

В Novita AI мы стремимся предоставить разработчикам быстрый, надёжный и доступный доступ к лучшим AI-моделям. Когда OpenAI выпустила свои открытые модели GPT-OSS 120B и 20B, мы разместили обе в тот же день. Но простого развёртывания модели недостаточно. Поэтому наша инженерная команда посвятила всю неделю одной цели: оптимизации наших эндпоинтов GPT-OSS для обеспечения исключительного пользовательского опыта.
Результат? Наш эндпоинт был признан одним из лучших в отрасли по версии Artificial Analysis — независимой платформы для анализа AI-моделей и хостинг-провайдеров.

Название: GPT OSS 120B
Источник: Hugging Face
Что такое GPT-OSS-120B?
GPT-OSS-120B — одна из новых открытых моделей с открытыми весами от OpenAI, выпущенная в августе 2025 года. Она имеет архитектуру mixture-of-experts (MoE) с 117 миллиардами параметров. При обработке каждого токена активируется только часть этих параметров, что обеспечивает эффективный вывод при сохранении сильных возможностей рассуждений. Эта модель поддерживает продвинутые функции: использование инструментов, расширенные контекстные окна и сложные рассуждения, и распространяется по лицензии Apache 2.0.
Задача: Баланс между показателями
Размещение LLM, таких как GPT-OSS 120B, требует одновременной балансировки нескольких метрик. Нам пришлось одновременно оптимизировать несколько ключевых показателей:
- Задержка (латентность): Как быстро модель отвечает на запрос пользователя? Низкая задержка, особенно время до первого токена, крайне важна для качественного пользовательского опыта в диалоге.
- Пропускная способность: Сколько токенов в секунду может обрабатывать наш эндпоинт? Высокая пропускная способность обеспечивает скорость, что напрямую влияет на пользовательский опыт.
- Контекстное окно: Может ли модель обрабатывать длинные, сложные запросы? У моделей GPT-OSS огромное контекстное окно в 131 072 токена, и нам нужно было убедиться, что наше развёртывание полностью поддерживает его возможности.
- Качество модели: Сохраняет ли наша оптимизация основные возможности модели, такие как вызов функций (также известный как вызов инструментов) и структурированные/JSON-выводы? Мы включили режим рассуждений и убедились, что наше развёртывание не вызывает ошибок и не снижает точность/возможности рассуждений модели.
Результаты: Что нам удалось достичь
Наши усилия оправдались. Эндпоинт Novita получил высокий рейтинг в отчёте по бенчмаркингу и анализу производительности API-провайдеров для GPT-OSS-120B (high) от Artificial Analysis. Мы были признаны лучшим по результатам тестов на рассуждения AIME (American Invitational Mathematics Examination) и GPQA (Graduate-Level Google-Proof Q&A). Novita показала одни из самых высоких показателей точности, и в довершение всего наши тарифы оказались одними из самых низких.
