

주요 요점
Llama 3.3 70B를 선택해야 할 때: 다국어 챗봇, 지능형 어시스턴트, AI 연구 등 애플리케이션에 적합하지만, 더 높은 하드웨어 리소스가 필요합니다.
Llama 3.3 70B에 부적합한 경우: 이미지나 오디오 처리가 필요한 경우
Mistral Nemo를 선택해야 할 때: 텍스트 생성 작업 및 함수 호출이 필요한 시나리오에 적합
Mistral Nemo에 부적합한 경우: 포괄적인 최고 수준의 벤치마크 점수를 원하는 경우
자신의 사용 사례에 맞게 Llama 3.3 70b 또는 Mistral Nemo를 평가하고 싶다면 — 가입 시 Novita AI에서 $0.5 크레딧을 제공합니다!
인공지능 분야는 빠르게 발전하고 있으며, Meta와 Mistral AI는 각각 차세대 언어 모델인 Llama 3.3 70B와 Mistral Nemo를 출시했습니다. 이번 출시는 업계에서 폭넓은 관심을 받고 있습니다. 이 글에서는 두 모델의 특징과 적용 시나리오를 종합적으로 분석하여 독자에게 완벽한 참고 자료를 제공합니다.
모델 제품군 기본 소개
비교를 시작하기에 앞서 각 모델의 기본 특성을 먼저 이해해 보겠습니다.
Llama 3.3 모델 제품군 특징
- 출시일: 2024년 12월 6일
- 모델 규모:
- 주요 혁신 사항:
- 명령어 튜닝(instruction-tuned) 버전만 제공
- 함수 호출 지원
- 다국어 대화에 최적화
- GQA 기술을 활용한 처리 효율성 향상
- 128K 토큰 컨텍스트 윈도우 지원
- 추론, 수학, 일반 지식에서 큰 개선
Mistral 모델 제품군 특징
- 출시일: 2024년 7월 19일
- 모델 규모:
- 주요 특징:
- 오픈소스 다국어 모델
- 128K 토큰 대규모 컨텍스트 윈도우
- 함수 호출 지원
- Tekken 토크나이저를 사용하여 효율성 향상
- 추론, 세계 지식, 코딩에 탁월
모델 비교
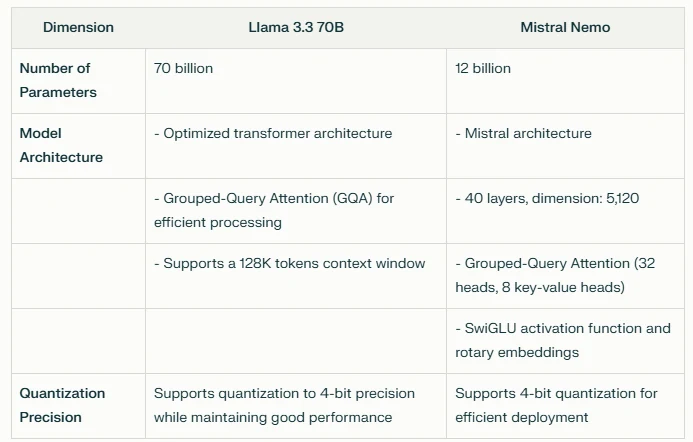
이 표는 두 모델 간의 매개변수, 아키텍처 설계 및 양자화 기능의 차이를 강조합니다. Llama 3.3 70B는 대규모 작업을 위해 훨씬 더 많은 매개변수 수와 최적화된 아키텍처를 제공하는 반면, Mistral Nemo는 효율적인 처리 기능을 갖춘 더 컴팩트한 디자인을 제공합니다. 두 모델 모두 배포 효율성 향상을 위한 양자화를 지원합니다.
