

Na Novita AI, estamos comprometidos em oferecer aos desenvolvedores acesso rápido, confiável e acessível aos principais modelos de IA. Quando a OpenAI lançou seus modelos de código aberto, GPT-OSS 120B e 20B, hospedamos ambos no mesmo dia. Mas apenas implantar um modelo não é suficiente. É por isso que nossa equipe de engenharia dedicou uma semana inteira a um objetivo: otimizar nossos endpoints GPT-OSS para entregar uma experiência de usuário excepcional.
O resultado? Nosso endpoint foi classificado como um dos melhores desempenhos do setor, validado pela Artificial Analysis, uma plataforma independente de análise de modelos de IA e provedores de hospedagem.

Título: GPT OSS 120B
Fonte: Hugging Face
O que é o GPT-OSS-120B?
O GPT-OSS-120B é um dos novos modelos de peso aberto da OpenAI lançados em agosto de 2025, com um design de mistura de especialistas (MoE) e 117 bilhões de parâmetros. Ele ativa apenas um subconjunto desses parâmetros por token, permitindo inferência eficiente enquanto preserva fortes capacidades de raciocínio. Este modelo suporta recursos avançados como uso de ferramentas, janelas de contexto estendidas e raciocínio complexo, todos sob a licença Apache 2.0.
O Desafio: Um Equilíbrio de Métricas
Hospedar LLMs como o GPT-OSS 120B exige equilibrar várias métricas ao mesmo tempo. Tivemos que otimizar para várias métricas-chave simultaneamente:
- Latência: Com que rapidez o modelo responde a uma solicitação do usuário? Baixa latência, especialmente o tempo até o primeiro token, é crucial para uma boa experiência de usuário conversacional.
- Throughput: Quantos tokens por segundo nosso endpoint consegue processar? Alto throughput garante velocidade, o que impacta diretamente a experiência do usuário.
- Janela de Contexto: O modelo consegue lidar com prompts longos e complexos? Os modelos GPT-OSS possuem uma janela de contexto massiva de 131.072 tokens, e precisávamos garantir que nossa implantação suportasse totalmente suas capacidades.
- Qualidade do Modelo: Nossa otimização preserva as capacidades principais do modelo, como chamada de funções (também conhecida como chamada de ferramentas) e Saídas Estruturadas/JSON? Habilitamos o raciocínio e garantimos que nossa implantação não introduzisse erros ou comprometesse a precisão e as habilidades de raciocínio do modelo.
Os Resultados: O que Alcançamos
Nosso trabalho duro valeu a pena. O endpoint da Novita obteve uma classificação alta no Relatório de Benchmarking e Análise de Desempenho de Provedores de API do GPT-OSS-120B (alto) da Artificial Analysis. Fomos reconhecidos como o melhor desempenho nos benchmarks de raciocínio AIME (American Invitational Mathematics Examination) e GPQA (Graduate-Level Google-Proof Q&A). A Novita entregou algumas das maiores pontuações de precisão, e para coroar, nossos custos estavam entre os mais baixos.
