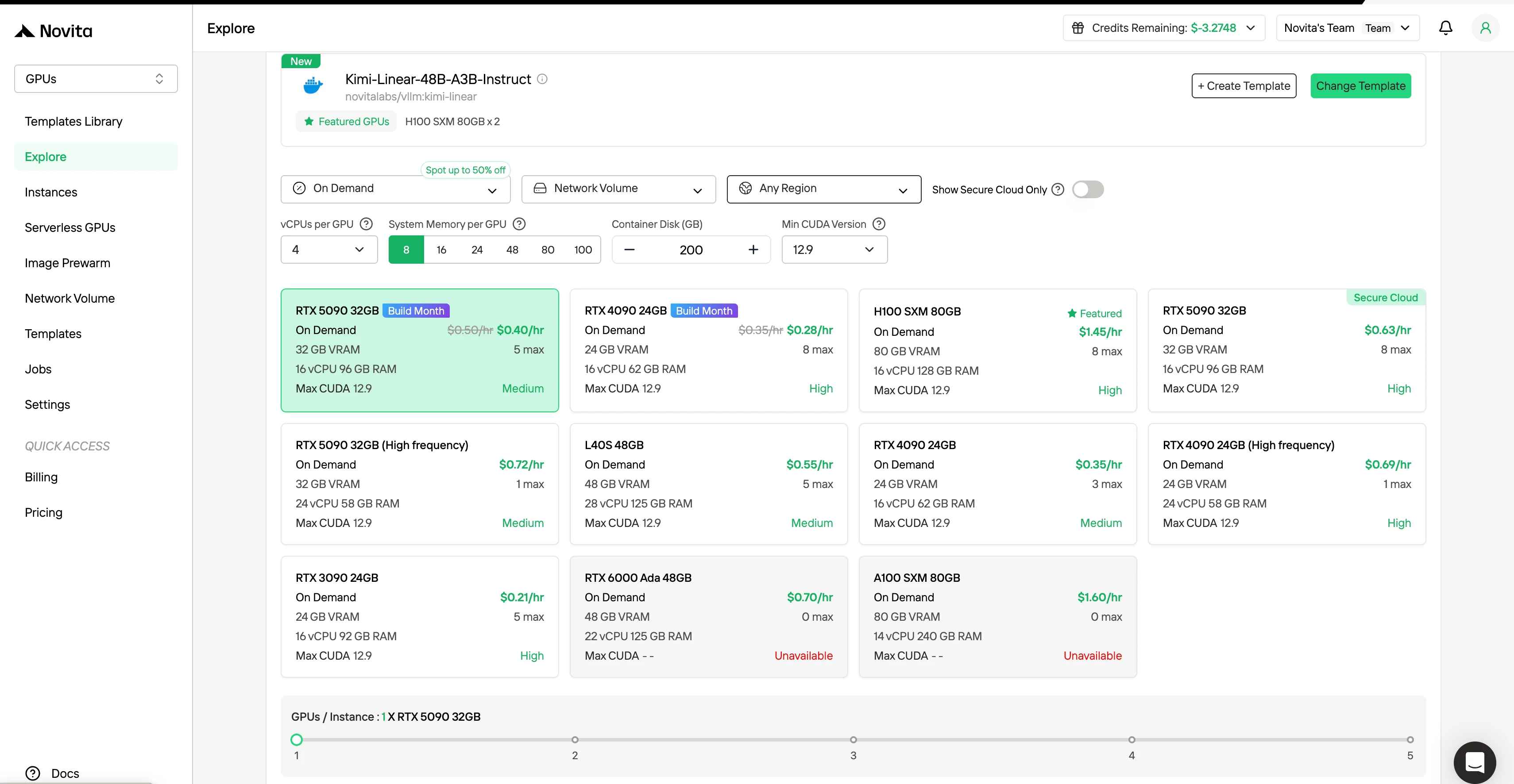
通过我们的网站创建你的 Novita AI 账号。注册后,导航到左侧边栏的“探索”部分,查看我们的 GPU 产品,开始你的 AI 开发之旅。

第二步:探索模板和 GPU 服务器
选择与你的项目需求相匹配的模板,如 PyTorch、TensorFlow 或 CUDA。然后选择你偏好的 GPU 配置——选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每种配置都有不同的 VRAM、RAM 和存储规格。
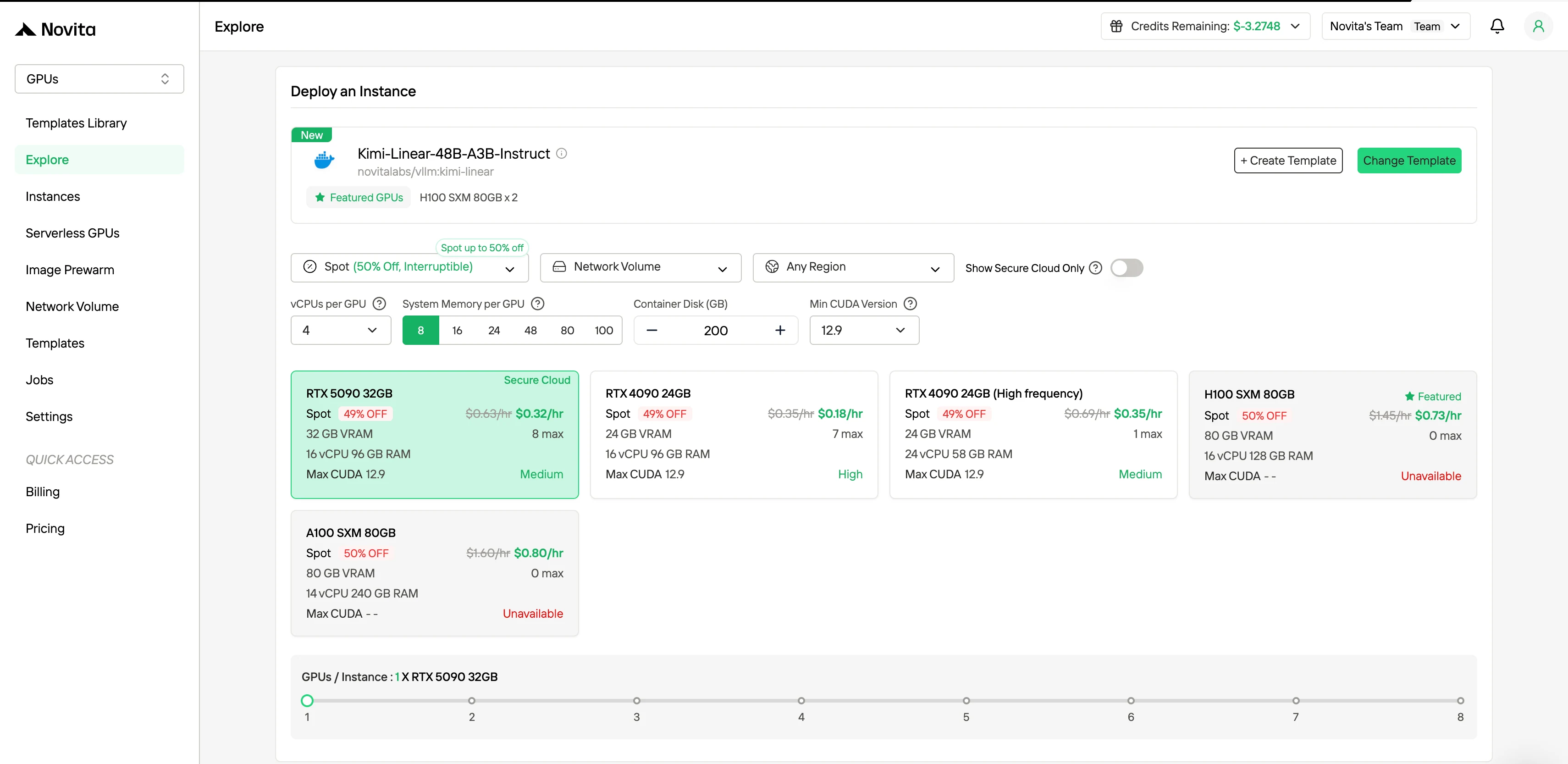
在右侧边栏的“筛选条件”下,你可以将计费方式从“按需”改为“竞价”以查看折扣价格。界面会立即更新,清晰显示 50% 的节省。这种透明度确保你在部署前确切知晓支付金额。
竞价实例支持:
- 保证 1 小时保护期
- 最高节省 50% 成本
- 配置提前 1 小时中断通知
- 预装 AI 框架
第三步:定制部署并启动实例
通过选择偏好的操作系统和配置选项来定制环境,确保针对特定 AI 工作负载和开发需求获得最佳性能。然后,你的高性能 GPU 环境将在几分钟内准备就绪,你可以立即开始机器学习、渲染或计算项目。
