

En Novita AI, nos comprometemos a ofrecer a los desarrolladores acceso rápido, fiable y asequible a los mejores modelos de IA. Cuando OpenAI lanzó sus modelos de código abierto, GPT-OSS 120B y 20B, los alojamos el mismo día. Pero simplemente desplegar un modelo no es suficiente. Por eso, nuestro equipo de ingeniería dedicó una semana completa a un objetivo: optimizar nuestros endpoints de GPT-OSS para ofrecer una experiencia de usuario excepcional.
¿El resultado? Nuestro endpoint ha sido clasificado como uno de los mejores de la industria, validado por Artificial Analysis, una plataforma independiente de análisis de modelos de IA y proveedores de alojamiento.

Título: GPT OSS 120B
Fuente: Hugging Face
¿Qué es GPT-OSS-120B?
GPT-OSS-120B es uno de los nuevos modelos de pesos abiertos de OpenAI lanzados en agosto de 2025, que presenta un diseño de mezcla de expertos (MoE) con 117 mil millones de parámetros. Solo activa un subconjunto de esos parámetros por token, lo que permite una inferencia eficiente y conserva sólidas capacidades de razonamiento. Este modelo admite funciones avanzadas como el uso de herramientas, ventanas de contexto extendidas y razonamiento complejo, todo bajo una licencia Apache 2.0.
El desafío: un acto de equilibrio
Alojar LLMs como GPT-OSS 120B requiere equilibrar múltiples métricas a la vez. Tuvimos que optimizar varios indicadores clave simultáneamente:
- Latencia: ¿Qué tan rápido responde el modelo a la solicitud de un usuario? La baja latencia, especialmente el tiempo hasta el primer token, es crucial para una buena experiencia conversacional.
- Rendimiento: ¿Cuántos tokens por segundo puede manejar nuestro endpoint? Un alto rendimiento garantiza velocidad, lo que impacta directamente en la experiencia del usuario.
- Ventana de contexto: ¿Puede el modelo manejar indicaciones largas y complejas? Los modelos GPT-OSS tienen una ventana de contexto masiva de 131,072 tokens, y necesitábamos asegurarnos de que nuestro despliegue soportara completamente sus capacidades.
- Calidad del modelo: ¿Nuestra optimización preserva las capacidades principales del modelo, como la llamada a funciones (también conocida como tool calling) y las salidas estructuradas/JSON? Activamos el razonamiento y nos aseguramos de que nuestro despliegue no introdujera errores ni comprometiera la precisión o las habilidades de razonamiento del modelo.
Los resultados: lo que logramos
Nuestro arduo trabajo dio frutos. El endpoint de Novita obtuvo una alta clasificación en el informe de Artificial Analysis GPT-OSS-120B (high) API Provider Performance Benchmarking & Analysis Report. Fuimos reconocidos como el mejor en los benchmarks de razonamiento AIME (American Invitational Mathematics Examination) y GPQA (Graduate-Level Google-Proof Q&A) . Novita obtuvo algunas de las puntuaciones de precisión más altas y, para rematar, nuestros costos estuvieron entre los más bajos.