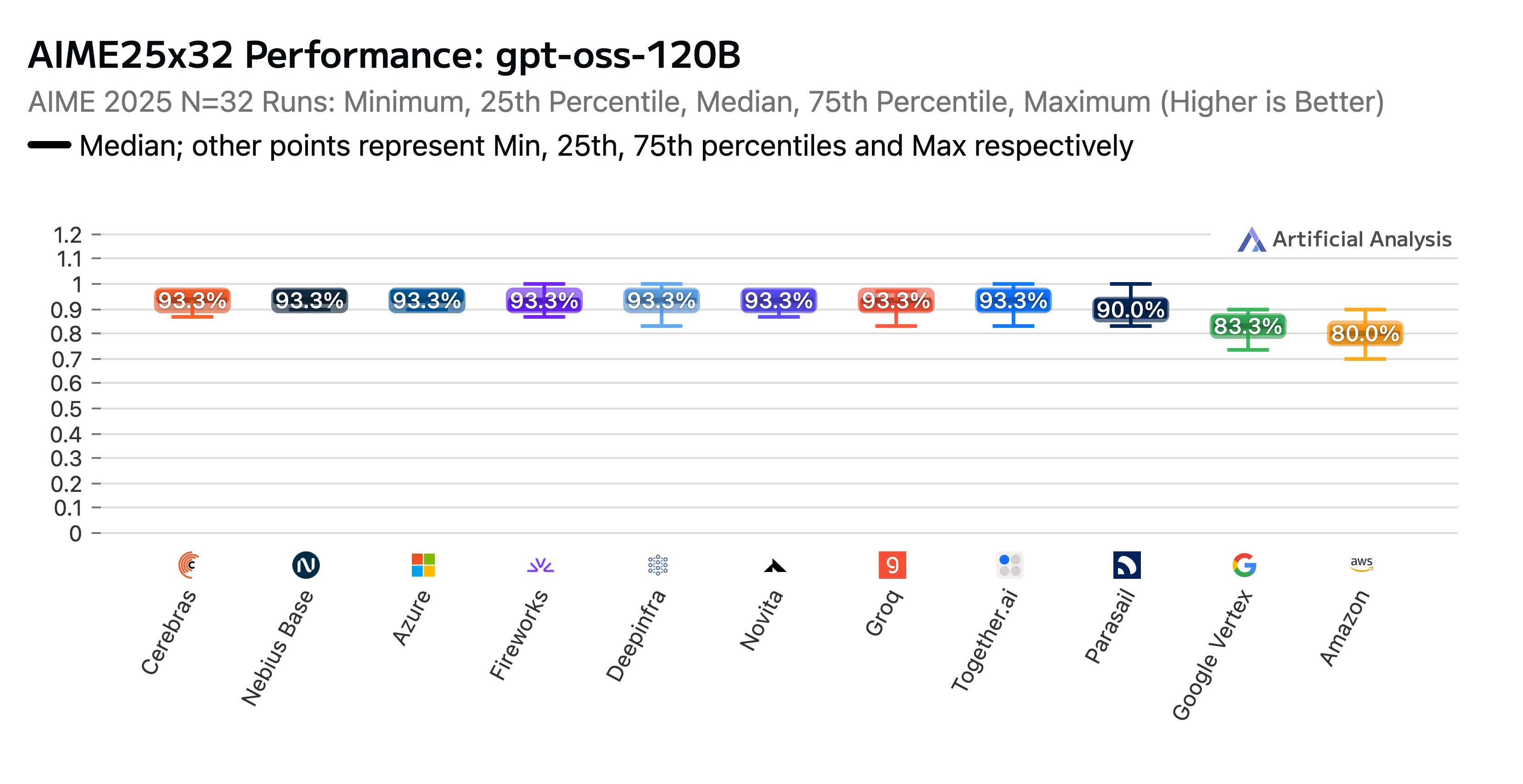
Título: Classificação de Desempenho do GPTOSS 120B AIME25x32 por Provedor de LLM
Fonte: Artificial Analysis
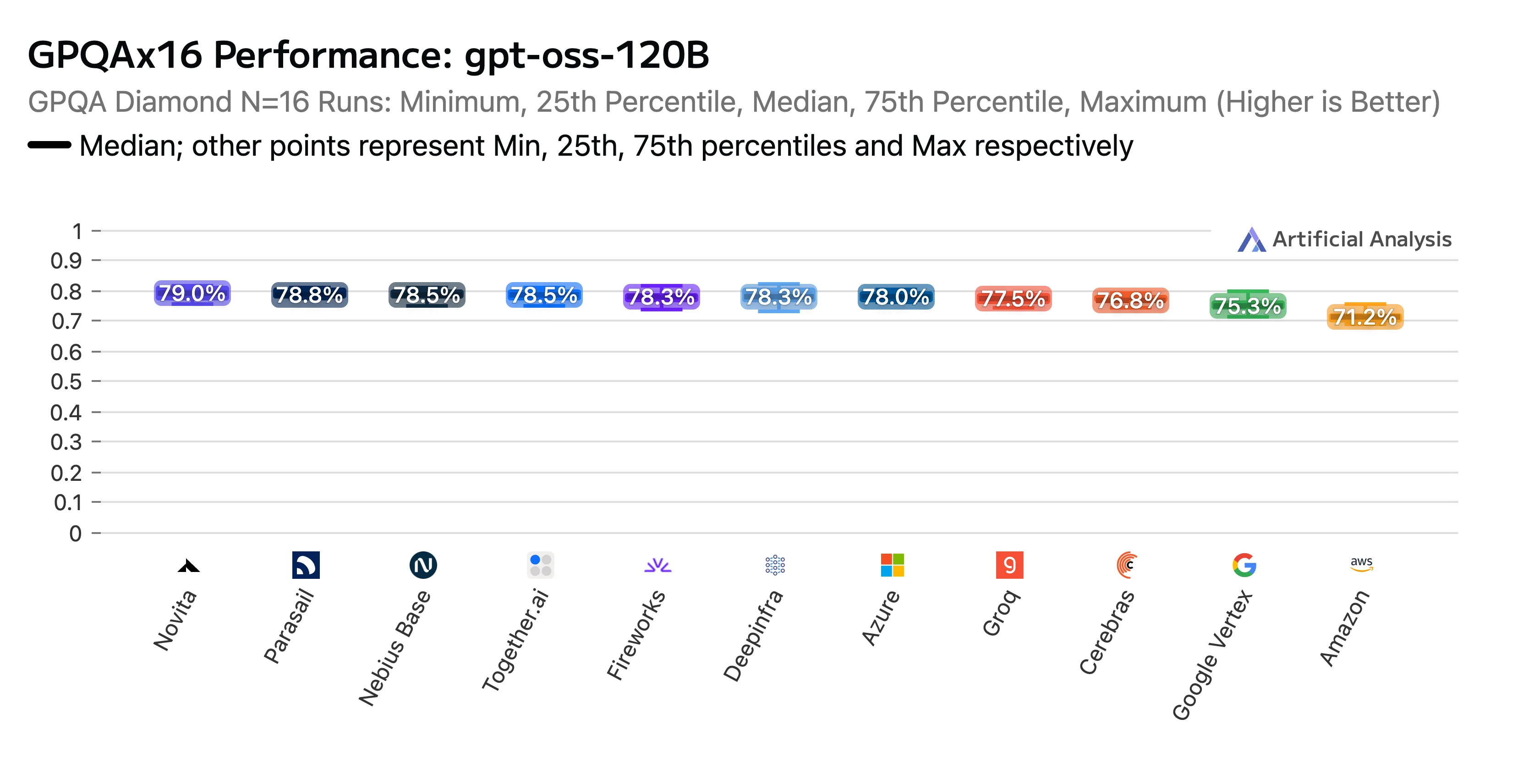
Título: Classificação de Desempenho do GPTOSS 120B GPQAx16 por Provedor de LLM