벤치마크 비교
이제 각 모델의 기본 특성을 살펴보았으니, 다양한 벤치마크에서의 성능을 자세히 알아보겠습니다. 이 비교는 각 모델의 강점을 다양한 영역에서 확인하는 데 도움이 될 것입니다.
| 벤치마크 | 의미 | Llama 3.3 70b | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU(Massive Multitask Language Understanding)는 다양한 작업에서 일반 언어 이해도를 평가합니다. | 86 | 66 |
| HumanEval | HumanEval 은 주어진 문제 설명에 기반하여 올바른 Python 코드를 작성하는 모델의 능력을 테스트합니다. | 86 | 71 |
| MATH | MATH 는 모델의 수학적 문제 해결 능력을 평가합니다. | 76 | 44 |
| Artificial Analysis Multilingual Index | 여러 언어에 걸친 성능을 반영합니다. 다국어 MMLU(일반 추론)와 MGSM(수학적 추론) 평가 점수의 평균으로 계산됩니다. | 84 | <61 |
이 표에서 볼 수 있듯이 Llama 3.3 70b는 모든 차원에서 특히 강점을 보입니다.
Llama 3.3 벤치마크에 대해 더 자세히 알고 싶다면 다음 글을 참고하세요: Llama 3.3 Benchmark: 주요 장점 및 적용 인사이트.
Novita AI를 통한 속도 비교
직접 테스트해 보고 싶다면 Novita AI 웹사이트에서 무료 체험을 시작할 수 있습니다.
지연 시간
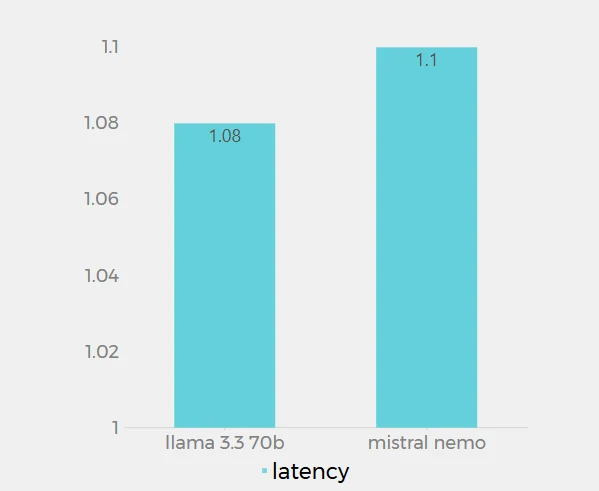
Novita AI에서 Llama 3.3 70B(1.08초)와 Mistral Nemo(1.1초)의 지연 시간 값은 0.02초 차이로 매우 가깝습니다. 이 데이터는 Novita AI 플랫폼에서 각 모델이 요청을 처리할 때의 응답 시간을 나타냅니다. Llama 3.3 70B가 약간 더 낮은 지연 시간을 보여 Mistral Nemo보다 약간 더 빠르게 응답함을 나타냅니다. 하지만 차이는 미미하며 대부분의 실제 애플리케이션에서 눈에 띄지 않을 수 있습니다. 두 모델 모두 낮은 지연 시간을 보여 빠른 응답에 잘 최적화되어 있음을 알 수 있습니다.
처리량 (초당 토큰 수)
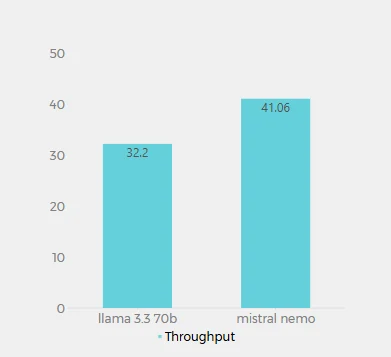
Novita AI에서 Llama 3.3 70B(32.2 토큰/초)와 Mistral Nemo(41.06 토큰/초)의 처리량 값은 각 모델이 초당 처리할 수 있는 토큰 수를 나타냅니다. 이 지표는 모델의 처리 속도와 효율성을 이해하는 데 중요합니다. Mistral Nemo는 더 높은 처리량을 보여 Llama 3.3 70B보다 초당 약 27.5% 더 많은 토큰을 처리합니다. 이는 Mistral Nemo가 텍스트 생성에서 더 효율적이며, 긴 출력에서 더 빠른 응답 시간을 제공할 가능성이 있음을 시사합니다.