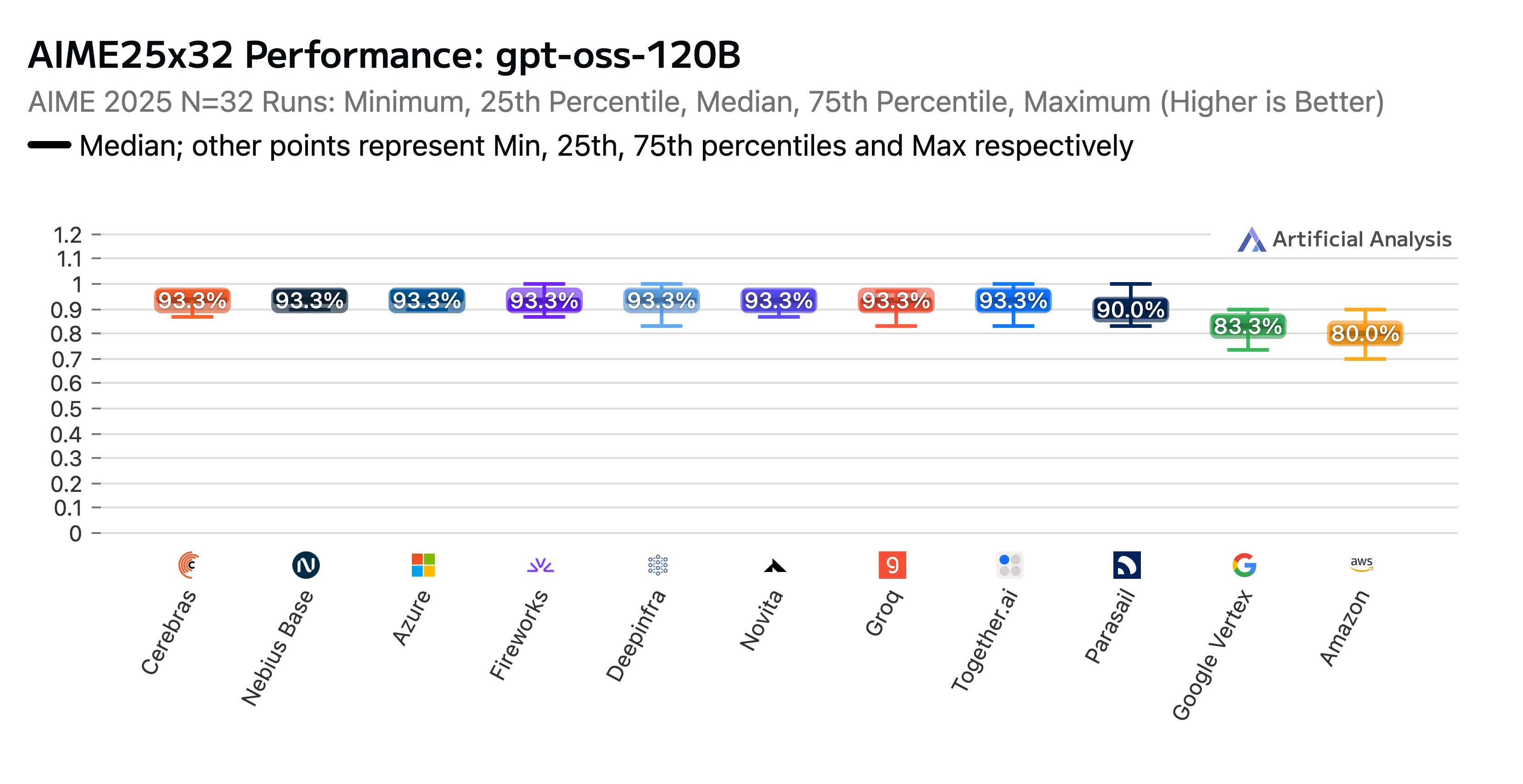
Título: Ranking de rendimiento GPTOSS 120B AIME25x32 por proveedor de LLM
Fuente: Artificial Analysis
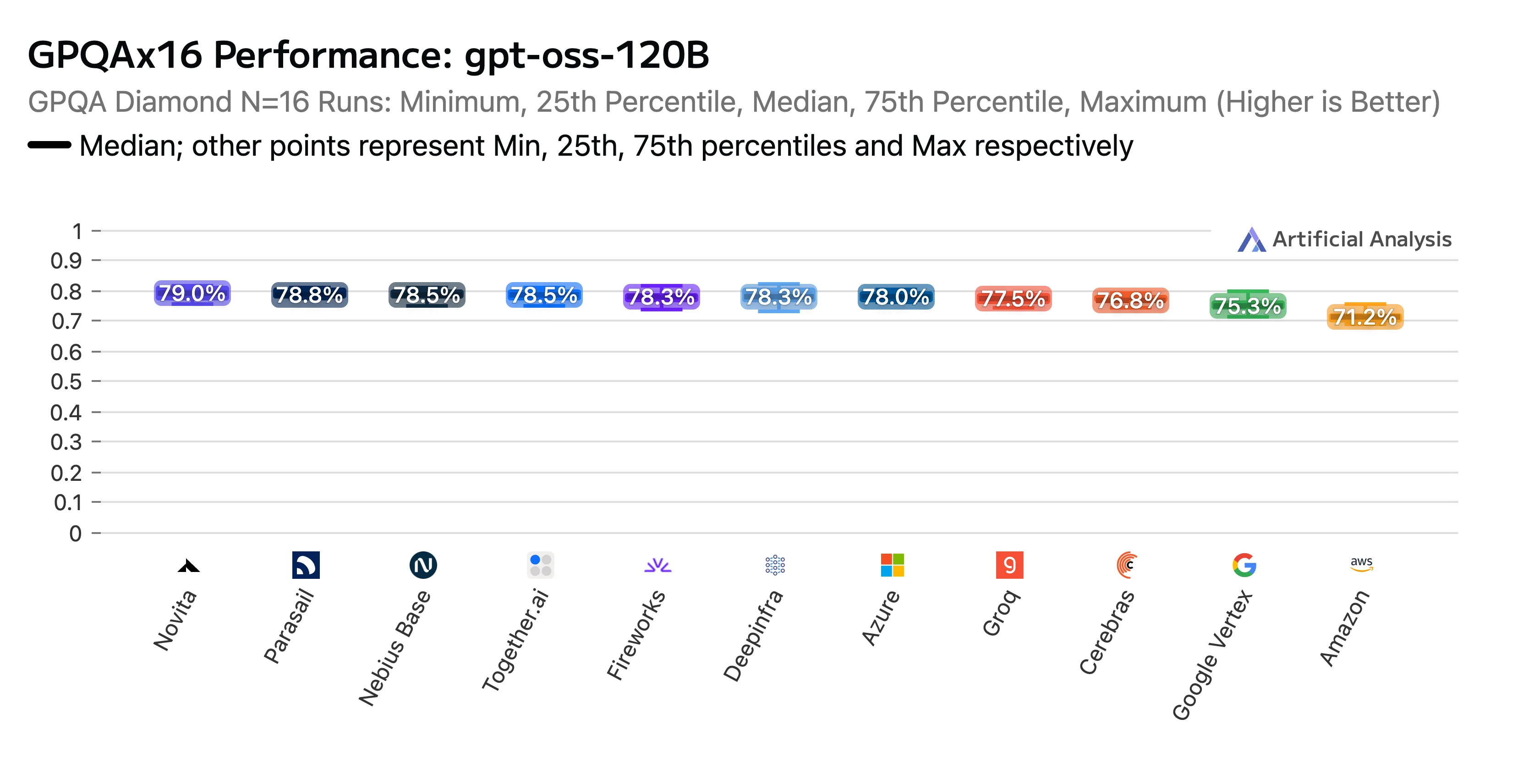
Título: Ranking de rendimiento GPTOSS 120B GPQAx16 por proveedor de LLM
Fuente: Artificial Analysis
El informe también destacó nuestros precios competitivos y velocidad:
- Ventana de contexto: Nuestro endpoint soporta completamente la impresionante ventana de contexto de 131k tokens del modelo.
- Tiempo total de respuesta extremo a extremo: 11.11 segundos.
