

Key Highlights
Choose Llama 3.3 70B when: applications like multilingual chatbots, intelligent assistants, and AI research, but requires higher hardware resources.
Not suitable for Llama 3.3 70B when: Image or audio processing is needed
Choose Mistral Nemo when: text generation tasks, and scenarios requiring function calling
Not suitable for Mistral Nemo when: Seeking comprehensive leading benchmark scores
If you’re looking to evaluate the Llama 3.3 70b or Mistral Nemo on your own use-cases — Upon registration, Novita AI provides a $0.5 credit to get you started!
The field of artificial intelligence is experiencing rapid development, with Meta and Mistral AI introducing their next-generation language models, Llama 3.3 70B and Mistral Nemo, respectively. These releases have garnered widespread attention in the industry. This article will provide a comprehensive analysis of the features and application scenarios of these two models, offering readers a thorough reference.
Basic Introduction of Models Families
To begin our comparison, we first understand the fundamental characteristics of each model.
Llama 3.3 Model Family Characteristics
- Release Date: December 6, 2024
- Model Scale:
- Key Innovations:
- Only instruction-tuned version available
- Supports function calling
- Optimized for multilingual dialogue
- Utilizes GQA technology to improve processing efficiency
- Supports 128K tokens context window
- Significant improvements in reasoning, mathematics, and general knowledge
Mistral Model Family Characteristics
- Release Date: July 19, 2024
- Model Scale:
- Key Features:
- Open-source multilingual model
- 128K tokens large context window
- Supports function calling
- Uses Tekken tokenizer to improve efficiency
- Excels in reasoning, world knowledge, and coding
Model Comparison
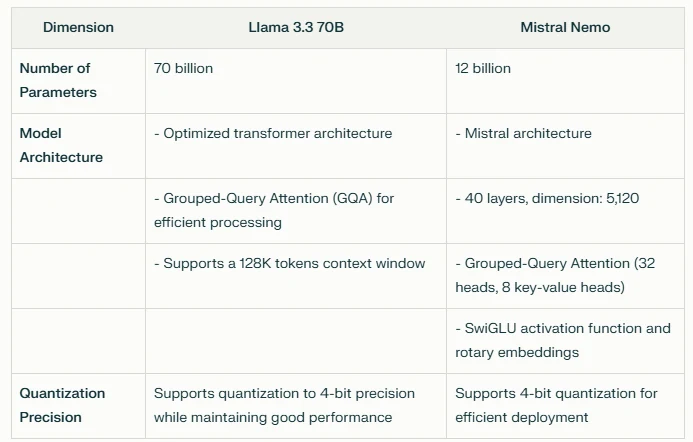
This table highlights the differences in parameters, architectural design, and quantization capabilities between the two models. Llama 3.3 70B offers a significantly larger parameter count and optimized architecture for high-capacity tasks, while Mistral Nemo provides a more compact design with efficient processing features. Both models support quantization for improved deployment efficiency.
Benchmark Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
| Benchmark | Meaning | Llama 3.3 70b | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU (Massive Multitask Language Understanding) evaluates general language understanding across diverse tasks. | 86 | 66 |
| HumanEval | HumanEval tests a model’s ability to write correct Python code based on given problem descriptions. | 86 | 71 |
| MATH | MATH assesses mathematical problem-solving capabilities of models. | 76 | 44 |
| Artificial Analysis Multilingual Index | Reflects performance across a range of languages. Calculated as the average of Multilingual MMLU (general reasoning) and MGSM (mathematical reasoning) evaluation scores. | 84 | <61 |
As we can see from this table, Llama 3.3 70b demonstrates particular strengths in all dimensions.
If you would like to know more about the llama3.3 benchmark knowledge. You can view this article as follows: Llama 3.3 Benchmark: Key Advantages and Application Insights.
Speed Comparison via Novita AI
If you want to test it yourself, you can start a free trial on the Novita AI website.
