

Bei Novita AI setzen wir uns dafür ein, Entwicklern schnellen, zuverlässigen und erschwinglichen Zugang zu den besten KI-Modellen zu bieten. Als OpenAI seine Open-Source-Modelle GPT-OSS 120B und 20B veröffentlichte, haben wir beide noch am selben Tag gehostet. Doch die einfache Bereitstellung eines Modells reicht nicht aus. Deshalb hat unser Engineering-Team eine ganze Woche lang an einem einzigen Ziel gearbeitet: die Optimierung unserer GPT-OSS-Endpunkte, um eine herausragende Benutzererfahrung zu liefern.
Das Ergebnis? Unser Endpunkt wurde von Artificial Analysis, einer unabhängigen Analyseplattform für KI-Modelle und Hosting-Anbieter, als einer der besten Performer der Branche eingestuft.

Titel: GPT OSS 120B
Quelle: Hugging Face
Was ist GPT-OSS-120B?
GPT-OSS-120B ist eines der neuen Open-Weight-Modelle von OpenAI, das im August 2025 veröffentlicht wurde und über ein Mixture-of-Experts (MoE)-Design mit 117 Milliarden Parametern verfügt. Es aktiviert nur eine Teilmenge dieser Parameter pro Token, was eine effiziente Inferenz ermöglicht, während gleichzeitig starke Schlussfolgerungsfähigkeiten erhalten bleiben. Dieses Modell unterstützt erweiterte Funktionen wie Tool-Nutzung, erweiterte Kontextfenster und komplexe Schlussfolgerungen – alles unter der Apache-2.0-Lizenz.
Die Herausforderung: Ein Balanceakt
Das Hosting von LLMs wie dem GPT-OSS 120B erfordert die gleichzeitige Balance mehrerer Metriken. Wir mussten mehrere Schlüsselmesswerte gleichzeitig optimieren:
- Latenz: Wie schnell antwortet das Modell auf die Anfrage eines Benutzers? Eine niedrige Latenz, insbesondere die Zeit bis zum ersten Token, ist entscheidend für eine gute Gesprächsbenutzererfahrung.
- Durchsatz: Wie viele Token pro Sekunde kann unser Endpunkt verarbeiten? Ein hoher Durchsatz gewährleistet Geschwindigkeit, die sich direkt auf die Benutzererfahrung auswirkt.
- Kontextfenster: Kann das Modell lange, komplexe Prompts verarbeiten? Die GPT-OSS-Modelle verfügen über ein riesiges Kontextfenster von 131.072 Token, und wir mussten sicherstellen, dass unsere Bereitstellung seine Fähigkeiten vollständig unterstützt.
- Modellqualität: Erhält unsere Optimierung die Kernfunktionen des Modells, wie Funktionsaufrufe (auch bekannt als Tool-Aufrufe) und strukturierte/JSON-Ausgaben? Wir haben die Schlussfolgerungsfähigkeiten aktiviert und sichergestellt, dass unsere Bereitstellung keine Fehler einführt oder die Genauigkeit/Schlussfolgerungsfähigkeiten des Modells beeinträchtigt.
Die Ergebnisse: Was wir erreicht haben
Unsere harte Arbeit hat sich ausgezahlt. Novitas Endpunkt erreichte eine hohe Platzierung im GPT-OSS-120B (high) API-Anbieter-Leistungsbenchmarking- & Analysebericht von Artificial Analysis. Wir wurden als Top-Performer bei den Schlussfolgerungs-Benchmarks AIME (American Invitational Mathematics Examination) und GPQA (Graduate-Level Google-Proof Q&A) ausgezeichnet. Novita erzielte einige der höchsten Genauigkeitswerte, und als i-Tüpfelchen waren unsere Kosten mit die niedrigsten.
