

Destaques Principais
Escolha Llama 3.3 70B quando: aplicações como chatbots multilíngues, assistentes inteligentes e pesquisa em IA, mas requer recursos de hardware mais elevados.
Não adequado para Llama 3.3 70B quando: for necessário processamento de imagem ou áudio.
Escolha Mistral Nemo quando: tarefas de geração de texto e cenários que exigem chamada de funções.
Não adequado para Mistral Nemo quando: buscar pontuações líderes abrangentes em benchmarks.
Se você está procurando avaliar o Llama 3.3 70B ou o Mistral Nemo nos seus próprios casos de uso — Ao se registrar, a Novita AI oferece um crédito de $0,5 para você começar!
O campo da inteligência artificial está passando por um rápido desenvolvimento, com a Meta e a Mistral AI apresentando seus modelos de linguagem de próxima geração, Llama 3.3 70B e Mistral Nemo, respectivamente. Esses lançamentos têm atraído ampla atenção na indústria. Este artigo fornecerá uma análise abrangente das características e cenários de aplicação desses dois modelos, oferecendo aos leitores uma referência completa.
Introdução Básica das Famílias de Modelos
Para iniciar nossa comparação, primeiro entendemos as características fundamentais de cada modelo.
Características da Família de Modelos Llama 3.3
- Data de lançamento: 6 de dezembro de 2024
- Escala do modelo:
- Principais inovações:
- Apenas versão ajustada por instruções disponível
- Suporte a chamada de funções
- Otimizado para diálogo multilíngue
- Utiliza tecnologia GQA para melhorar a eficiência de processamento
- Suporte a janela de contexto de 128K tokens
- Melhorias significativas em raciocínio, matemática e conhecimento geral
Características da Família de Modelos Mistral
- Data de lançamento: 19 de julho de 2024
- Escala do modelo:
- Principais características:
- Modelo multilíngue de código aberto
- Janela de contexto grande de 128K tokens
- Suporte a chamada de funções
- Usa tokenizador Tekken para melhorar a eficiência
- Excelente em raciocínio, conhecimento mundial e codificação
Comparação de Modelos
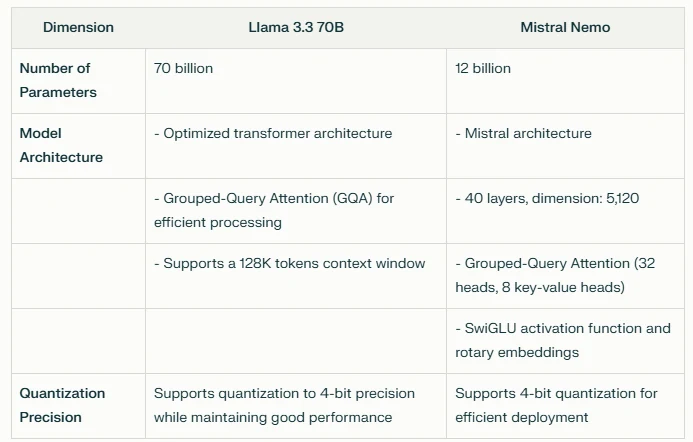
Esta tabela destaca as diferenças nos parâmetros, design arquitetônico e capacidades de quantização entre os dois modelos. O Llama 3.3 70B oferece uma contagem de parâmetros significativamente maior e uma arquitetura otimizada para tarefas de alta capacidade, enquanto o Mistral Nemo oferece um design mais compacto com recursos de processamento eficientes. Ambos os modelos suportam quantização para melhor eficiência de implantação.
Comparação de Benchmarks
Agora que estabelecemos as características básicas de cada modelo, vamos nos aprofundar em seu desempenho em vários benchmarks. Esta comparação ajudará a ilustrar seus pontos fortes em diferentes áreas.
| Benchmark | Significado | Llama 3.3 70B | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU (Massive Multitask Language Understanding) avalia a compreensão geral da linguagem em diversas tarefas. | 86 | 66 |
| HumanEval | HumanEval testa a capacidade de um modelo de escrever código Python correto com base em descrições de problemas. | 86 | 71 |
| MATH | MATH avalia as capacidades de resolução de problemas matemáticos dos modelos. | 76 | 44 |
| Artificial Analysis Multilingual Index | Reflete o desempenho em uma variedade de idiomas. Calculado como a média das pontuações de avaliação do Multilingual MMLU (raciocínio geral) e MGSM (raciocínio matemático). | 84 | <61 |
Como podemos ver nesta tabela, o Llama 3.3 70B demonstra pontos fortes particulares em todas as dimensões.
Se você quiser saber mais sobre o conhecimento de benchmark do llama3.3, pode consultar este artigo: Llama 3.3 Benchmark: Principais Vantagens e Insights de Aplicação.
Comparação de Velocidade via Novita AI
Se você quiser testar por conta própria, pode iniciar uma avaliação gratuita no site da Novita AI.
