

開發者在評估次世代 GPU 時,往往難以判斷 RTX 5090 在真實 AI 工作負載、基礎設施限制與成本層面上,是否能帶來比 RTX 4090 更有意義的優勢。
本文將從三個核心維度解答這個疑問: (1) 由 Blackwell 架構、FP8 加速與 32GB VRAM 帶來的 LLM 推理、擴散模型、多模態生成性能提升; (2) 安全穩定運行 RTX 5090 所需的平台級升級要求; (3) 哪些開發者群體能從升級中獲得最大收益,哪些群體選擇 RTX 4090 或雲端 GPU 性價比更高。
此外,本文還會透過 Linux 與 Windows 系統支援的對比,結合 Novita AI 的低成本存取模式,將 RTX 5090 放在實際部署路徑中進行分析。這些維度將為開發者提供清晰、基於證據的決策框架,幫助你判斷 RTX 5090 是否是你正確的投資選擇。
Novita AI 正在推出「Build Month」活動,為開發者提供所有主力產品最高 20% 的專屬折扣!
RTX 5090 對 AI 工作負載的實際提升幅度有多大?
RTX 5090 在 7B-13B 模型上的 LLM 推理速度比 RTX 4090 快約 50%,搭配 FP8/FP16 加速時,在 vLLM 中運行 phi-4 可達到每秒 3000 tokens 的吞吐量。
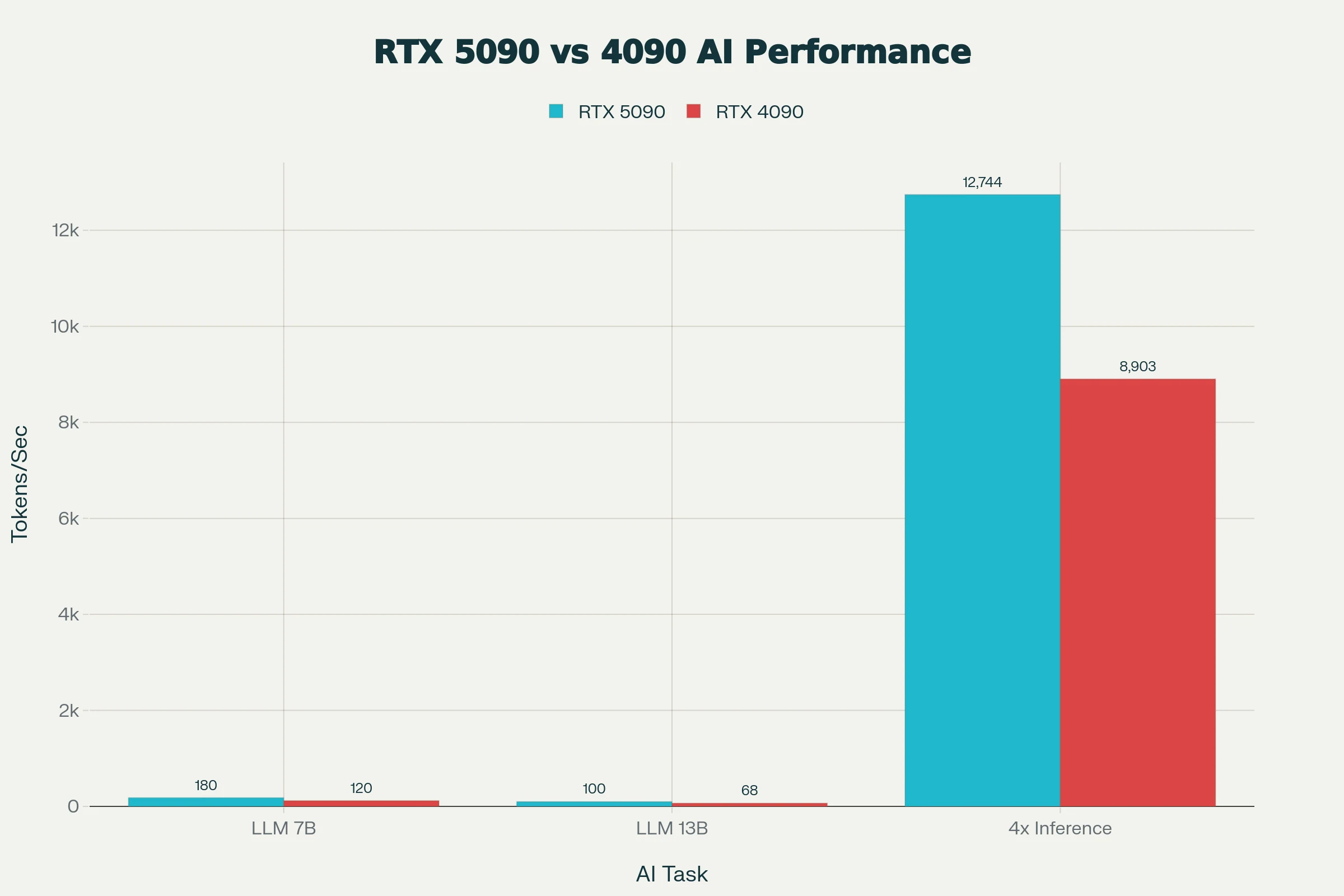
數據來源:AIGPUValue
32GB VRAM 是突破性升級嗎?
其 32GB VRAM 可以完整加載 49B 量化 LLM,相比 RTX 4090 的 24GB VRAM 是質的飛躍,能流暢運行更大尺寸的擴散模型或 70B Q4 量化模型,且速度符合實用標準。
| 規格 | RTX 5090 | RTX 4090 |
|---|---|---|
| 架構 | Blackwell | Ada Lovelace |
| VRAM | 32GB GDDR7 | 24GB GDDR6X |
| 記憶體頻寬 | 1,792 GB/s | 1,008 GB/s |
| CUDA 核心 | 21,760 | 16,384 |
| 張量核心 | 680 | 512 |
| 熱設計功耗(TDP) | 575W | 450W |
| 官方建議售價(MSRP) | $1,999 | $1,599 |
32GB VRAM 能實現的應用場景:
- 以高壓縮量化運行 70B 級 LLM
- 4K-8K 高解析度擴散模型影片工作流
- 無需梯度檢查點的中等規模模型訓練
| GPU | 每分鐘生成圖數 | 提升幅度 |
|---|---|---|
| RTX 5090 | 35 | +59% |
| RTX 4090 | 22 | 基準值 |
目前還無法實現的場景:
- 70B 模型全精度訓練
- 無降頻的多小時高解析度影片生成
開發者要運行 RTX 5090 需要升級哪些硬體?
RTX 5090 並非即插即用替代品,其 575W 的熱設計功耗與 PCIe 5.0 介面需要平台級升級,而非簡單的更換元件。長時間穩定的 AI 工作負載通常需要更高容量的電源供應器、強化散熱方案、優化氣流與結構支撐的機殼,以及足夠的數據通道頻寬。這張顯卡也不支援 NVLink,意味著所有跨 GPU 通信都只能依賴 PCIe,這會限制訓練的擴展效率,並在多 GPU 環境中加劇熱堆疊問題。
必須升級的硬體清單
- 1000-1200W 電源供應器(符合 ATX 3.1 / PCIe 5.1 規範,配備 12V-2x6 介面)
- 高容量散熱系統(大型風冷散熱器或水冷)
- 配備強化 PCIe 插槽與強勁氣流設計的機殼
- 主機板上的 PCIe 5.0 x16 主插槽
- 64-128GB DDR5 記憶體(用於支援 LLM 工作負載的離載運行)
- Gen4/Gen5 規格 NVMe SSD(用於模型儲存)
1. 供電需求
建議搭配 1000-1200W 電源供應器,以應對持續高負載與瞬態功耗峰值。80+ Gold 或 Platinum 級別的能效認證可以降低發熱與長期運營成本。12V-2x6 介面必須安裝應力消除配件,因為介面過熱與機械應力是常見問題,尤其在顯卡垂直安裝的場景中。

2. 散熱與機殼整合
RTX 5090 需要搭配大型雙槽或三槽散熱器,或使用水冷方案。多 GPU 配置下的熱密度會急劇上升,因此消費級塔式機殼通常無法勝任。建議選擇配備網孔面板、強化顯卡插槽與強勁氣流路徑的機殼,若組建 2 張或 4 張 RTX 5090 的陣列,推薦使用伺服器或工作站機殼。

3. 儲存需求
高速 NVMe SSD(Gen4/Gen5 規格,讀取速度約 7GB/s 級別)可以加速初始模型加載與數據集洗牌。儲存速度不會影響每秒生成的 token 數,但會大幅提升重複加載模型時的工作流響應速度。

現有開發框架是否已支援 RTX 5090?