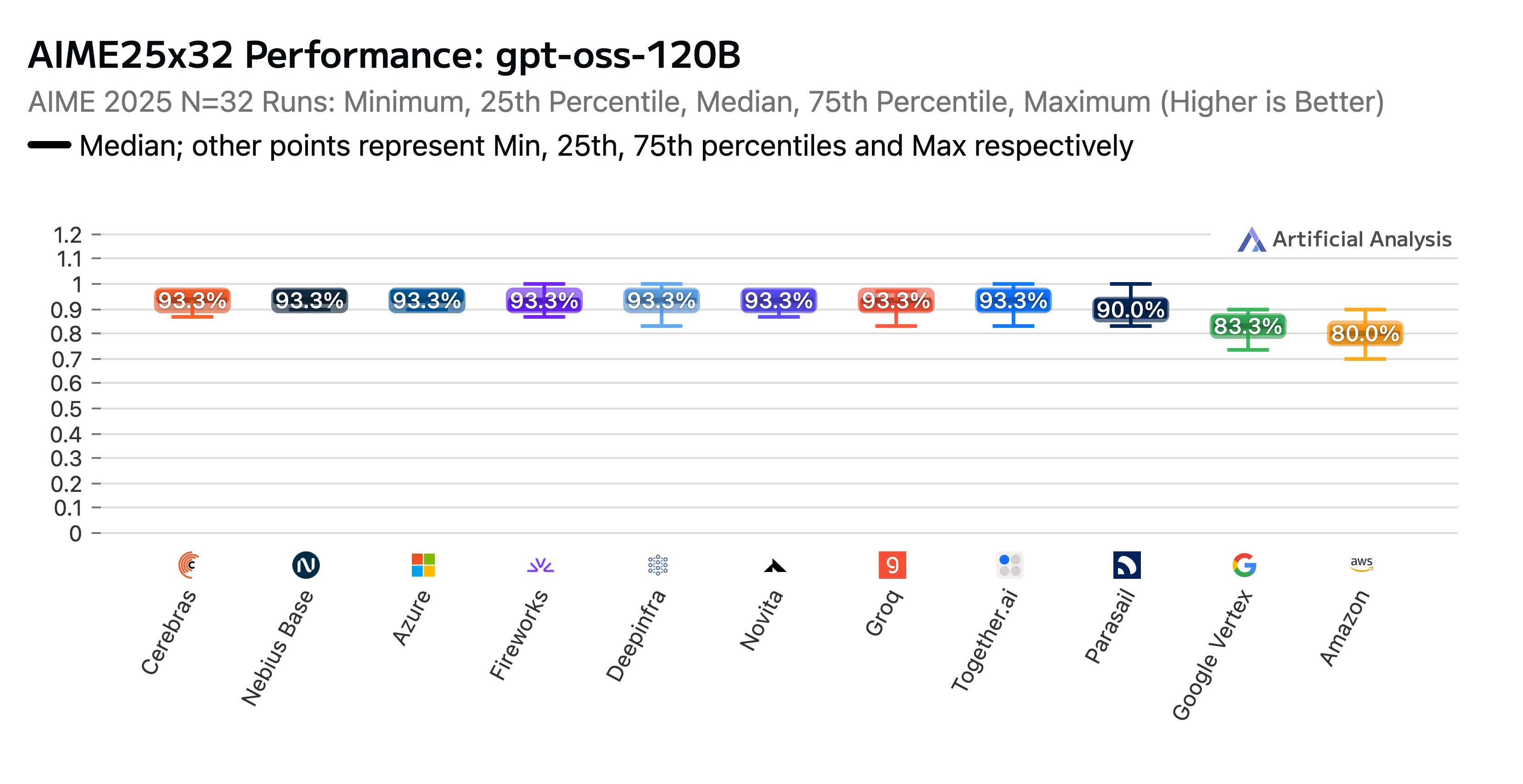
Titel: GPTOSS 120B AIME25x32 Leistungsrangliste nach LLM-Anbieter
Quelle: Artificial Analysis
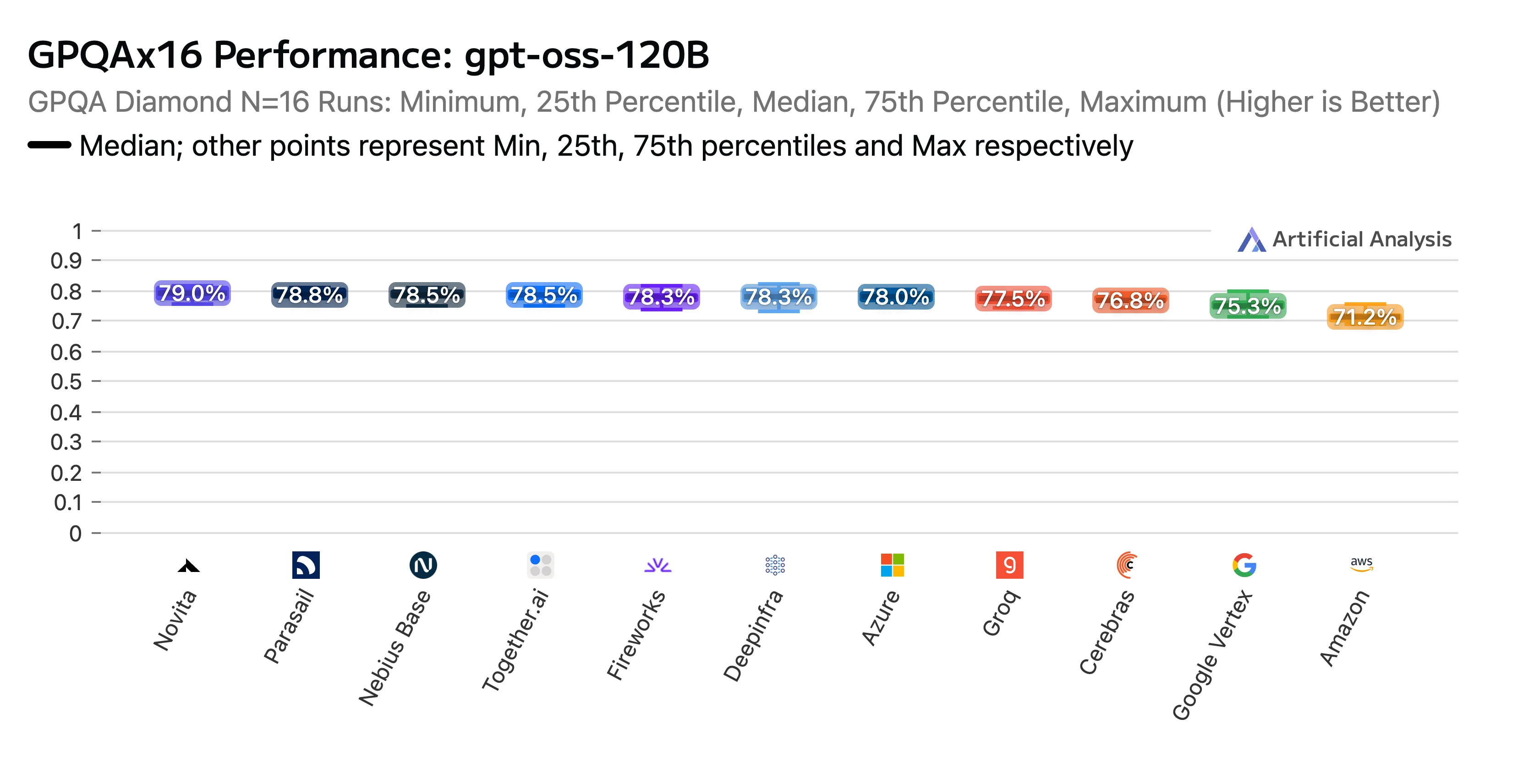
Titel: GPTOSS 120B GPQAx16 Leistungsrangliste nach LLM-Anbieter
Quelle: Artificial Analysis
