

在 Novita AI,我们致力于为开发者提供快速、可靠且价格合理的顶级 AI 模型访问。当 OpenAI 发布其开源模型 GPT-OSS 120B 和 20B 时,我们在同一天就完成了托管。但仅仅部署一个模型还不够。因此,我们的工程团队投入了整整一周的时间来完成一个目标:优化我们的 GPT-OSS 端点,以提供卓越的用户体验。
结果如何?我们的端点被行业权威独立分析平台 Artificial Analysis 评为顶级性能提供商之一。

标题:GPT OSS 120B
来源:Hugging Face
什么是 GPT-OSS-120B?
GPT-OSS-120B 是 OpenAI 于 2025 年 8 月发布的新开放权重模型之一,采用混合专家(MoE)设计,拥有 1170 亿参数。它每个 token 仅激活部分参数,从而实现高效推理同时保持强大的推理能力。该模型支持工具使用、扩展上下文窗口和复杂推理等高级功能,并基于 Apache 2.0 许可证发布。
挑战:多目标权衡
托管像 GPT-OSS 120B 这样的大语言模型需要同时平衡多个指标。我们必须同时优化以下几个关键指标:
- 延迟: 模型响应用户请求的速度有多快?低延迟,尤其是首 token 时间,对于良好的对话用户体验至关重要。
- 吞吐量: 我们的端点每秒能处理多少 token?高吞吐量确保速度,直接影响用户体验。
- 上下文窗口: 模型能否处理长而复杂的提示词?GPT-OSS 模型拥有 131,072 个 token 的超大上下文窗口,我们需要确保部署完全支持其能力。
- 模型质量: 我们的优化是否保留了模型的核心能力,如函数调用(也称为工具调用)和结构化/JSON 输出?我们启用了推理功能,并确保部署不会引入错误或损害模型的准确性和推理能力。
