

在 Novita AI,我們始終致力於為開發者提供快速、可靠且平價的頂級 AI 模型存取服務。當 OpenAI 發布開源模型 GPT-OSS 120B 與 20B 時,我們當天就完成了兩款模型的託管。但僅僅部署模型還不夠,因此我們的工程團隊花了一整週時間專注於一個目標:優化我們的 GPT-OSS 端點,為使用者帶來卓越的使用體驗。
最終成果?我們的端點獲評為業界頂尖效能表現,這已經由 AI 模型與託管服務的獨立分析平台 Artificial Analysis 驗證。

標題:GPT OSS 120B
來源:Hugging Face
什麼是 GPT-OSS-120B?
GPT-OSS-120B 是 OpenAI 於 2025 年 8 月發布的全新開源權重模型之一,採用混合專家(MoE)架構,擁有 1170 億個參數。它在處理每個 token 時僅會啟動部分參數,既能在保留強大推理能力的同時實現高效推論。該模型在 Apache 2.0 許可協議下支援工具調用、擴展上下文窗口、複雜推理等進階功能。
挑戰:多指標平衡優化
託管 GPT-OSS 120B 這類大語言模型(LLM)需要同時平衡多項指標,我們必須對以下幾個關鍵指標進行同步優化:
- 延遲: 模型回應使用者請求的速度有多快?低延遲,尤其是首 token 生成時間,是優質對話體驗的關鍵。
- 吞吐量: 我們的端點每秒能處理多少個 token?高吞吐量能確保回應速度,直接影響使用者體驗。
- 上下文窗口: 模型能否處理長且複雜的提示詞?GPT-OSS 系列模型擁有高達 131,072 token 的上下文窗口,我們需要確保託管部署能完整發揮這項能力。
- 模型品質: 我們的優化是否保留了模型的核心能力,例如函數調用(也稱工具調用)以及結構化/JSON 輸出?我們啟用了推理功能,同時確保託管部署不會引入錯誤、損害模型的準確性與推理能力。