Der Bericht hob außerdem unsere wettbewerbsfähigen Preise und die Geschwindigkeit hervor:
- Kontextfenster: Unser Endpunkt unterstützt vollständig das beeindruckende 131k-Token-Kontextfenster des Modells
- Gesamte End-to-End-Antwortzeit: 11,11 Sekunden
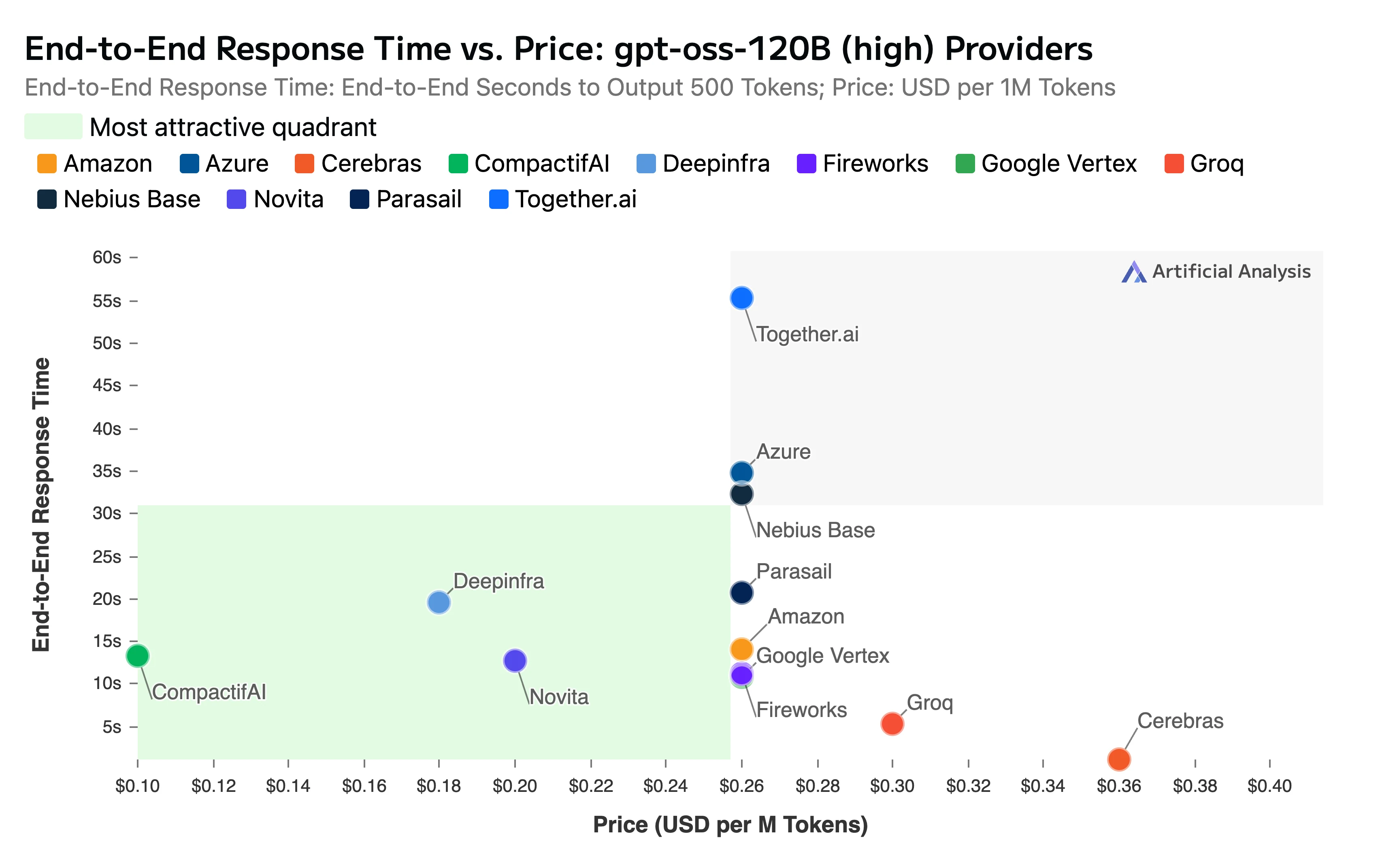
Titel: End-to-End-Antwortzeit im Vergleich zum Preis
Quelle: Artificial Analysis
- Kombinierter Preis: 0,20 $ pro Million Token, wobei Eingabetoken mit 0,10 $/M und Ausgabetoken mit 0,50 $/M berechnet werden.
