

At Novita AI, we’re committed to providing developers fast, reliable, and affordable access to the top AI models. When OpenAI released its open-source models, GPT-OSS 120B and 20B, we hosted both on the same day. But simply deploying a model isn’t enough. That’s why our engineering team dedicated an entire week to one goal: optimizing our GPT-OSS endpoints to deliver exceptional user experience.
The result? Our endpoint has been ranked as a top performer in the industry, validated by Artificial Analysis, an independent analysis platform of AI models and hosting providers.

Title: GPT OSS 120B
Source: Hugging Face
What Is GPT-OSS-120B?
GPT-OSS-120B is one of OpenAI’s new open-weight models released in August 2025, featuring a mixture-of-experts (MoE) design with 117 billion parameters. It only activates a subset of those parameters per token, enabling efficient inference while preserving strong reasoning capabilities. This model supports advanced features like tool usage, extended context windows, and complex reasoning, all under an Apache 2.0 license.
The Challenge: A Balancing Act
Hosting LLMs like GPT-OSS 120B requires balancing multiple metrics at once. We had to optimize for several key metrics simultaneously:
- Latency: How quickly does the model respond to a user’s request? Low latency, especially time to first token, is crucial for a good conversational user experience.
- Throughput: How many tokens per second can our endpoint handle? High throughput ensures speed which directly impacts user experience.
- Context Window: Can the model handle long, complex prompts? The GPT-OSS models have a massive 131,072 token context window, and we needed to ensure our deployment fully supports its capabilities.