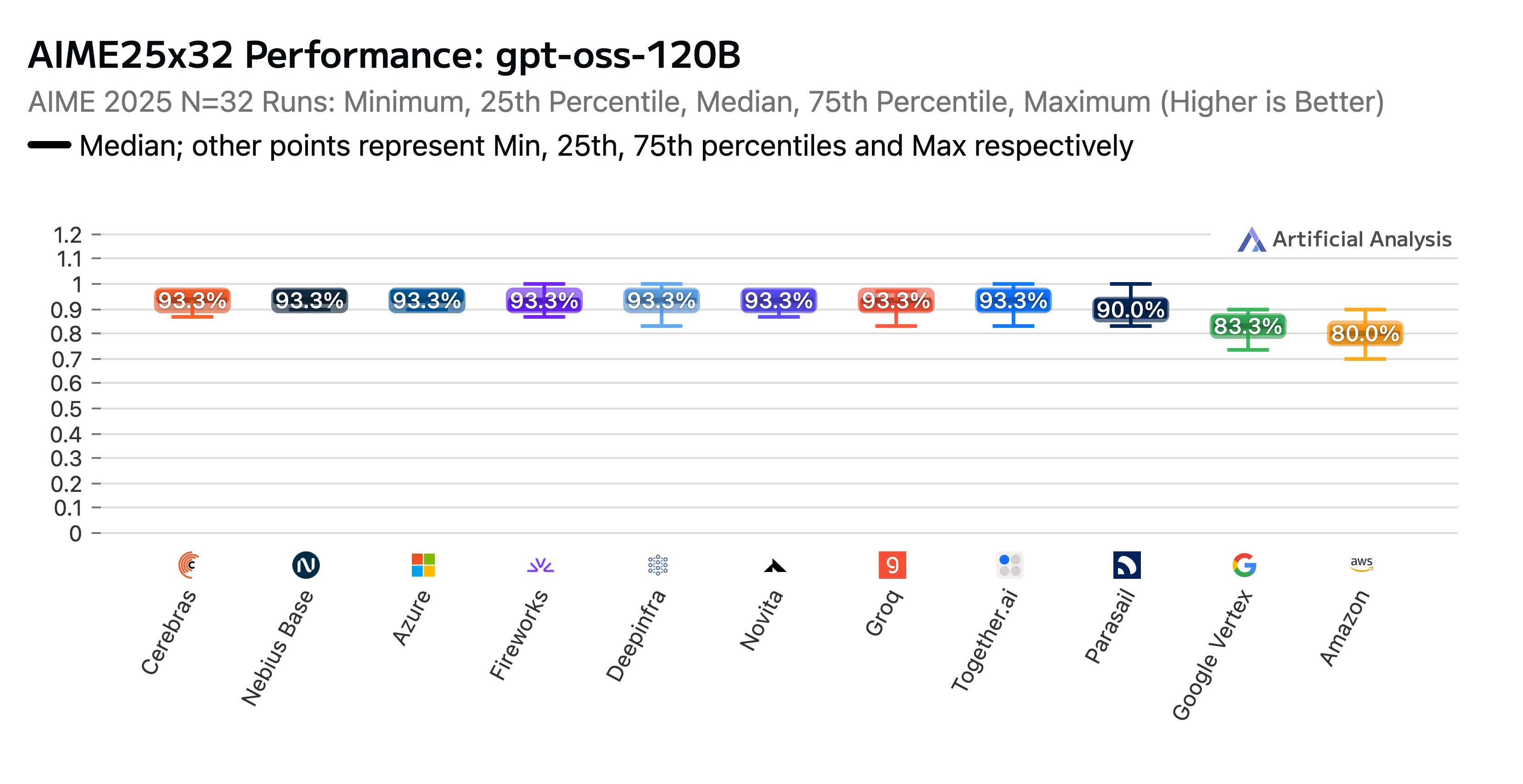
Название: Рейтинг производительности GPTOSS 120B AIME25x32 по провайдерам LLM
Источник: Artificial Analysis
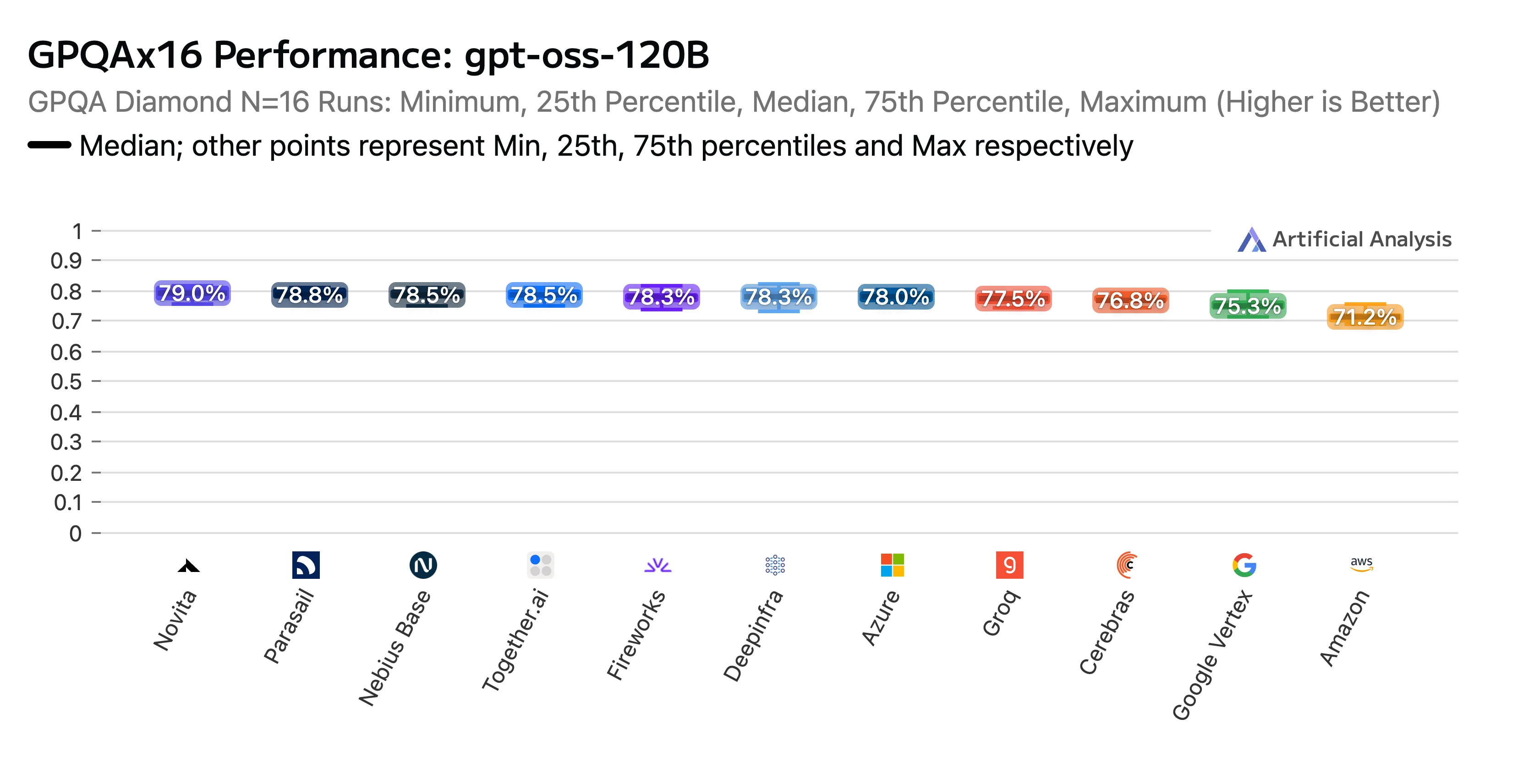
Название: Рейтинг производительности GPTOSS 120B GPQAx16 по провайдерам LLM
Источник: Artificial Analysis