RTX 5090 代表了架构上的重大进步,提供了更强的 FP8 吞吐量、显著更高的内存带宽,以及 32GB VRAM 的实用飞跃,从而解锁更大的量化 LLM、高分辨率扩散工作流和中规模训练。然而,其优势取决于配套升级的供电、散热、机箱支持和 PCIe 5.0 带宽。对于专注于视频和多模态生成、SDXL/Flux 扩散或单 GPU 研究训练的开发者,RTX 5090 提供了明确且立即可见的价值。对于优先考虑量化 LLM 推理、多 GPU 扩展或严格成本效益的用户,RTX 4090 或云端部署仍然更合适。借助 Novita AI 提供折扣云实例,开发者无需大量前期投资即可评估 RTX 5090 的性能。
常见问题解答
RTX 5090 在实际工作负载中比 RTX 4090 快多少?
在 7B–13B 模型上,RTX 5090 的 LLM 推理速度比 RTX 4090 大约快 50%,并在 vLLM 中通过 FP8/FP16 加速可达约 3k 令牌/秒(phi-4)。
RTX 5090 的 32GB VRAM 是否改变了开发者的模型运行能力?
是的。RTX 5090 可以加载 49B 甚至 70B Q4 LLM 并以可用速度运行,而 RTX 4090 由于 24GB VRAM 的限制在这些工作负载上力不从心。
哪些工作负载从 RTX 5090 中获益最多?
与 RTX 4090 相比,视频/多模态生成、SDXL/Flux 扩散、中规模 ≤20B 训练以及企业级本地推理在 RTX 5090 上均有显著提升。
Novita AI 是一个 AI 云平台,为开发者提供了通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云,用于构建和扩展应用。
推荐阅读