Latency
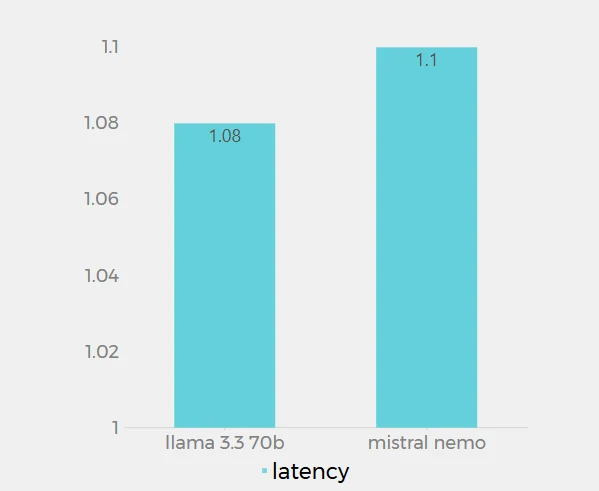
The latency values for Llama 3.3 70B (1.08s) and Mistral Nemo (1.1s) on Novita AI are very close, with only 0.02s difference. This data represents the response time of each model when processing requests on the Novita AI platform. Llama 3.3 70B shows a marginally lower latency, indicating it responds slightly faster than Mistral Nemo. However, the difference is minimal and may not be noticeable in most practical applications. Both models demonstrate low latency, suggesting they are both well-optimized for quick responses.
Throughput (Tokens per Second)
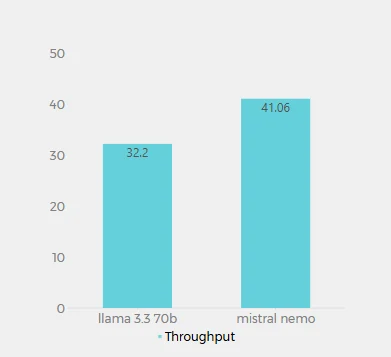
The throughput values for Llama 3.3 70B (32.2 tokens/second) and Mistral Nemo (41.06 tokens/second) on Novita AI represent the number of tokens each model can process per second. This metric is crucial for understanding the models’ processing speed and efficiency. Mistral Nemo demonstrates a higher throughput, processing approximately 27.5% more tokens per second than Llama 3.3 70B. This suggests that Mistral Nemo is more efficient in generating text, potentially offering faster response times for longer outputs.
Hardware Requirements Comparison
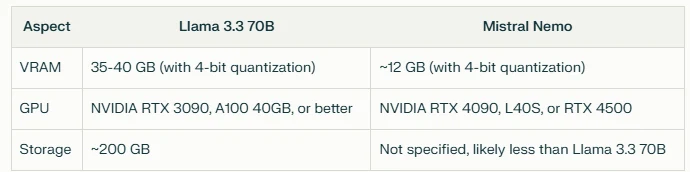
In conclusion, Mistral Nemo seems to offer a more efficient option in terms of hardware requirements, potentially making it more suitable for deployments with limited resources or where efficiency is a priority. However, Llama 3.3 70B’s higher resource requirements might be justified by its larger model size, which could potentially offer better performance in certain tasks.
Applications and Use Cases
Llama 3.3 70B
- Multilingual chatbots and intelligent assistants
- Code support and software development
- Synthetic data generation
- Multilingual content creation and localization
- AI research and experimental platform
- Knowledge-based application development
- Flexible deployment for small teams
Mistral Nemo
- Global multilingual applications, especially suitable for scenarios requiring function calling
- Text generation and translation tasks
Accessibility and Deployment through Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.

Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for pthon users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
In conclusion, Llama 3.3 70B and Mistral Nemo each have their unique characteristics, offering new possibilities for AI application development. When choosing, one should consider specific requirements and weigh the features of each model to achieve the best application effect. As technology continues to advance, we look forward to seeing more innovative AI language models emerge, driving the continuous development of the artificial intelligence field.
Frequently Asked Questions
How much RAM for Llama 3 70B?
Estimated RAM: Around 350 GB to 500 GB of GPU memory is typically required for running Llama 3.1 70B on a single GPU, and the associated system RAM could also be in the range of 64 GB to 128 GB.
Is Llama 3 better than GPT-4?
Our findings show that Llama 3 70B can be up to 50 times cheaper and 10 times faster than GPT-4 when used through cloud API providers. From our small scale evaluations, we learned that Llama 3 70B is good at grade school math, arithmetic reasoning and summarization capabilities.
Is Llama 3 better than claude?
Llama 3 is a top-notch model known for its incredible abilities in understanding and responding to various inputs. On the other hand, Claude 3 comes in different versions like Haiku, Sonnet, and Opus, each with unique strengths. The Opus version of Claude 3 has even outperformed the famous GPT-4 in important tests.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