Fonte: Artificial Analysis
O relatório também destacou nosso preço competitivo e velocidade:
- Janela de Contexto: Nosso endpoint suporta totalmente a impressionante janela de contexto de 131k tokens do modelo
- Tempo total de resposta ponta a ponta: 11,11 segundos
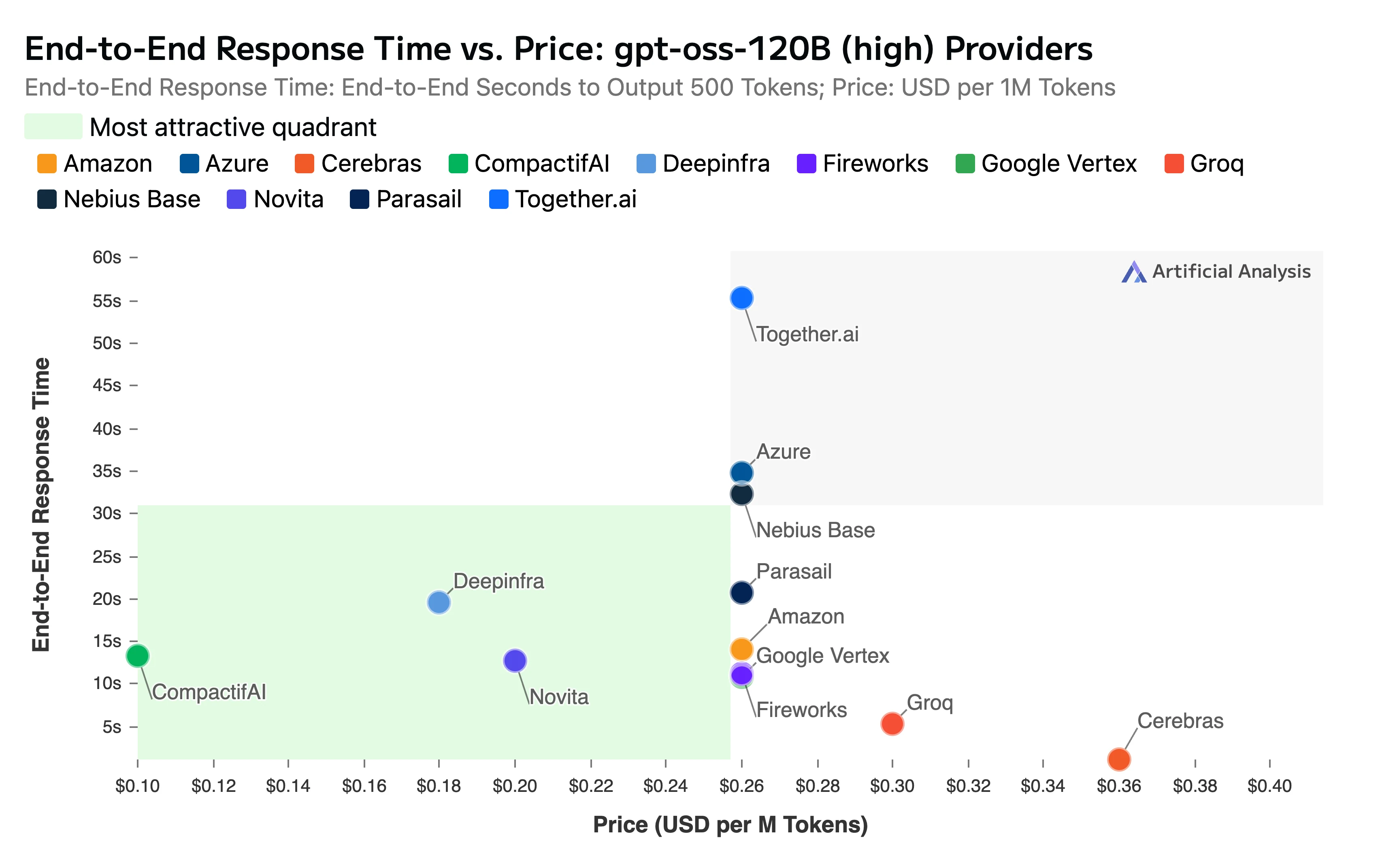