- Model Quality: Does our optimization preserve the model’s core capabilities, such as function calling (also known as tool calling) and Structured/JSON Outputs? We enabled reasoning and made sure our deployment didn’t introduce errors or compromise the model’s accuracy/reasoning abilities.
The Results: What We Achieved
Our hard work paid off. Novita’s endpoint earned a high ranking in the Artificial Analysis GPT-OSS-120B (high) API Provider Performance Benchmarking & Analysis Report. We were recognized as the top performer on the AIME (American Invitational Mathematics Examination) and GPQA (Graduate-Level Google-Proof Q&A) reasoning benchmarks. Novita delivered some of the highest accuracy scores, and to top it all off, our costs were among the lowest.
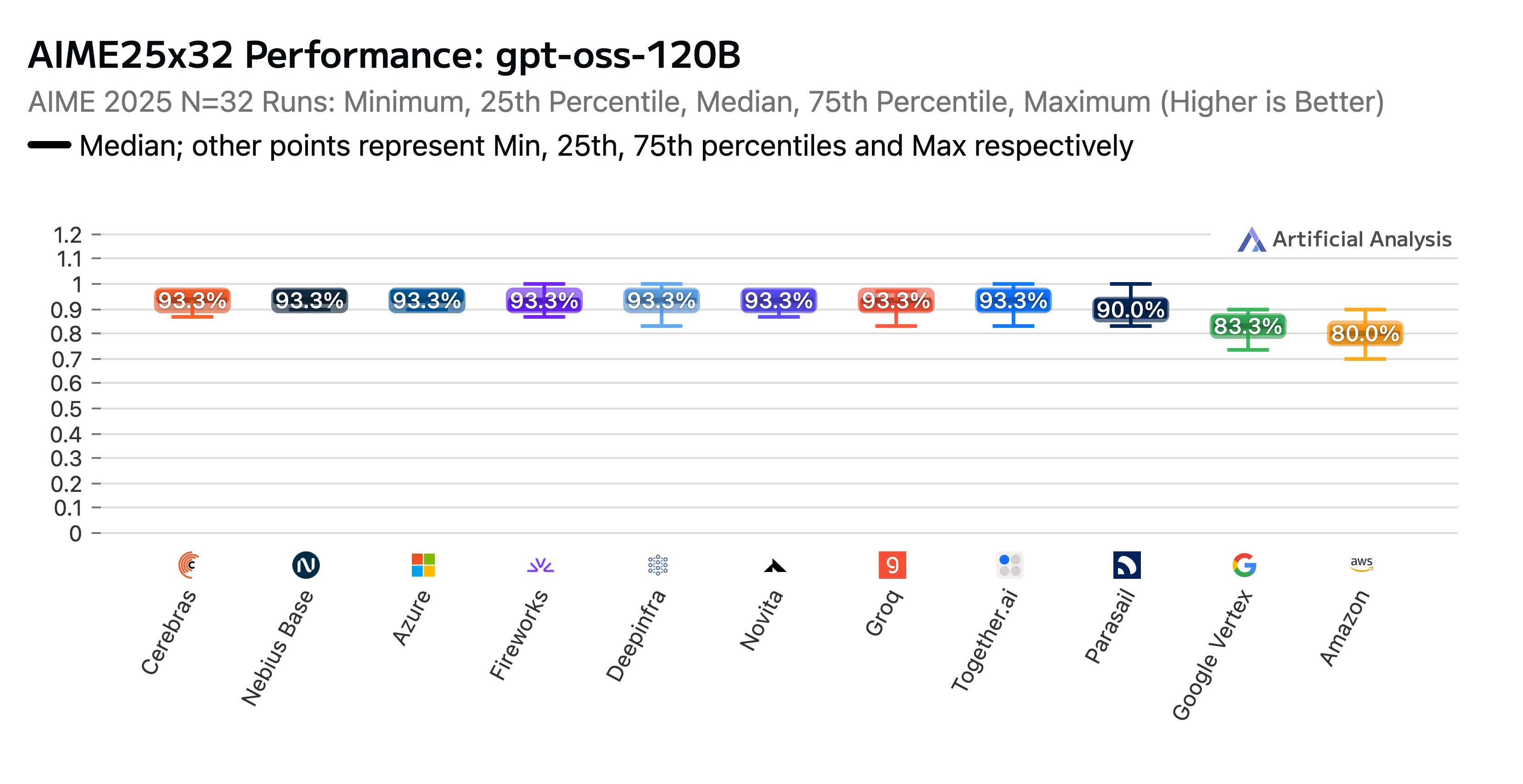
Title: GPTOSS 120B AIME25x32 Performance Rankings by LLM Provider
