

主なポイント
Llama 3.3 70B を選ぶべき場合: 多言語チャットボット、インテリジェントアシスタント、AI研究などのアプリケーション。ただし、より高いハードウェアリソースが必要です。
Llama 3.3 70B が適さない場合: 画像や音声処理が必要な場合
Mistral Nemo を選ぶべき場合: テキスト生成タスク、関数呼び出しが必要なシナリオ
Mistral Nemo が適さない場合: 包括的なトップクラスのベンチマークスコアを求める場合
ご自身のユースケースで Llama 3.3 70b または Mistral Nemo を評価したい場合、Novita AI に登録すると、開始用の $0.5 クレジットが提供されます!
人工知能の分野は急速な発展を遂げており、Meta と Mistral AI はそれぞれ次世代言語モデルである Llama 3.3 70B と Mistral Nemo を発表しました。これらのリリースは業界で広く注目されています。本記事では、これら2つのモデルの特徴と適用シナリオを包括的に分析し、読者に徹底的な参考情報を提供します。
モデルファミリーの基本紹介
比較を始めるにあたり、まず各モデルの基本的な特徴を理解しましょう。
Llama 3.3 モデルファミリーの特徴
- リリース日:2024年12月6日
- モデル規模:
- 主な革新点:
- インストラクションチューニング済みバージョンのみ提供
- 関数呼び出しをサポート
- 多言語対話向けに最適化
- GQA 技術を活用して処理効率を向上
- 128K トークンのコンテキストウィンドウをサポート
- 推論、数学、一般知識において大幅な改善
Mistral モデルファミリーの特徴
- リリース日:2024年7月19日
- モデル規模:
- 主な特徴:
- オープンソースの多言語モデル
- 128K トークンの大規模コンテキストウィンドウ
- 関数呼び出しをサポート
- Tekken トークナイザーを使用して効率を向上
- 推論、世界知識、コーディングに優れる
モデル比較
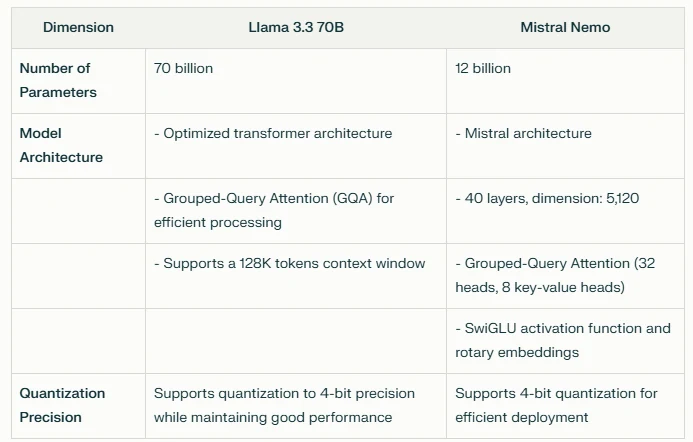
この表は、2つのモデルのパラメータ数、アーキテクチャ設計、量子化機能の違いを強調しています。Llama 3.3 70B はパラメータ数が大幅に多く、高性能タスク向けに最適化されたアーキテクチャを提供します。一方、Mistral Nemo はよりコンパクトな設計で、効率的な処理機能を備えています。両モデルとも、デプロイ効率を向上させるための量子化をサポートしています。
ベンチマーク比較
各モデルの基本特性を確認したところで、さまざまなベンチマークにおけるパフォーマンスを詳しく見ていきましょう。この比較により、それぞれの強みが明確になります。
| ベンチマーク | 意味 | Llama 3.3 70b | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU(Massive Multitask Language Understanding)は、多様なタスクにおける一般的な言語理解を評価します。 | 86 | 66 |
| HumanEval | HumanEval は、与えられた問題の説明に基づいて正しい Python コードを記述するモデルの能力をテストします。 | 86 | 71 |
| MATH | MATH は、モデルの数学的問題解決能力を評価します。 | 76 | 44 |
| Artificial Analysis Multilingual Index | 複数言語にわたるパフォーマンスを反映します。多言語 MMLU(一般的な推論)と MGSM(数学的推論)の評価スコアの平均として計算されます。 | 84 | <61 |
この表からわかるように、Llama 3.3 70b はあらゆる次元で特に優れたパフォーマンスを示しています。
llama3.3 のベンチマーク知識についてさらに詳しく知りたい場合は、以下の記事をご覧ください: Llama 3.3 Benchmark: Key Advantages and Application Insights。
Novita AI での速度比較
ご自身でテストしたい場合は、Novita AI のウェブサイトで無料トライアルを開始できます。
レイテンシ
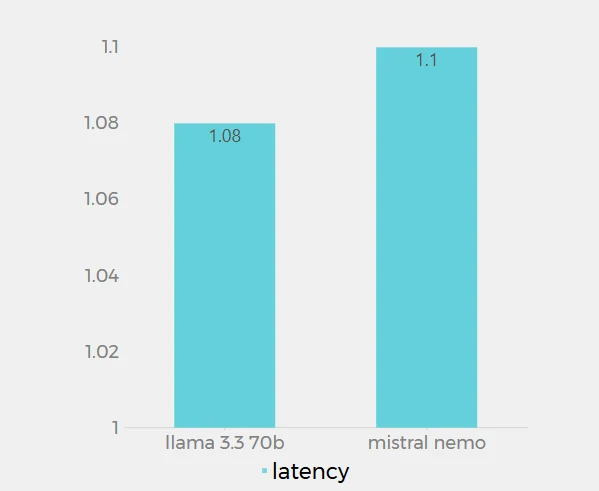
Novita AI 上での Llama 3.3 70B(1.08秒)と Mistral Nemo(1.1秒)のレイテンシ値は非常に近く、差はわずか0.02秒です。このデータは、Novita AI プラットフォームで各モデルがリクエストを処理する際の応答時間を示しています。Llama 3.3 70B はわずかに低いレイテンシを示しており、Mistral Nemo よりわずかに速く応答することを示しています。ただし、その差はわずかであり、ほとんどの実用的なアプリケーションでは気にならない程度です。両モデルとも低レイテンシを示しており、迅速な応答に向けて十分に最適化されていることがわかります。
スループット(1秒あたりのトークン数)
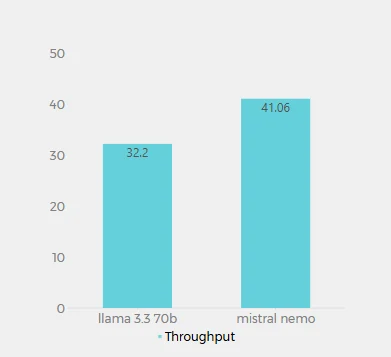
Novita AI 上での Llama 3.3 70B(32.2トークン/秒)と Mistral Nemo(41.06トークン/秒)のスループット値は、各モデルが1秒間に処理できるトークン数を表します。この指標は、モデルの処理速度と効率を理解する上で重要です。Mistral Nemo は高いスループットを示し、Llama 3.3 70B よりも1秒間あたり約27.5%多くのトークンを処理します。これは、Mistral Nemo がテキスト生成においてより効率的であり、長い出力に対してより高速な応答時間を提供できる可能性があることを示唆しています。
ハードウェア要件の比較
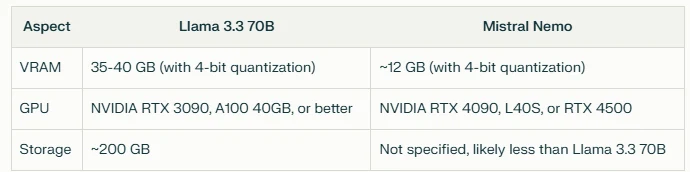
結論として、Mistral Nemo はハードウェア要件の面でより効率的なオプションを提供しているようです。リソースが限られている環境や効率性が優先されるデプロイに適している可能性があります。ただし、Llama 3.3 70B のより高いリソース要件は、より大規模なモデルサイズによって正当化される可能性があり、特定のタスクではより優れたパフォーマンスを提供する可能性があります。
アプリケーションとユースケース
Llama 3.3 70B
- 多言語チャットボットとインテリジェントアシスタント
- コードサポートとソフトウェア開発
- 合成データ生成
- 多言語コンテンツ作成とローカライゼーション
- AI研究と実験プラットフォーム
- 知識ベースのアプリケーション開発
- 小規模チーム向けの柔軟なデプロイ
Mistral Nemo
- グローバルな多言語アプリケーション。特に、関数呼び出しが必要なシナリオに適しています。
- テキスト生成および翻訳タスク
Novita AI によるアクセスとデプロイ
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。

