

Puntos clave
Elige Llama 3.3 70B cuando: se necesiten aplicaciones como chatbots multilingües, asistentes inteligentes e investigación en IA, pero se requieran mayores recursos de hardware.
No es adecuado para Llama 3.3 70B cuando: se necesite procesamiento de imágenes o audio.
Elige Mistral Nemo cuando: se requieran tareas de generación de texto y escenarios que necesiten function calling.
No es adecuado para Mistral Nemo cuando: se busquen puntuaciones líderes completas en benchmarks.
Si estás buscando evaluar Llama 3.3 70B o Mistral Nemo en tus propios casos de uso — Al registrarte, Novita AI te proporciona un crédito de $0.5 para comenzar.
El campo de la inteligencia artificial está experimentando un desarrollo rápido, con Meta y Mistral AI presentando sus modelos de lenguaje de próxima generación, Llama 3.3 70B y Mistral Nemo, respectivamente. Estos lanzamientos han atraído una amplia atención en la industria. Este artículo proporcionará un análisis completo de las características y escenarios de aplicación de estos dos modelos, ofreciendo a los lectores una referencia exhaustiva.
Introducción básica de las familias de modelos
Para comenzar nuestra comparación, primero comprendamos las características fundamentales de cada modelo.
Características de la familia de modelos Llama 3.3
- Fecha de lanzamiento: 6 de diciembre de 2024
- Escala del modelo:
- Innovaciones clave:
- Solo disponible versión ajustada por instrucciones
- Soporta function calling
- Optimizado para diálogos multilingües
- Utiliza tecnología GQA para mejorar la eficiencia de procesamiento
- Soporta ventana de contexto de 128K tokens
- Mejoras significativas en razonamiento, matemáticas y conocimiento general
Características de la familia de modelos Mistral
- Fecha de lanzamiento: 19 de julio de 2024
- Escala del modelo:
- Características clave:
- Modelo multilingüe de código abierto
- Ventana de contexto grande de 128K tokens
- Soporta function calling
- Utiliza el tokenizador Tekken para mejorar la eficiencia
- Destaca en razonamiento, conocimiento del mundo y codificación
Comparación de modelos
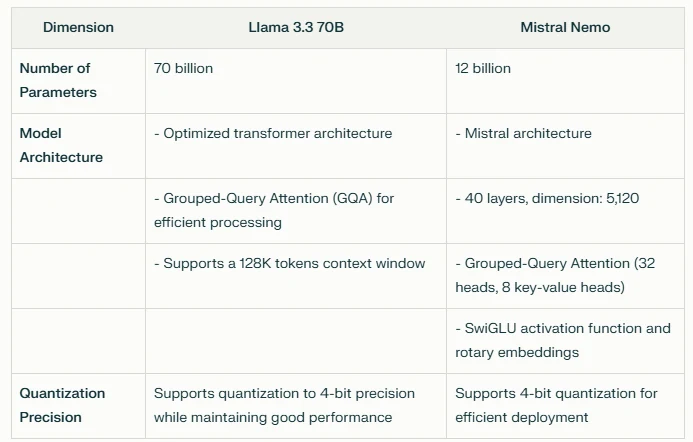
Esta tabla resalta las diferencias en parámetros, diseño arquitectónico y capacidades de cuantización entre los dos modelos. Llama 3.3 70B ofrece un número de parámetros significativamente mayor y una arquitectura optimizada para tareas de alta capacidad, mientras que Mistral Nemo proporciona un diseño más compacto con características de procesamiento eficiente. Ambos modelos admiten cuantización para mejorar la eficiencia de implementación.
Comparación de benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.
| Benchmark | Significado | Llama 3.3 70B | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU (Massive Multitask Language Understanding) evalúa la comprensión general del lenguaje en diversas tareas. | 86 | 66 |
| HumanEval | HumanEval prueba la capacidad de un modelo para escribir código Python correcto basado en descripciones de problemas dadas. | 86 | 71 |
| MATH | MATH evalúa las capacidades de resolución de problemas matemáticos de los modelos. | 76 | 44 |
| Artificial Analysis Multilingual Index | Refleja el rendimiento en varios idiomas. Se calcula como el promedio de las puntuaciones de Multilingual MMLU (razonamiento general) y MGSM (razonamiento matemático). | 84 | <61 |
Como podemos ver en esta tabla, Llama 3.3 70B demuestra fortalezas particulares en todas las dimensiones.
Si deseas obtener más información sobre el benchmark de Llama 3.3, puedes consultar el siguiente artículo: Llama 3.3 Benchmark: Ventajas clave y perspectivas de aplicación.
Comparación de velocidad a través de Novita AI
Si deseas probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.