하드웨어 요구 사항 비교
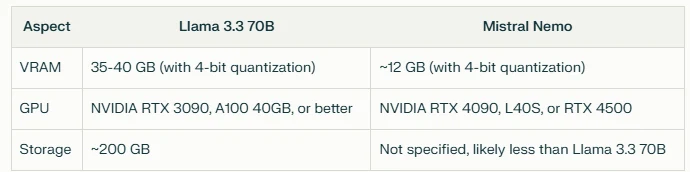
결론적으로 Mistral Nemo는 하드웨어 요구 사항 측면에서 더 효율적인 옵션으로 보이며, 리소스가 제한된 환경이나 효율성이 중요한 배포에 더 적합할 수 있습니다. 그러나 Llama 3.3 70B의 더 높은 리소스 요구 사항은 더 큰 모델 크기로 인해 특정 작업에서 더 나은 성능을 제공할 가능성으로 정당화될 수 있습니다.
애플리케이션 및 사용 사례
Llama 3.3 70B
- 다국어 챗봇 및 지능형 어시스턴트
- 코드 지원 및 소프트웨어 개발
- 합성 데이터 생성
- 다국어 콘텐츠 제작 및 현지화
- AI 연구 및 실험 플랫폼
- 지식 기반 애플리케이션 개발
- 소규모 팀을 위한 유연한 배포
Mistral Nemo
- 글로벌 다국어 애플리케이션, 특히 함수 호출이 필요한 시나리오에 적합
- 텍스트 생성 및 번역 작업
Novita AI를 통한 접근성 및 배포
1단계: 로그인 및 모델 라이브러리 접속
계정에 로그인하고 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.

4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공해 드립니다. 설정 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.

설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완료 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
가입 시 Novita AI에서 $0.5 크레딧을 제공합니다!
무료 크레딧을 모두 사용한 후에는 결제하여 계속 사용할 수 있습니다.
결론적으로 Llama 3.3 70B와 Mistral Nemo는 각각 고유한 특성을 가지고 있어 AI 애플리케이션 개발에 새로운 가능성을 제공합니다. 선택 시 특정 요구 사항을 고려하고 각 모델의 특징을 저울질하여 최상의 애플리케이션 효과를 얻어야 합니다. 기술이 계속 발전함에 따라 더 혁신적인 AI 언어 모델이 등장하여 인공지능 분야의 지속적인 발전을 이끌어가길 기대합니다.
자주 묻는 질문
Llama 3 70B에 필요한 RAM은 얼마인가요?
예상 RAM: 단일 GPU에서 Llama 3.1 70B를 실행하려면 일반적으로 약 350GB~500GB 의 GPU 메모리가 필요하며, 관련 시스템 RAM도 64GB~128GB 범위일 수 있습니다.
Llama 3가 GPT-4보다 더 나은가요?
당사 연구 결과에 따르면 Llama 3 70B는 클라우드 API 제공업체를 통해 사용할 경우 GPT-4보다 최대 50배 저렴하고 10배 더 빠를 수 있습니다. 소규모 평가를 통해 Llama 3 70B가 초등 수학, 산술 추론 및 요약 능력에 뛰어나다는 것을 알게 되었습니다.
Llama 3가 Claude보다 더 나은가요?
Llama 3는 다양한 입력을 이해하고 응답하는 뛰어난 능력으로 알려진 최고 수준의 모델입니다. 반면 Claude 3는 Haiku, Sonnet, Opus 등 다양한 버전으로 제공되며 각각 고유한 강점을 가지고 있습니다. Claude 3의 Opus 버전은 중요한 테스트에서 유명한 GPT-4를 능가하기도 했습니다.
Novita AI는 AI 비전을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구를 제공합니다. 인프라를 제거하고, 무료로 시작하여 AI 비전을 현실로 만드세요.