成果:我們達到的目標
我們的努力得到了回報。Novita 的端點在 Artificial Analysis 發布的 GPT-OSS-120B(高負載)API 供應商效能基準測試與分析報告 中獲得了高排名。我們在 AIME(美國邀請數學考試) 與 GPQA(研究生級別防谷歌問答) 推理基準測試中被评为頂尖表現者,準確率得分位居前列,更難得的是我們的收費成本屬於業界最低水平。
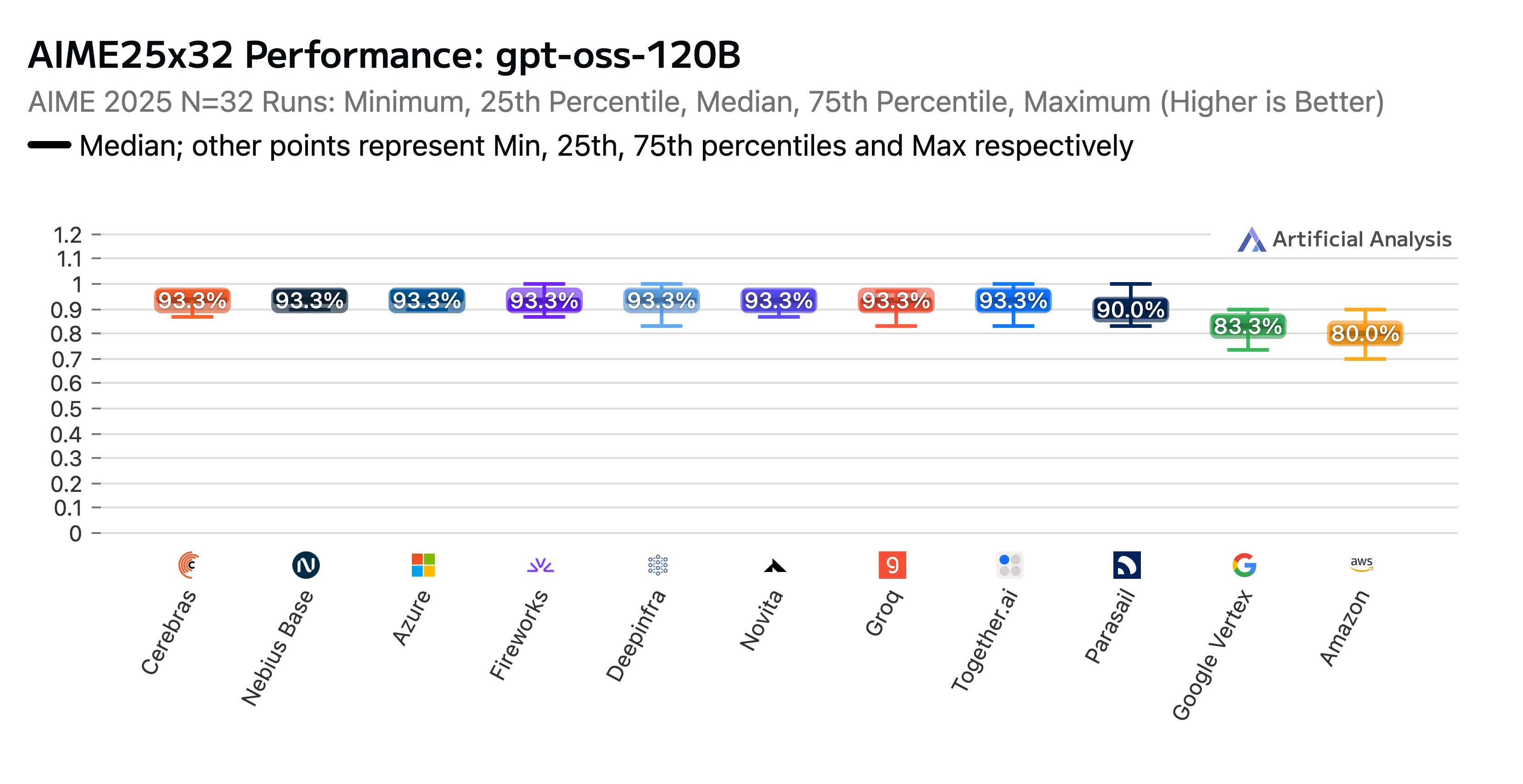
標題:GPTOSS 120B AIME25x32 各大 LLM 供應商效能排名
來源:Artificial Analysis
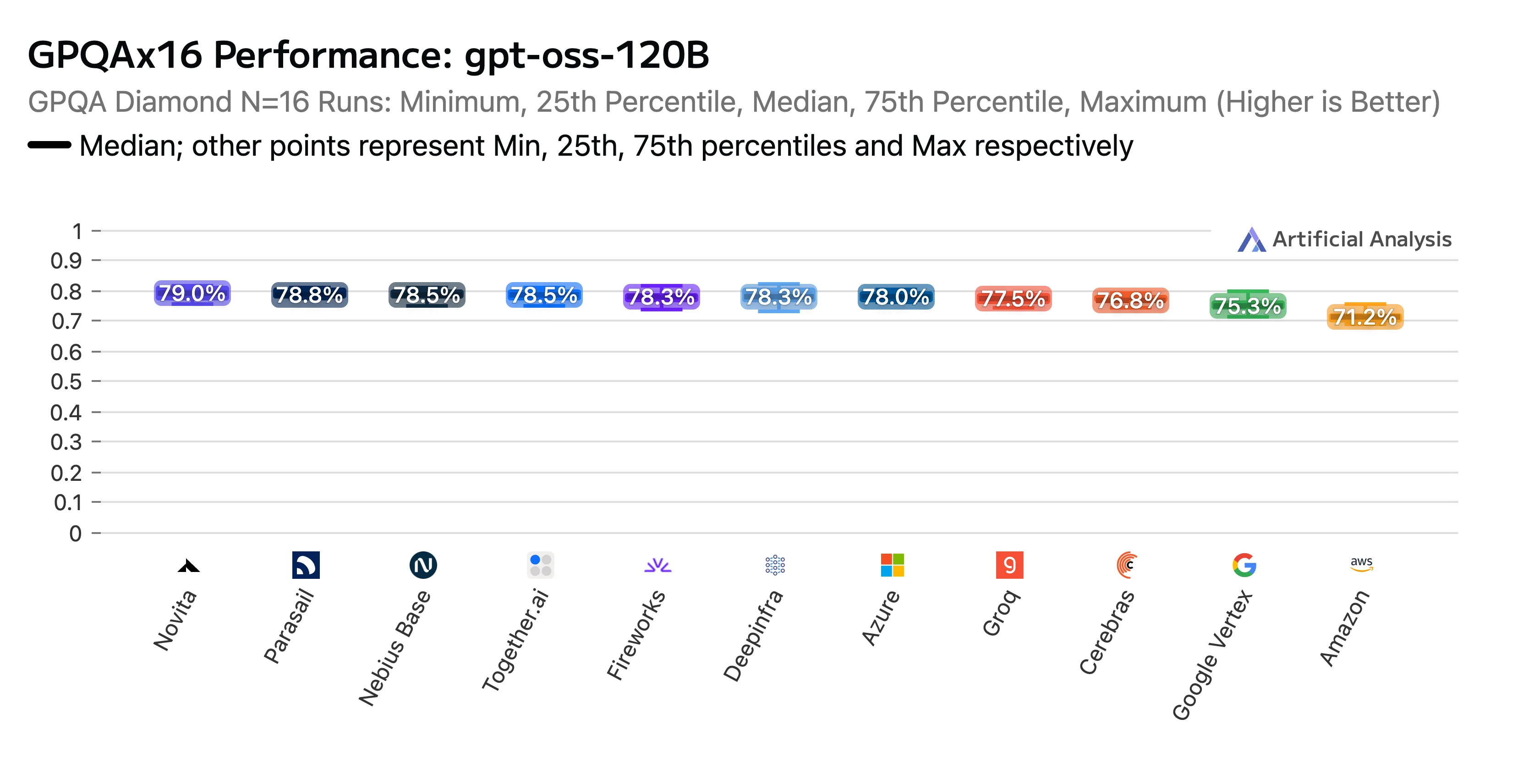