1. 如果你的目標是 AI 開發、模型訓練或大模型推理,優先選擇 Linux 系統
- CUDA 驅動程式發布速度最快、穩定性最高
- 與 PyTorch、TensorFlow、JAX、vLLM、TensorRT-LLM 等框架的相容性最佳
- FP8、BF16 與 Blackwell 架構優化都會優先登陸 Linux 平台
- ROCm 與 oneAPI 的支援也在 Linux 平台上最完善
- 多 GPU 擴展、PCIe 通道管理與 NVLink 替代方案的可靠性更高
2. 如果你的需求是日常桌面使用 + AI 推理 + 操作便捷,選擇 Windows 11 系統
- 安裝最簡單(驅動、應用程式、使用者介面都易於配置)
- 原生 CUDA 支援完善
- 第三方圖形化工具(LM Studio、ComfyUI、A1111、Ollama Windows 版本)運行流暢
- 非常適合不進行研究級開發的用戶
相比 Linux 的劣勢:
- TensorRT-LLM、FP8 優化與高級核心的更新會更晚推送
- 因驅動差異,多 GPU 配置穩定性較低
- 極端場景(I/O 瓶頸、PCIe 飽和)下性能更低
| 使用場景 | 最佳系統 | 原因 |
|---|---|---|
| 大模型 LLM(30B-70B)、FP8 流程、模型訓練、vLLM 推理 | Linux | CUDA 效能最強、穩定性最高、生態系優先支援 |
| 單卡推理、Stable Diffusion、圖形化工具使用 | Windows | 操作最簡單、圖形化工具支援最全面 |
| 混合工作流(編程 + 偶爾執行重型 AI 任務) | Windows + WSL2 | 兼顧便捷性與不錯的效能 |
| 多 GPU 工作站(2 張或 4 張 RTX 5090) | Linux | 驅動穩定、PCIe 管理更完善 |
哪些開發者最適合升級 RTX 5090?
| 開發者類型 | 是否建議購買 RTX 5090? | 核心原因 |
|---|---|---|
| 影片/多模態生成 | 強烈推薦 | FP8 + 高記憶體頻寬帶來的提升幅度極大 |
| 擴散模型(SDXL、Flux) | 強烈推薦 | 高解析度生成與批次縮放的優勢明顯 |
| 中等規模訓練(≤20B 參數量) | 強烈推薦 | 迭代速度更快,單卡訓練可行 |
| 企業本地推理部署 | 強烈推薦 | 可運行更多實例、吞吐量更高 |
| 僅需運行量化 LLM 推理 | 大概率不需要 | 相較 RTX 4090 提升極小 |
| 預算優先的開發者 | 大概率不需要 | RTX 4090 或雲端部署性價比更高 |
| 多 GPU 訓練用戶 | 大概率不需要 | 訓練需求更依賴記憶體容量與互連頻寬,而非單卡原始運算效能 |
如何以極低成本使用 RTX 5090?