ステップ4:API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーします。

ステップ5:API をインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
登録時に、Novita AI は開始用の $0.5 クレジットを提供します!
無料クレジットを使い切った場合は、支払いを行って継続利用できます。
結論として、Llama 3.3 70B と Mistral Nemo はそれぞれ独自の特徴を持ち、AI アプリケーション開発に新たな可能性を提供します。選択する際は、特定の要件を考慮し、各モデルの特徴を比較検討することで、最適なアプリケーション効果を達成できます。技術が進歩し続ける中、より革新的な AI 言語モデルが登場し、人工知能分野の継続的な発展を促進することを期待しています。
よくある質問
Llama 3 70B にはどのくらいの RAM が必要ですか?
推定 RAM: Llama 3.1 70B を1つの GPU で実行するには、通常 約 350 GB から 500 GB の GPU メモリが必要で、関連するシステム RAM も 64 GB から 128 GB の範囲になる可能性があります。
Llama 3 は GPT-4 より優れていますか?
我々の調査結果によると、Llama 3 70B はクラウド API プロバイダーを通じて使用した場合、GPT-4 よりも最大 50 倍安価で、10 倍高速になる可能性があります。小規模な評価から、Llama 3 70B は小学校レベルの算数、算術推論、要約能力に優れていることがわかりました。
*Llama 3 は Claude より優れていますか?
Llama 3 は、様々な入力の理解と応答において素晴らしい能力を持つトップクラスのモデルです。一方、Claude 3 は Haiku、Sonnet、Opus といった異なるバージョンがあり、それぞれに独自の強みがあります。Claude 3 の Opus バージョンは、重要なテストで有名な GPT-4 を上回る性能を発揮しています。
Novita AI は、AI の野望を実現するためのオールインワンクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で開始して、AI ビジョンを現実のものにしましょう。