標題:GPTOSS 120B GPQAx16 各大 LLM 供應商效能排名
來源:Artificial Analysis
該報告也點出了我們在定價與速度上的競爭優勢:
- 上下文窗口: 我們的端點完整支援模型高達 131k token 的上下文窗口
- 總端到端回應時間: 11.11 秒
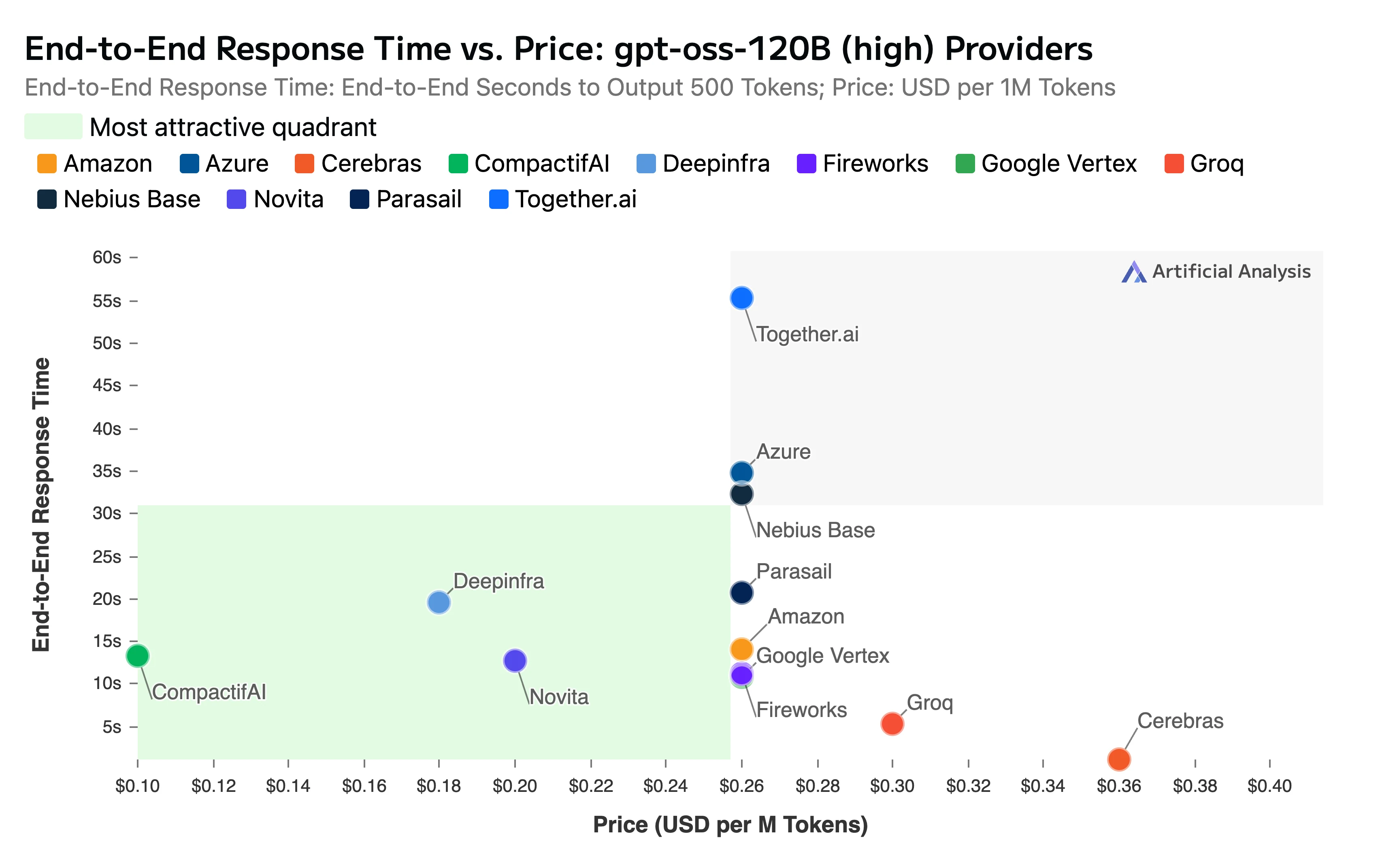
標題:端到端回應時間 vs 價格
來源:Artificial Analysis
- 混合計價: 每百萬 token 收費 0.20 美元,其中輸入 token 單價為 0.10 美元/百萬,輸出 token 單價為 0.50 美元/百萬
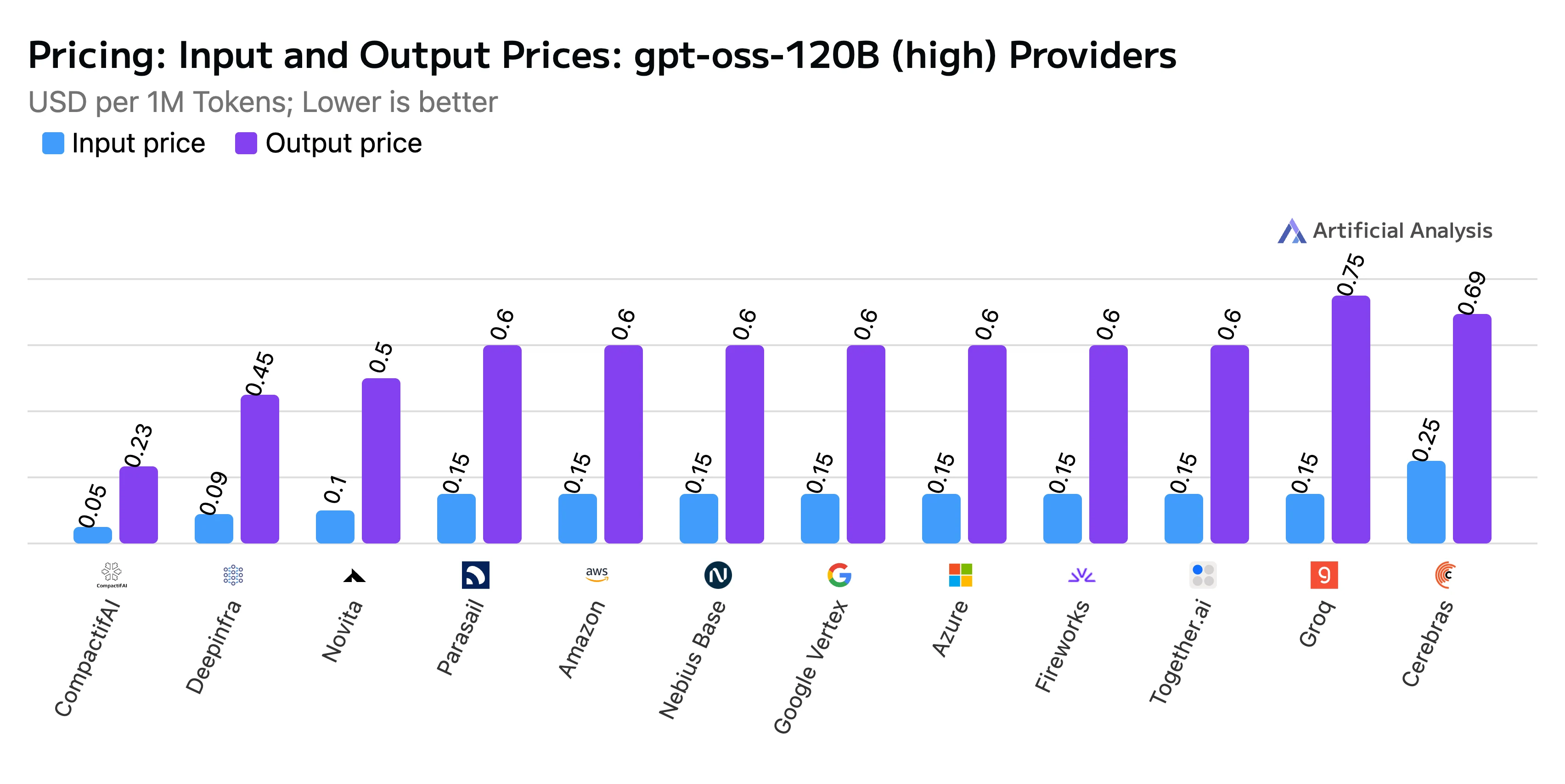
我們很榮幸能將這般水準的效能帶給開源社群,也期待看到使用者們運用優化後的 GPT-OSS 創造出哪些精彩作品。