Novita AI 提供基於雲端的高效能 GPU 實例平台。憑藉強勁的 GPU 算力,它能確保複雜任務的執行效率,降低各類硬體的部署門檻,相比自建本地硬體用於大規模 AI 部署,成本效益更高。
1 張 RTX 4090 GPU:每小時 0.28 美元
8 張 RTX 4090 GPU:每小時 2.24 美元
1 張 RTX 4090 GPU:每小時 0.40 美元
8 張 RTX 4090 GPU:每小時 3.20 美元
Novita AI 正在推出「Build Month」活動,為開發者提供所有主力產品最高 20% 的專屬折扣!
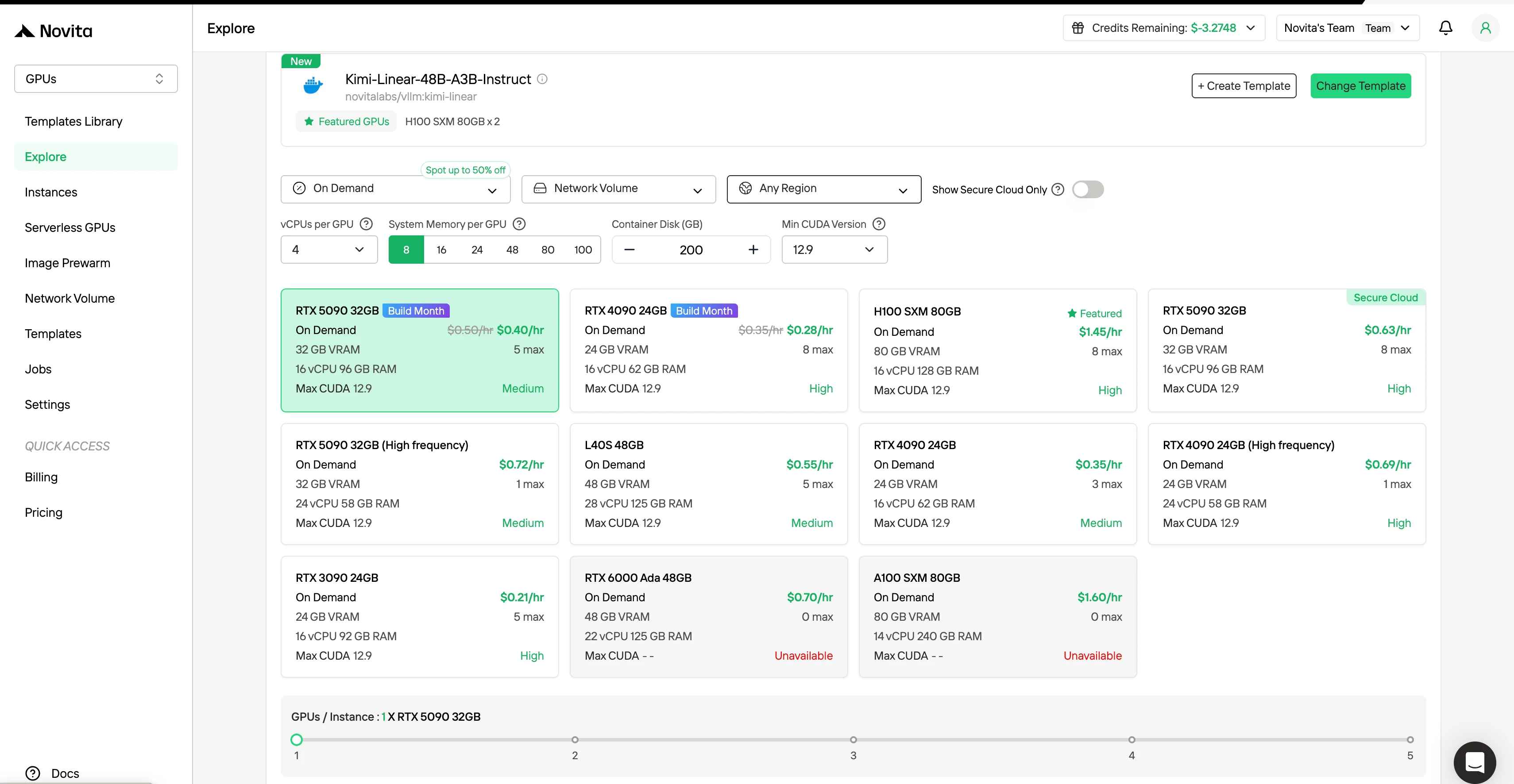
步驟1:註冊帳號 透過我們的官方網站建立 Novita AI 帳號,註冊完成後,在左側導航欄進入「Explore」頁面,即可查看我們提供的 GPU 資源,開啟你的 AI 開發之旅。

步驟2:選擇模板與 GPU 伺服器 根據專案需求選擇對應的模板,例如 PyTorch、TensorFlow 或 CUDA 模板。之後選擇你偏好的 GPU 配置,可選規格包括強勁的 L40S、RTX 4090 或 A100 SXM4,每種配置的 VRAM、記憶體與儲存規格各不相同。