Latencia
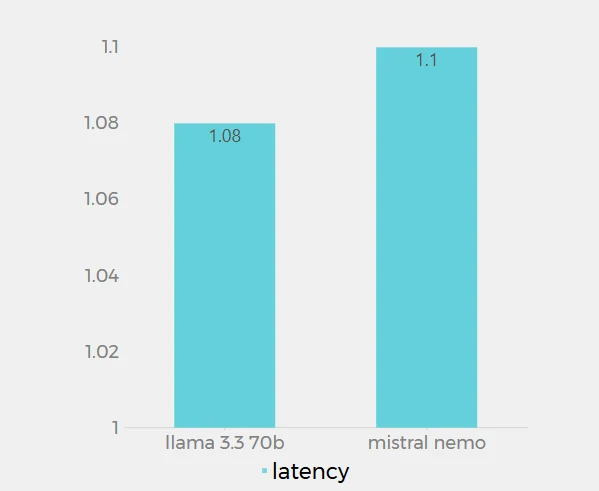
Los valores de latencia de Llama 3.3 70B (1.08 s) y Mistral Nemo (1.1 s) en Novita AI son muy cercanos, con solo 0.02 s de diferencia. Estos datos representan el tiempo de respuesta de cada modelo al procesar solicitudes en la plataforma Novita AI. Llama 3.3 70B muestra una latencia ligeramente menor, lo que indica que respuestas un poco más rápido que Mistral Nemo. Sin embargo, la diferencia es mínima y puede no ser perceptible en la mayoría de las aplicaciones prácticas. Ambos modelos demuestran baja latencia, lo que sugiere que ambos están bien optimizados para respuestas rápidas.
Rendimiento (tokens por segundo)
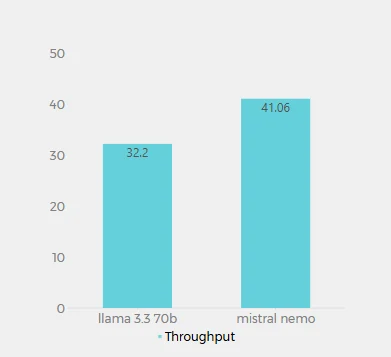
Los valores de rendimiento de Llama 3.3 70B (32.2 tokens/segundo) y Mistral Nemo (41.06 tokens/segundo) en Novita AI representan la cantidad de tokens que cada modelo puede procesar por segundo. Esta métrica es crucial para comprender la velocidad de procesamiento y eficiencia de los modelos. Mistral Nemo demuestra un mayor rendimiento, procesando aproximadamente un 27.5% más de tokens por segundo que Llama 3.3 70B. Esto sugiere que Mistral Nemo es más eficiente en la generación de texto, ofreciendo potencialmente tiempos de respuesta más rápidos para salidas más largas.
Comparación de requisitos de hardware
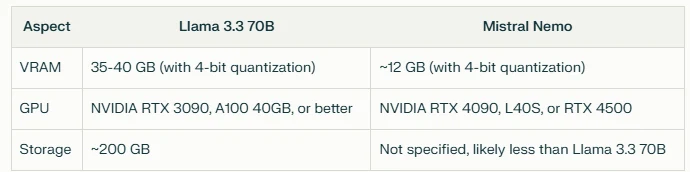
En conclusión, Mistral Nemo parece ofrecer una opción más eficiente en términos de requisitos de hardware, lo que podría hacerlo más adecuado para implementaciones con recursos limitados o donde la eficiencia sea una prioridad. Sin embargo, los requisitos de recursos más altos de Llama 3.3 70B podrían justificarse por su tamaño de modelo más grande, que potencialmente podría ofrecer un mejor rendimiento en ciertas tareas.
Aplicaciones y casos de uso
Llama 3.3 70B
- Chatbots multilingües y asistentes inteligentes
- Soporte de código y desarrollo de software
- Generación de datos sintéticos
- Creación y localización de contenido multilingüe
- Investigación en IA y plataformas experimentales
- Desarrollo de aplicaciones basadas en conocimiento
- Implementación flexible para equipos pequeños
Mistral Nemo
- Aplicaciones multilingües globales, especialmente adecuadas para escenarios que requieren function calling
- Tareas de generación de texto y traducción
Accesibilidad e implementación a través de Novita AI
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página Settings, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtén la clave API de Novita AI consultando: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<TU CLAVE API DE Novita AI>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # o False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Actúa como si fueras un asistente útil.",
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI proporciona un crédito de $0.5 para que puedas comenzar.
Si los créditos gratuitos se agotan, puedes pagar para continuar usándolo.
En conclusión, Llama 3.3 70B y Mistral Nemo tienen cada uno sus características únicas, ofreciendo nuevas posibilidades para el desarrollo de aplicaciones de IA. Al elegir, se deben considerar los requisitos específicos y sopesar las características de cada modelo para lograr el mejor efecto de aplicación. A medida que la tecnología continúa avanzando, esperamos ver más modelos de lenguaje innovadores de IA que impulsen el desarrollo continuo del campo de la inteligencia artificial.
Preguntas frecuentes
¿Cuánta RAM para Llama 3 70B?
RAM estimada: Generalmente se requieren alrededor de 350 GB a 500 GB de memoria de GPU para ejecutar Llama 3.1 70B en una sola GPU, y la RAM del sistema asociada también podría estar en el rango de 64 GB a 128 GB.
¿Es Llama 3 mejor que GPT-4?
Nuestros hallazgos muestran que Llama 3 70B puede ser hasta 50 veces más barato y 10 veces más rápido que GPT-4 cuando se usa a través de proveedores de API en la nube. Según nuestras evaluaciones a pequeña escala, aprendimos que Llama 3 70B es bueno en matemáticas de nivel escolar, razonamiento aritmético y capacidades de resumen.
¿Es Llama 3 mejor que Claude?
Llama 3 es un modelo de primer nivel conocido por sus increíbles habilidades para comprender y responder a diversas entradas. Por otro lado, Claude 3 viene en diferentes versiones como Haiku, Sonnet y Opus, cada una con fortalezas únicas. La versión Opus de Claude 3 incluso ha superado al famoso GPT-4 en pruebas importantes.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, serverless, instancia de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