成果:我们取得的成就
我们的辛勤工作得到了回报。Novita 的端点在 Artificial Analysis 的 GPT-OSS-120B(高)API 提供商性能基准测试与分析报告 中获得了高排名。我们在 AIME(美国数学邀请赛) 和 GPQA(研究生级谷歌证明问答) 推理基准测试中被公认为顶级表现者。Novita 提供了最高的准确率分数,更棒的是,我们的成本也处于最低水平。
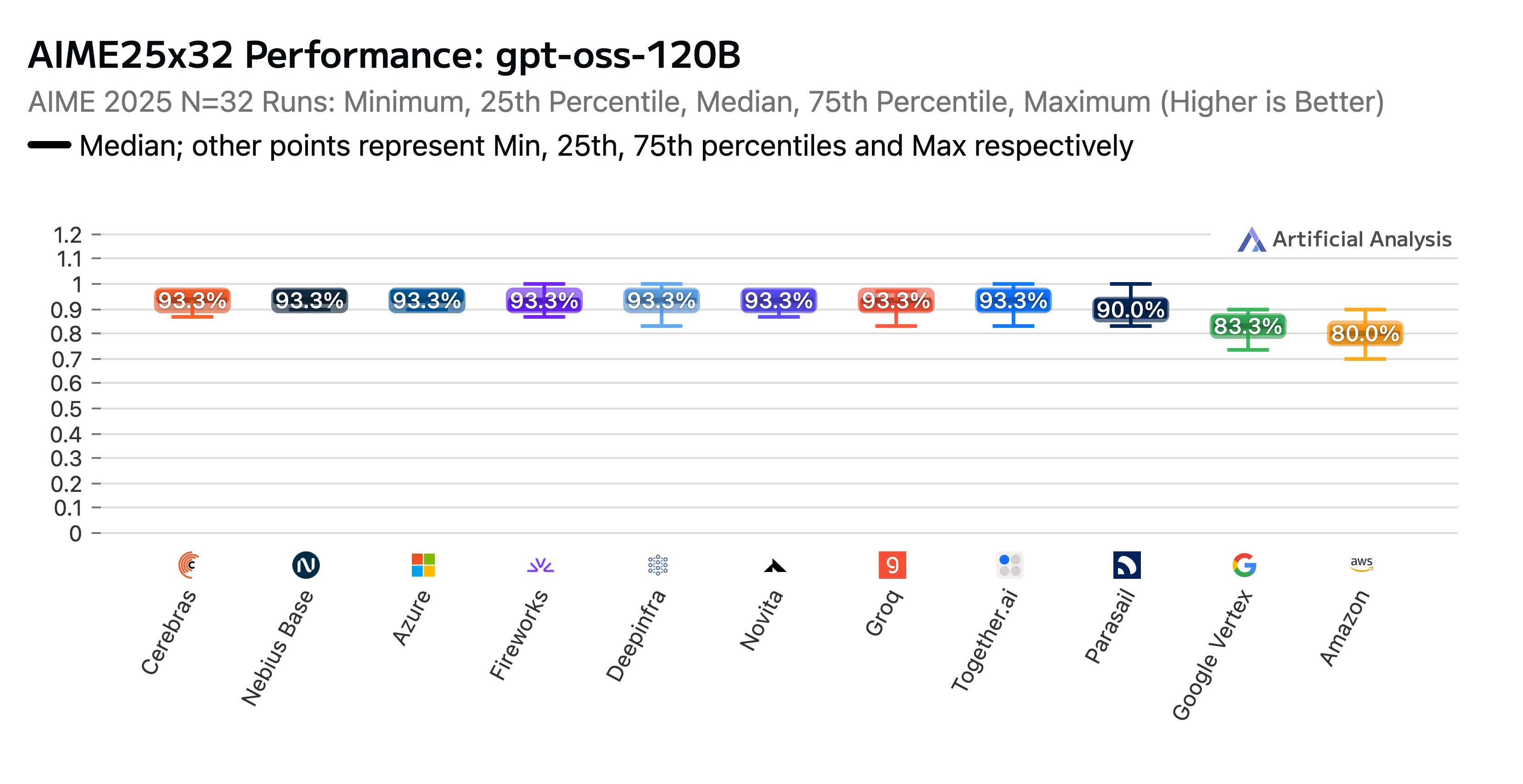
标题:GPTOSS 120B AIME25x32 性能排名(按 LLM 提供商)
来源:Artificial Analysis
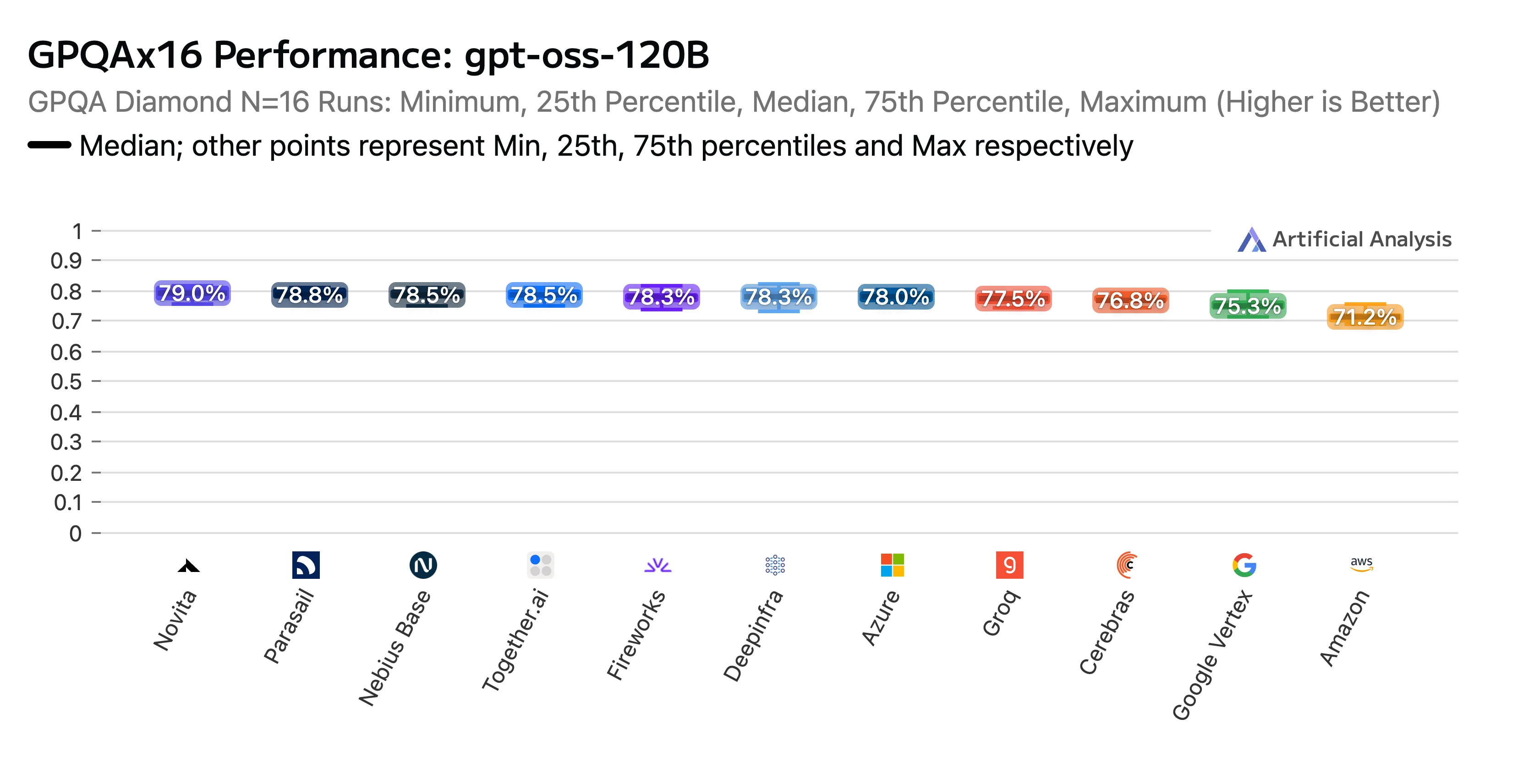
标题:GPTOSS 120B GPQAx16 性能排名(按 LLM 提供商)
来源:Artificial Analysis