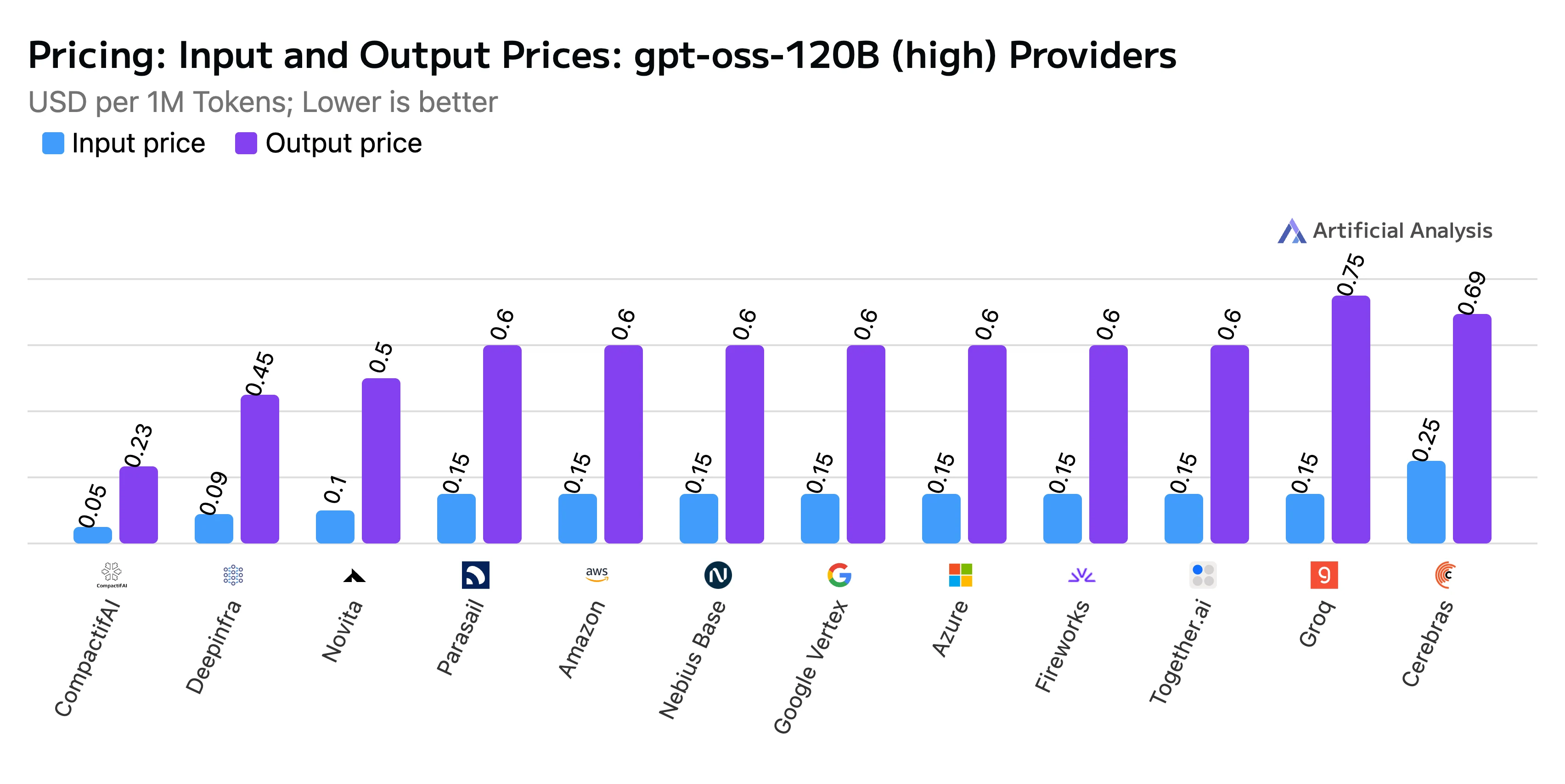
Titel: Preisvergleich von Eingabe- und Ausgabetoken
Quelle: Artificial Analysis
Wir sind stolz darauf, dieses Leistungsniveau der Open-Source-Community zur Verfügung zu stellen, und sind gespannt, was unsere Nutzer mit der Kraft eines optimierten GPT-OSS entwickeln werden.
Testen Sie Novitas GPT-OSS-Endpunkt noch heute!