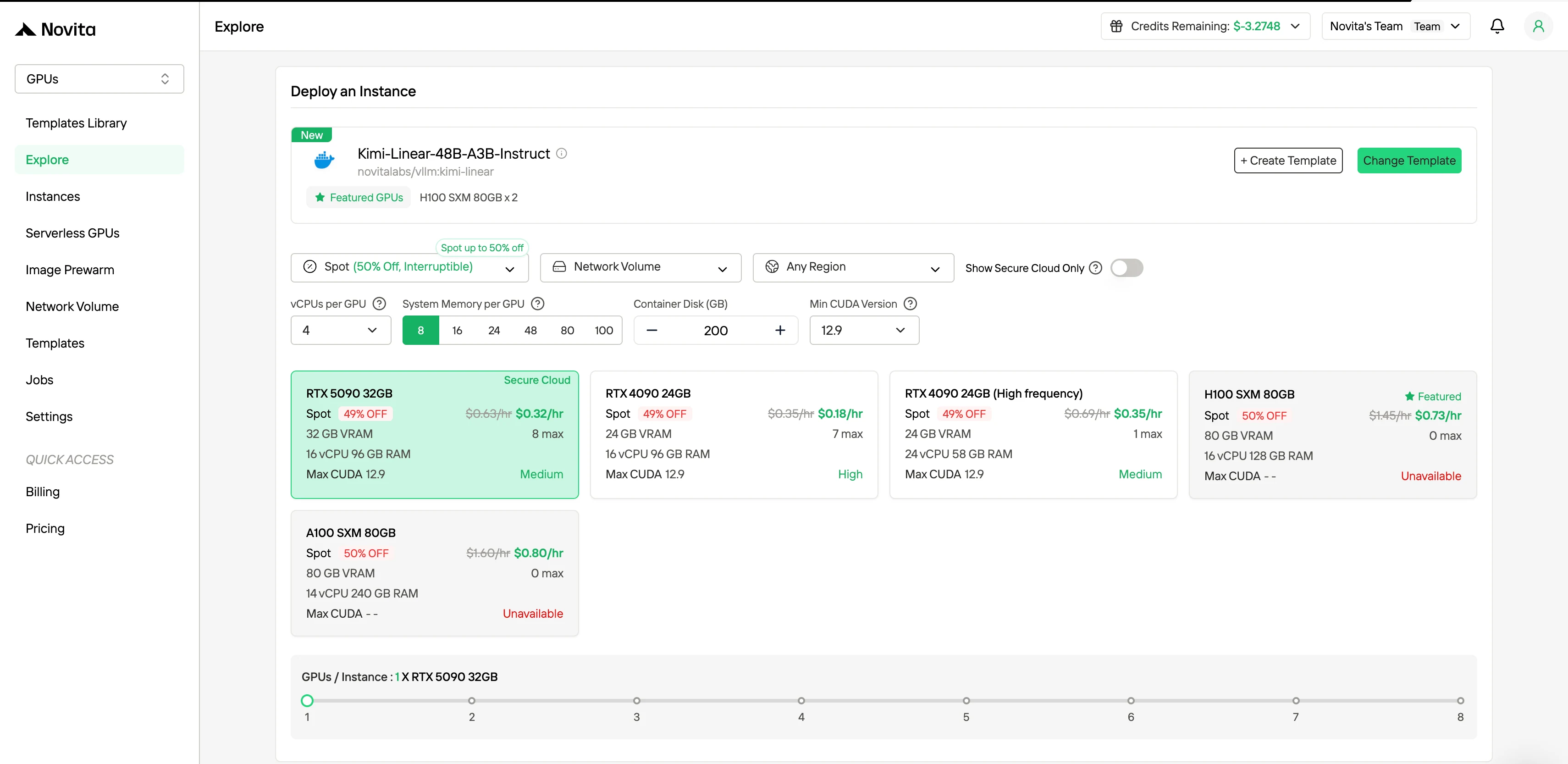
在右側導航欄的 Filter 選項中,你可以將計費方式從「On-Demand」切換為「Spot」,即可查看折扣後的價格。介面會即時更新,清晰標註 50% 的優惠幅度。這種透明的計費方式能讓你在部署前清楚了解所需費用。
Spot 實例支援:
- 1 小時保護期保證
- 最高可享 50% 費用優惠
- 預設配置 1 小時提前中斷通知
- 預裝 AI 框架,開箱即用
步驟3:自訂部署配置並啟動實例 根據你的 AI 工作負載與開發需求,選擇合適的作業系統與配置選項,確保效能達到最優化。完成配置後,你的高效能 GPU 環境將在幾分鐘內準備就緒,你可以立即開始機器學習、渲染或計算類專案。
RTX 5090 帶來了架構層面的重大升級,擁有更強的 FP8 吞吐量、更高的記憶體頻寬,以及實用性極強的 32GB VRAM,能支援更大規模的量化 LLM、高解析度擴散模型工作流與中等規模訓練。但這些優勢需要配套升級供電、散熱、機殼支援與 PCIe 5.0 頻寬才能發揮。對於專注於影片與多模態生成、SDXL/Flux 擴散模型、或單卡研究訓練的開發者來說,RTX 5090 能帶來清晰且即時的價值。而對於優先考慮量化 LLM 推理、多 GPU 擴展或嚴格成本控制的用戶,RTX 4090 或雲端部署仍是更合適的選擇。透過 Novita AI 的折扣雲端實例,開發者無需投入大量前期成本,即可評估 RTX 5090 的實際效能。
常見問題
RTX 5090 在實際工作負載中比 RTX 4090 快多少? 在 7B-13B 參數量的模型上,RTX 5090 的 LLM 推理速度比 RTX 4090 快約 50%,搭配 FP8/FP16 加速時,在 vLLM 中運行 phi-4 可達到約 3000 tokens/s 的吞吐量。
RTX 5090 的 32GB VRAM 是否改變了開發者可運行的模型範圍? 是的。RTX 5090 可以流暢加載 49B 甚至 70B Q4 量化版本的 LLM,而 RTX 4090 受限於 24GB 的 VRAM,無法在可接受的速度下運行這些模型。
哪些工作負載能從 RTX 5090 獲得最大收益? 影片/多模態生成、SDXL/Flux 擴散模型、≤20B 參數量的中等規模訓練,以及企業本地推理部署,在 RTX 5090 上的表現都遠優於 RTX 4090。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面部署 AI 模型,同時提供平價、可靠的 GPU 雲端服務,用於 AI 模型的構建與擴展。
推薦閱讀