该报告还强调了我们的竞争性定价和速度:
- 上下文窗口: 我们的端点完全支持模型令人印象深刻的 131k token 上下文窗口
- 端到端总响应时间: 11.11 秒
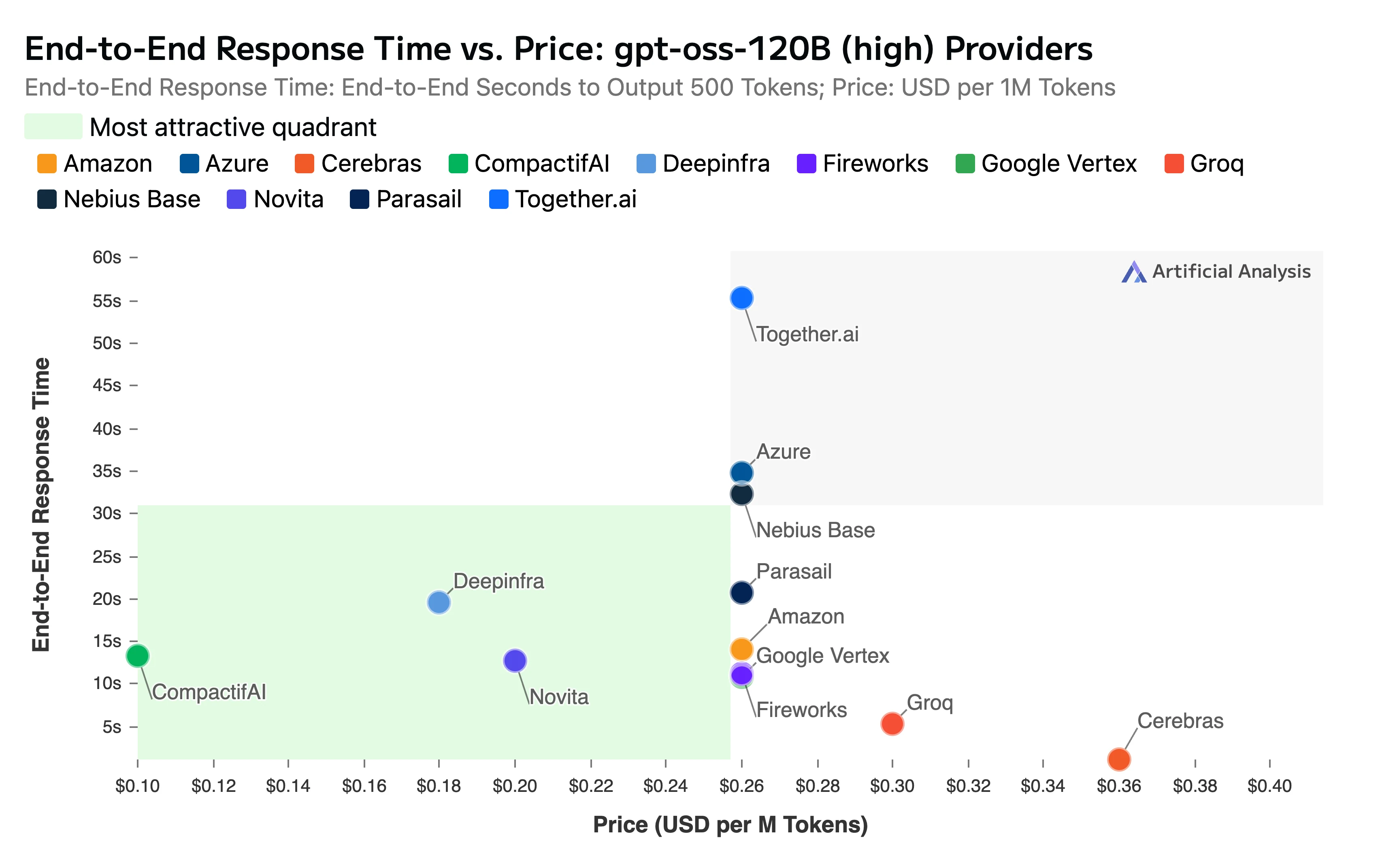
标题:端到端响应时间 vs 价格
来源:Artificial Analysis
- 混合价格: 每百万 token 0.20 美元,其中输入 token 价格为 0.10 美元/M,输出 token 价格为 0.50 美元/M
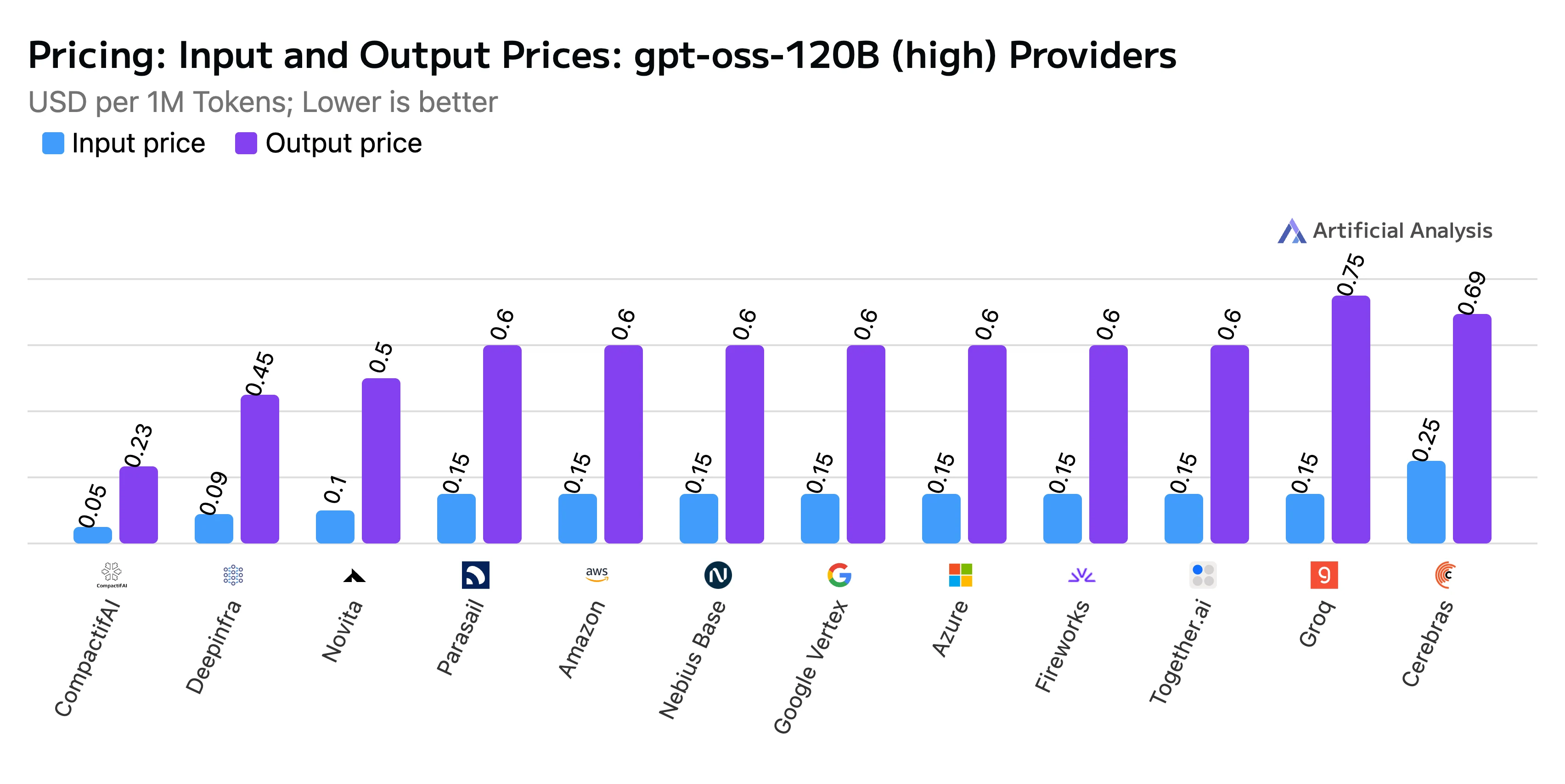
标题:输入和输出价格对比
来源:Artificial Analysis
我们很自豪能为开源社区带来如此级别的性能,并期待看到我们的用户利用优化的 GPT-OSS 构建出怎样的成果。