В отчёте также отмечались наши конкурентоспособные тарифы и скорость:
- Контекстное окно: Наш эндпоинт полностью поддерживает впечатляющее контекстное окно модели в 131k токенов
- Общее время ответа от начала до конца: 11,11 секунды
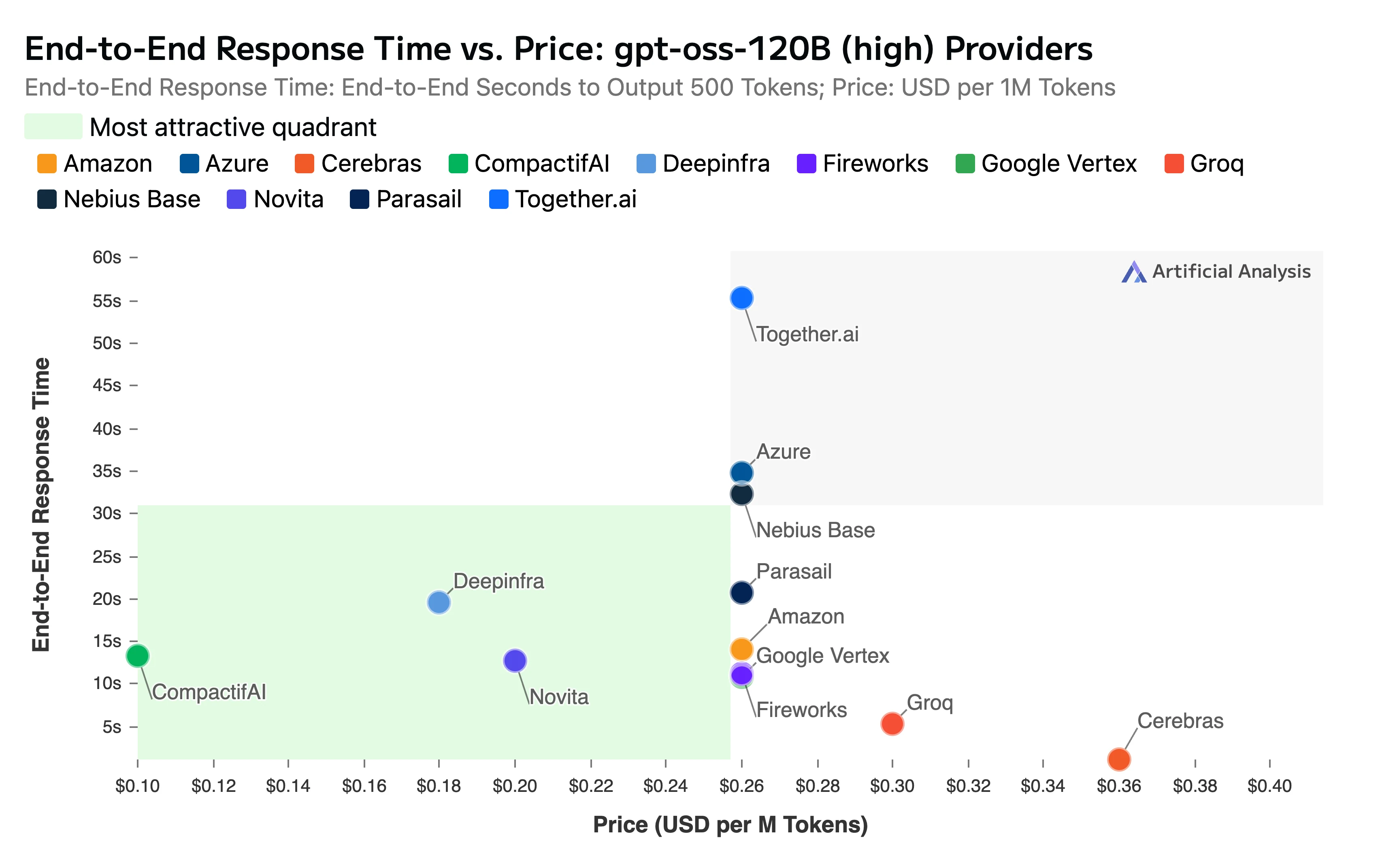