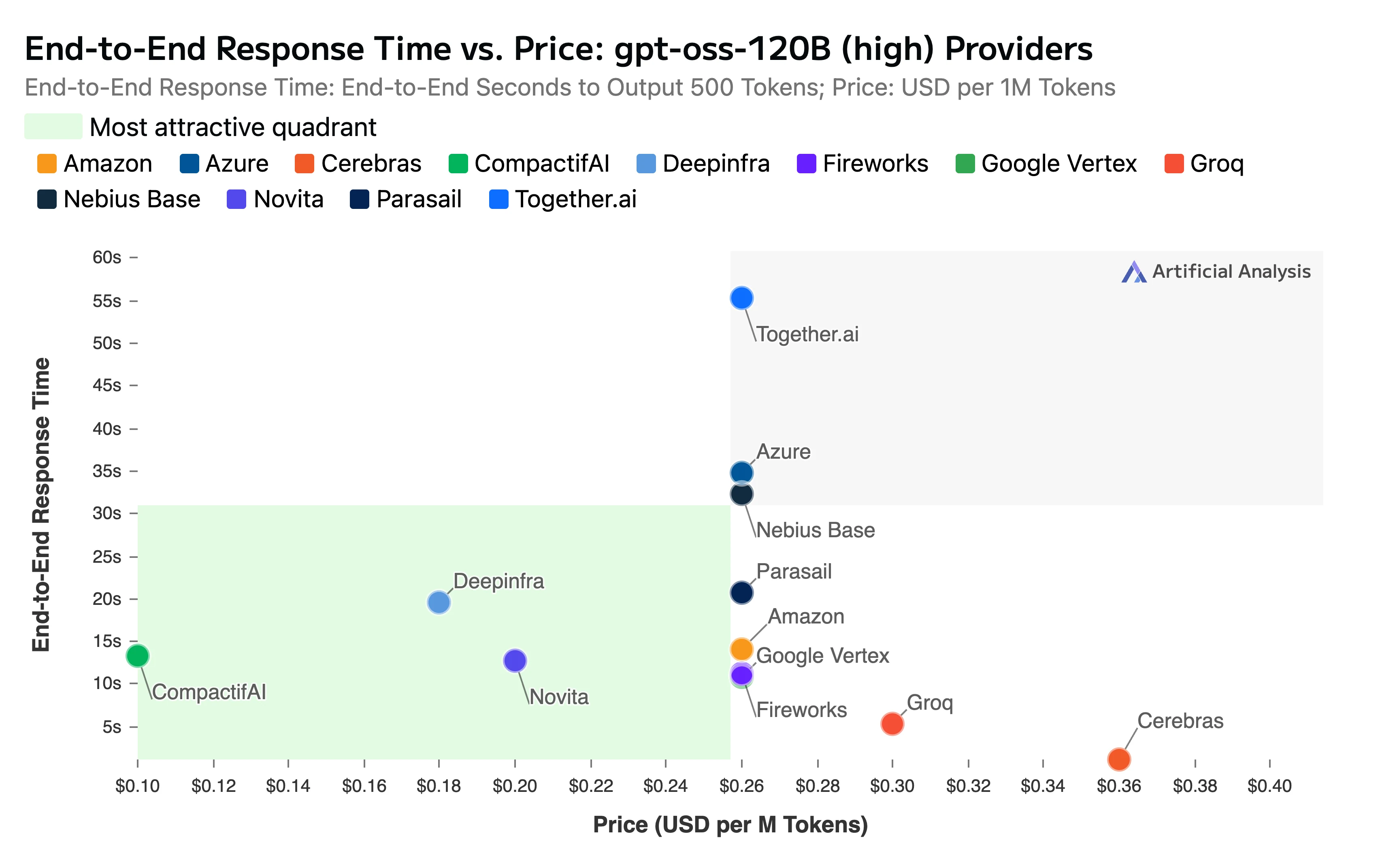
Título: Tiempo de respuesta extremo a extremo vs. precio
Fuente: Artificial Analysis
- Precio combinado: $0.20 por millón de tokens, con tokens de entrada a $0.10/M y tokens de salida a $0.50/M.