Source: Artificial Analysis
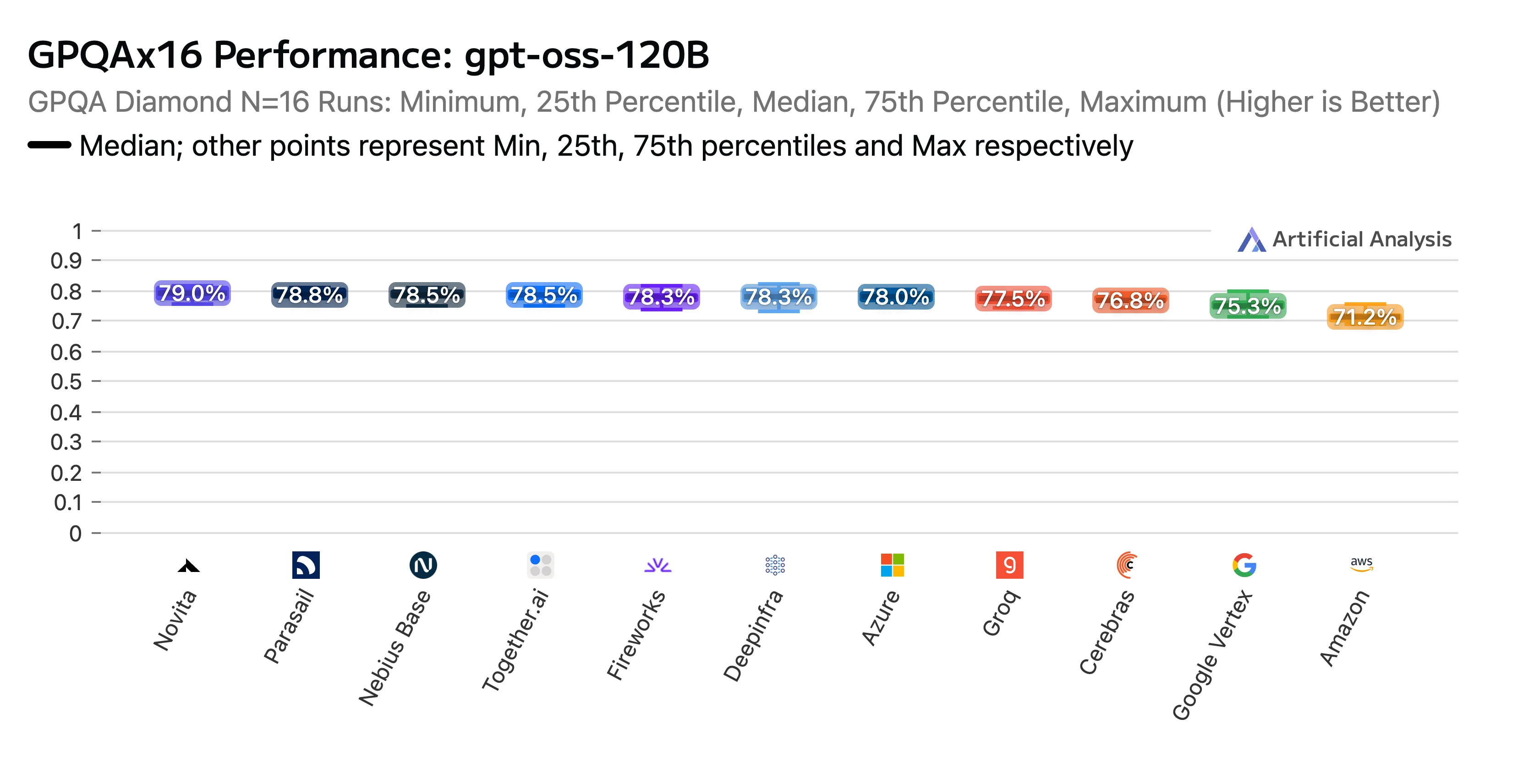
Title: GPTOSS 120B GPQAx16 Performance Rankings by LLM Provider
Source: Artificial Analysis
The report also highlighted our competitive pricing and speed:
- Context Window: Our endpoint fully supports the model’s impressive 131k token context window
- Total end-to-end response time: 11.11 seconds
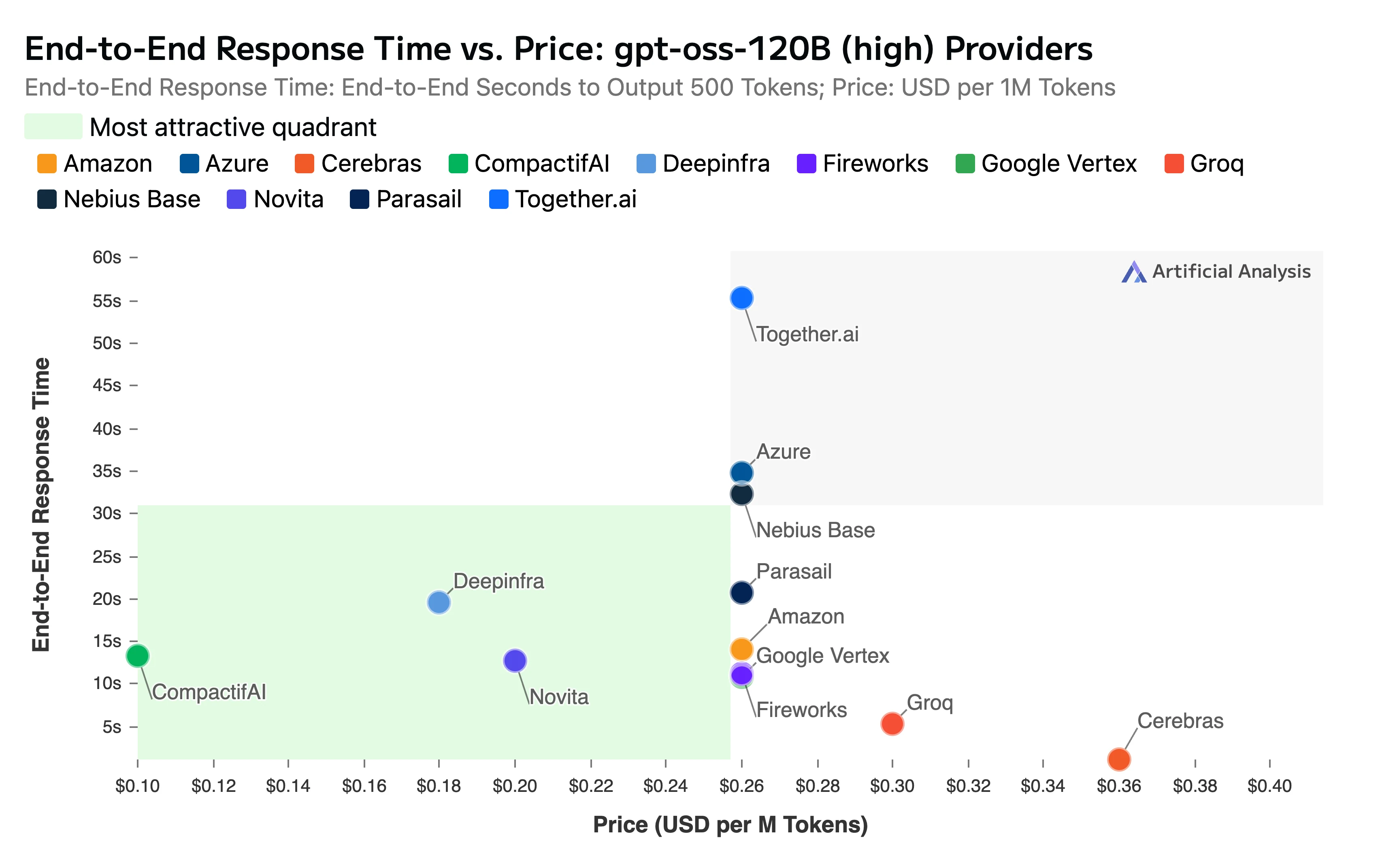
Title: End-to-End Response Time vs Price
Source: Artificial Analysis
- Blended Price: $0.20 per million tokens, with input tokens priced at $0.10/M and output tokens at $0.50/M
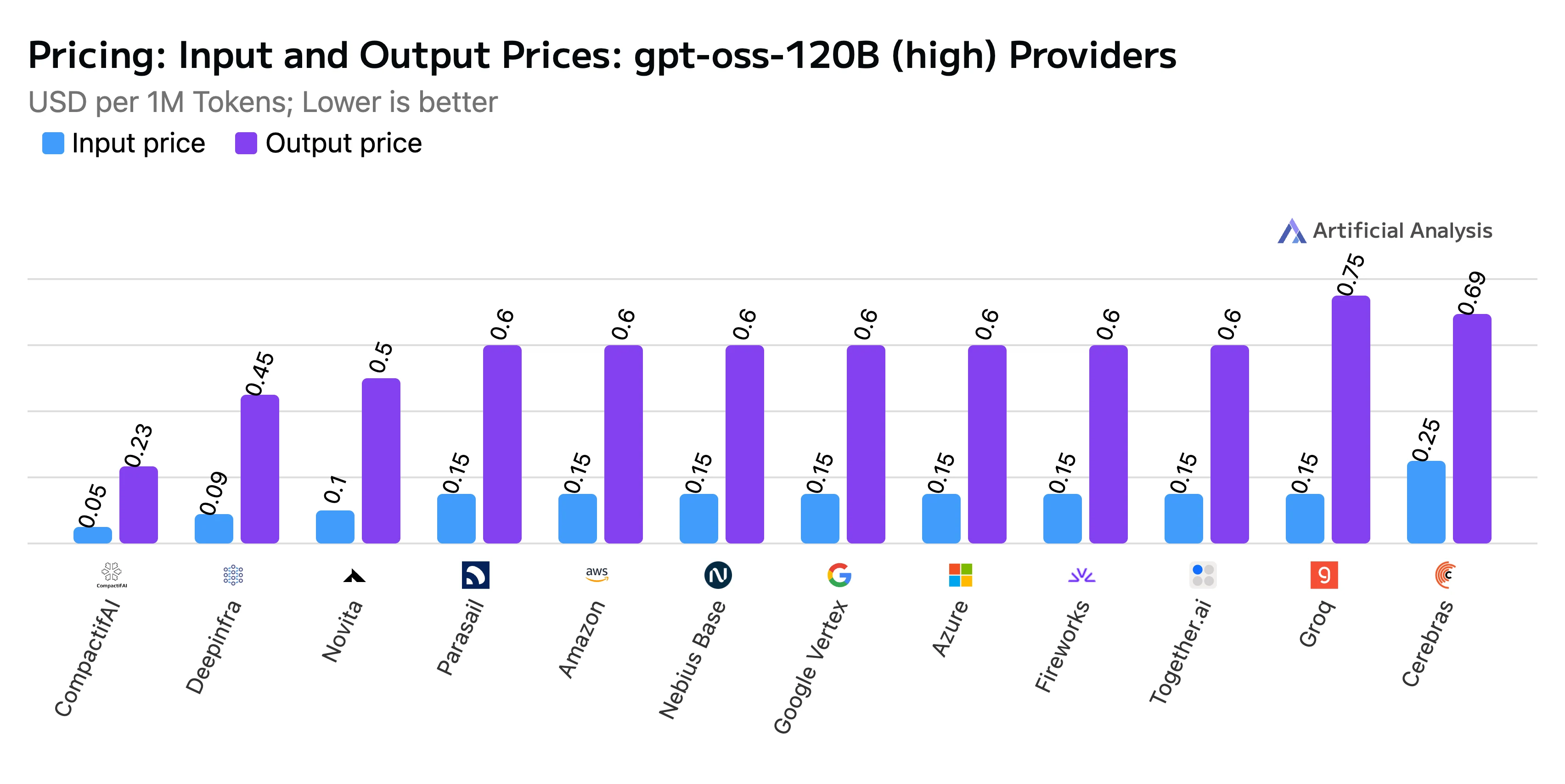
Title: Input and Output Price Comparison
Source: Artificial Analysis
We’re proud to bring this level of performance to the open source community and are excited to see what our users build with the power of an optimized GPT-OSS.