Название: Время ответа от начала до конца в сравнении с ценой
Источник: Artificial Analysis
- Средневзвешенная цена: $0,20 за миллион токенов, при этом входные токены стоят $0,10 за миллион, а выходные — $0,50 за миллион
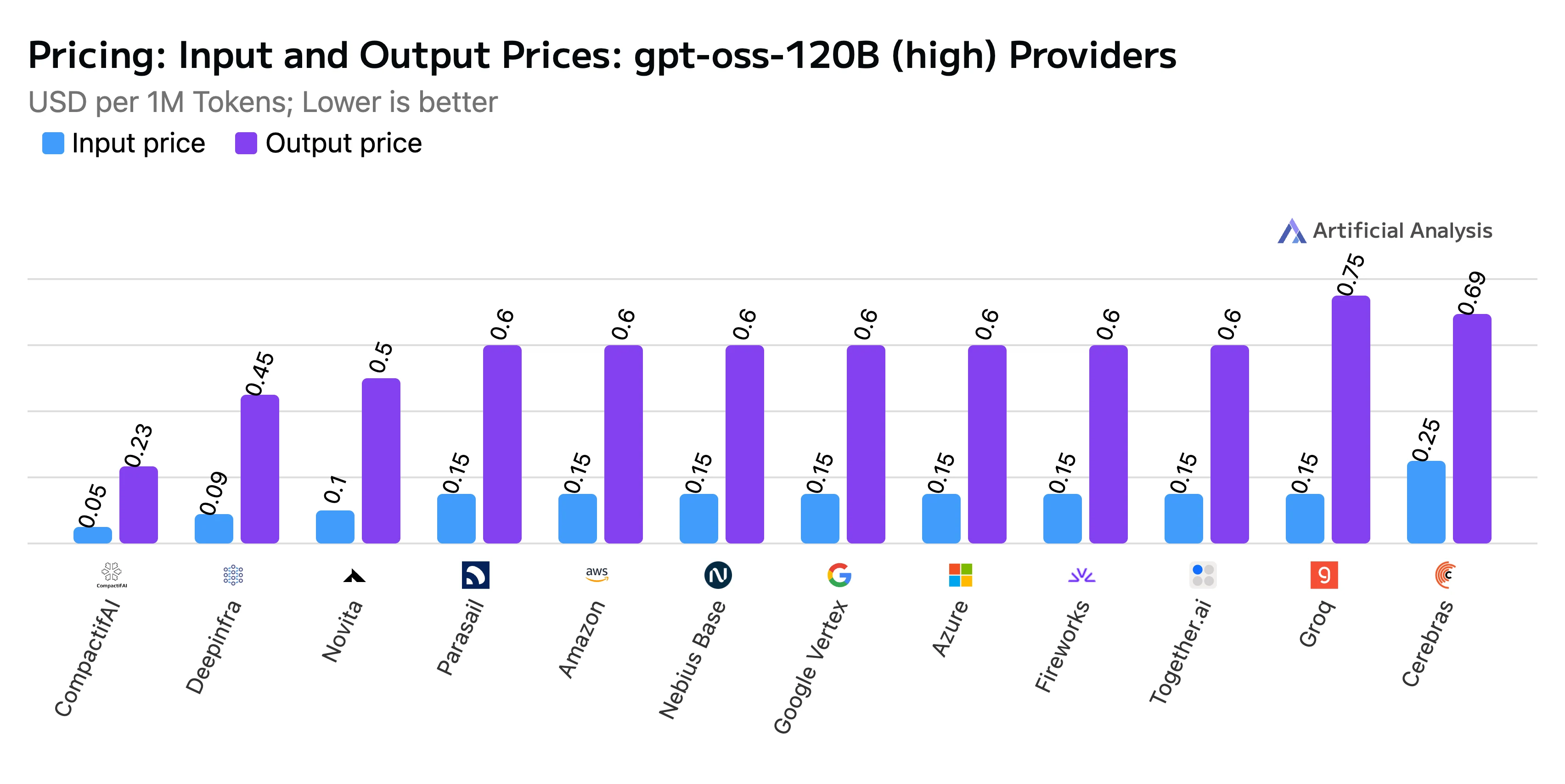
Название: Сравнение цен на входные и выходные токены
Источник: Artificial Analysis
Мы гордимся тем, что привносим такой уровень производительности в сообщество открытого исходного кода, и с нетерпением ждём, что наши пользователи создадут с помощью оптимизированного GPT-OSS.
Попробуйте эндпоинт GPT-OSS от Novita уже сегодня!