Título: Tempo de Resposta Ponta a Ponta vs Preço
Fonte: Artificial Analysis
- Preço Combinado: $0,20 por milhão de tokens, com tokens de entrada custando $0,10/M e tokens de saída $0,50/M
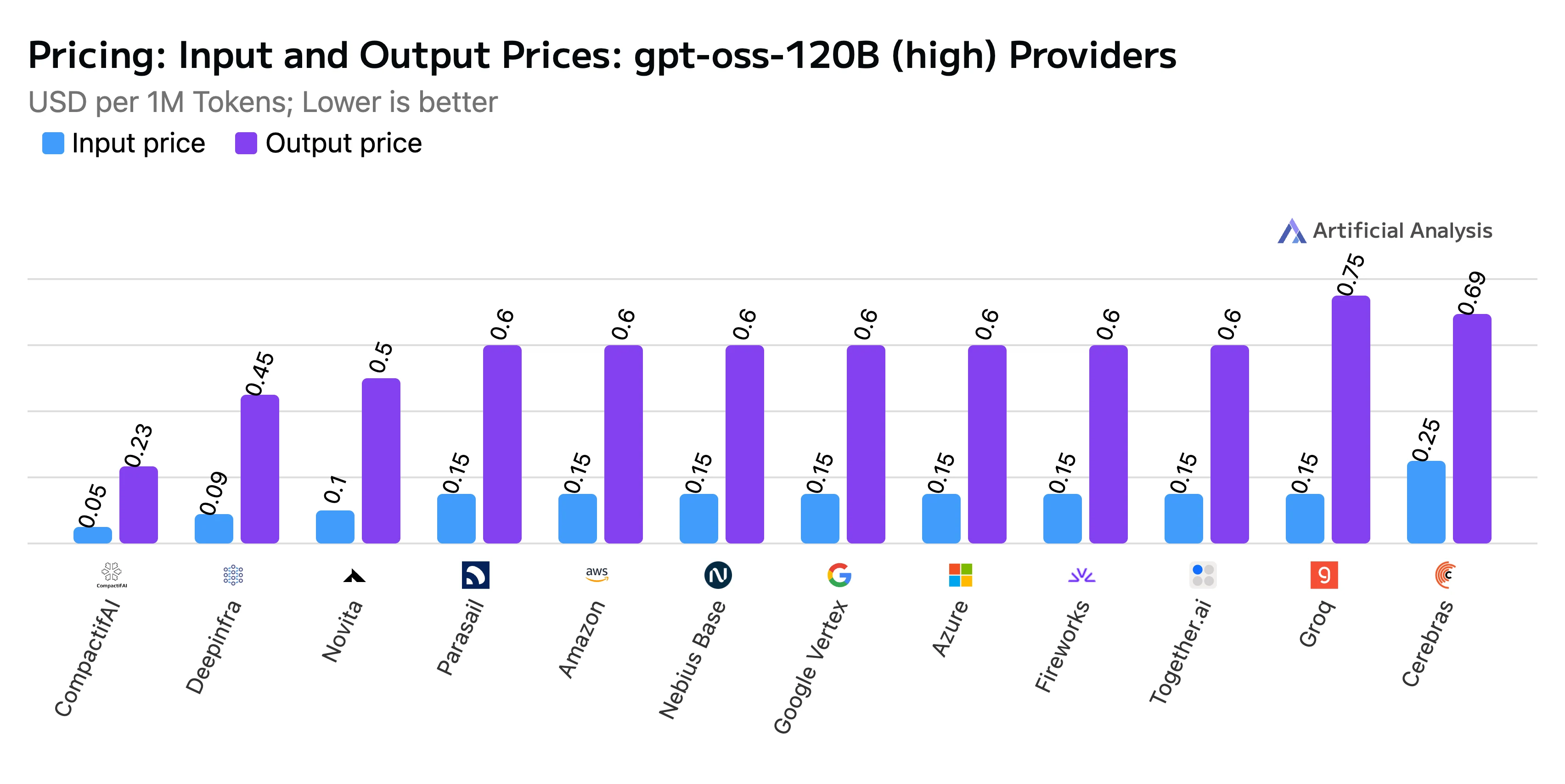
Título: Comparação de Preços de Entrada e Saída
Fonte: Artificial Analysis
Temos orgulho de trazer esse nível de desempenho para a comunidade de código aberto e estamos animados para ver o que nossos usuários constroem com o poder de um GPT-OSS otimizado.
Experimente o Endpoint GPT-OSS da Novita hoje mesmo!