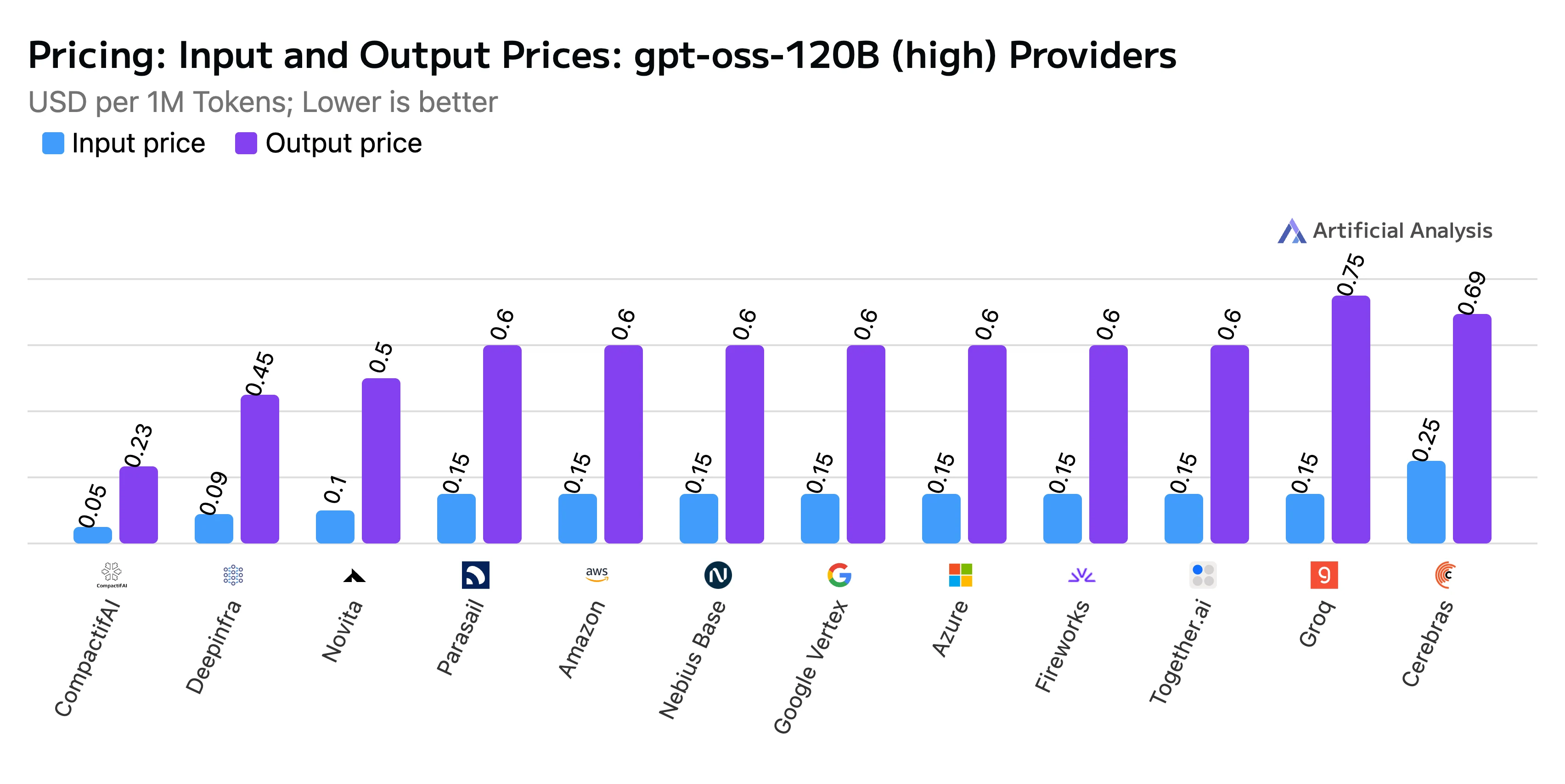
Título: Comparación de precios de entrada y salida
Fuente: Artificial Analysis
Estamos orgullosos de ofrecer este nivel de rendimiento a la comunidad de código abierto y estamos emocionados de ver lo que nuestros usuarios construirán con el poder de un GPT-OSS optimizado.