Latência
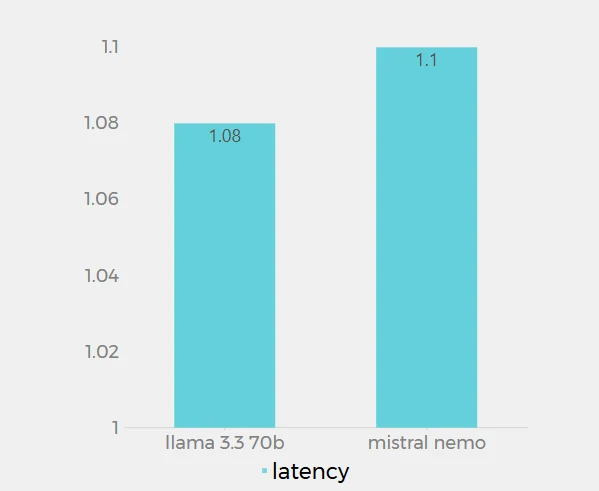
Os valores de latência para Llama 3.3 70B (1,08s) e Mistral Nemo (1,1s) na Novita AI são muito próximos, com apenas 0,02s de diferença. Esses dados representam o tempo de resposta de cada modelo ao processar solicitações na plataforma Novita AI. O Llama 3.3 70B mostra uma latência marginalmente menor, indicando que responde um pouco mais rápido que o Mistral Nemo. No entanto, a diferença é mínima e pode não ser perceptível na maioria das aplicações práticas. Ambos os modelos demonstram baixa latência, sugerindo que ambos são bem otimizados para respostas rápidas.
Throughput (Tokens por Segundo)
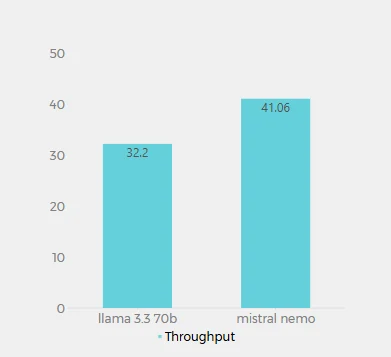
Os valores de throughput para Llama 3.3 70B (32,2 tokens/segundo) e Mistral Nemo (41,06 tokens/segundo) na Novita AI representam o número de tokens que cada modelo pode processar por segundo. Essa métrica é crucial para entender a velocidade e eficiência de processamento dos modelos. O Mistral Nemo demonstra um throughput maior, processando aproximadamente 27,5% mais tokens por segundo que o Llama 3.3 70B. Isso sugere que o Mistral Nemo é mais eficiente na geração de texto, potencialmente oferecendo tempos de resposta mais rápidos para saídas mais longas.
Comparação de Requisitos de Hardware
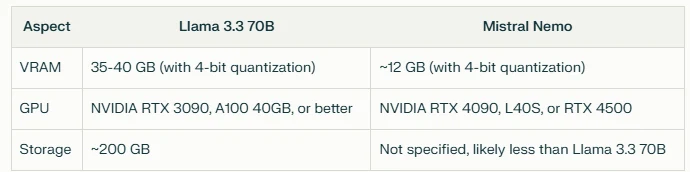
Em conclusão, o Mistral Nemo parece oferecer uma opção mais eficiente em termos de requisitos de hardware, potencialmente tornando-o mais adequado para implantações com recursos limitados ou onde a eficiência é prioritária. No entanto, os maiores requisitos de recursos do Llama 3.3 70B podem ser justificados pelo seu tamanho de modelo maior, que poderia oferecer melhor desempenho em certas tarefas.
Aplicações e Casos de Uso
Llama 3.3 70B
- Chatbots multilíngues e assistentes inteligentes
- Suporte a código e desenvolvimento de software
- Geração de dados sintéticos
- Criação e localização de conteúdo multilíngue
- Pesquisa em IA e plataforma experimental
- Desenvolvimento de aplicações baseadas em conhecimento
- Implantação flexível para pequenas equipes
Mistral Nemo
- Aplicações multilíngues globais, especialmente adequadas para cenários que exigem chamada de funções
- Tarefas de geração de texto e tradução
Acessibilidade e Implantação através da Novita AI
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie sua avaliação gratuita
Comece sua avaliação gratuita para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acesse a página “Settings” e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtenha a chave de API da Novita AI consultando: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<SUA CHAVE DE API Novita AI>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # ou False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Aja como se você fosse um assistente útil.",
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Ao se registrar, a Novita AI oferece um crédito de $0,5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
Em conclusão, o Llama 3.3 70B e o Mistral Nemo têm cada um suas características únicas, oferecendo novas possibilidades para o desenvolvimento de aplicações de IA. Ao escolher, deve-se considerar os requisitos específicos e ponderar as características de cada modelo para alcançar o melhor efeito de aplicação. À medida que a tecnologia continua a avançar, esperamos ver mais modelos de linguagem de IA inovadores surgirem, impulsionando o desenvolvimento contínuo do campo da inteligência artificial.
Perguntas Frequentes
Quanta RAM é necessária para o Llama 3 70B?
RAM estimada: Cerca de 350 GB a 500 GB de memória GPU são tipicamente necessários para executar o Llama 3.1 70B em uma única GPU, e a RAM do sistema associada também pode estar na faixa de 64 GB a 128 GB.
O Llama 3 é melhor que o GPT-4?
Nossas descobertas mostram que o Llama 3 70B pode ser até 50 vezes mais barato e 10 vezes mais rápido que o GPT-4 quando usado através de provedores de API em nuvem. Com base em avaliações em pequena escala, aprendemos que o Llama 3 70B é bom em matemática de nível escolar, raciocínio aritmético e capacidades de sumarização.
O Llama 3 é melhor que o Claude?
O Llama 3 é um modelo de primeira linha conhecido por suas incríveis habilidades em entender e responder a várias entradas. Por outro lado, o Claude 3 vem em versões diferentes como Haiku, Sonnet e Opus, cada uma com pontos fortes únicos. A versão Opus do Claude 3 superou até mesmo o famoso GPT-4 em testes importantes.
Novita AI é a plataforma All-in-one em nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



