

NVIDIA’s H200 SXM and RTX 5090 rank among the most powerful GPUs of their class, yet they serve entirely different purposes in the AI ecosystem. RTX 5090 excels at high-speed inference and smaller-scale fine-tuning, while H200 SXM is optimized for large-scale training and multi-GPU deployment in data centers.
This article compares both GPUs across architecture, memory, performance, and cost to help you determine whether your workloads truly demand a data-center GPU—or if a single RTX 5090 can already meet your AI goals.
H200 vs 5090: Detailed Specifications
| Detail | H200 SXM | RTX 5090 |
| Release Date | 18 November 2024 | 30 January 2025 |
| Architecture | Hopper | Blackwell |
| GPU Memory | 141 GB HBM3e | 32 GB GDDR7 |
| Memory Interface | 6144-bit | 512-bit |
| Memory Bandwidth | 4.8 TB/s | 1.792 TB/s |
| NVIDIA Decoder | 7x NVDEC & 7x JPEG | 3x 9th Gen |
| CUDA Cores | 16896 | 21760 |
| Tensor Cores | 528 | 680 |
| Total Graphics Power | up to 700W | 575W |
H200 vs 5090: Comprehensive Performance Review
The NVIDIA H200 SXM and RTX 5090 serve two fundamentally different markets. While the RTX 5090 is engineered to push consumer and creator workloads to new heights, the H200 SXM is purpose-built for data-center-scale AI, where throughput, memory capacity, and cluster deployment are critical.
To choose wisely, it’s essential to evaluate how their strengths align with your real workload demands.
🟩 RTX 5090: The Top-Tier Consumer GPU
Designed for enthusiasts, developers, and creators, the RTX 5090 focuses on raw speed, flexibility, and broad application coverage. It enables fast iteration and AI experimentation as long as the model fits within consumer GPU memory budgets.
- Maximum Throughput for Local Prototyping
With its ultra-wide memory bandwidth and powerful Tensor/RT cores, it excels at fast model iteration, rendering, and mixed creative-AI workflows.- Affordable Entry to High-End AI
As a consumer-class GPU, it delivers exceptional price-performance for users who want cutting-edge compute without enterprise infrastructure.- Consistent Real-Time Responsiveness
The RTX 5090’s high clock speeds and efficient architecture enable stable frame generation and quick inference cycles, ideal for testing or live creative sessions where latency matters.- Streamlined AI Development and Deployment
The RTX 5090 enables efficient local fine-tuning, inference, and model optimization, allowing developers to iterate and scale AI workloads seamlessly without relying on complex cloud infrastructure.
🟦 H200 SXM:The High-End Enterprise AI GPU
Engineered for mission-critical data center deployment, the H200 prioritizes memory capacity, throughput efficiency, and multi-GPU scalability for modern generative AI systems.
- Massive Memory for Production-Grade Models
Equipped with 141GB HBM3e, it handles large language models, dense retrieval, and long-context inference with minimal sharding overhead.- High-Reliability Enterprise Performance
Designed for consistent uptime, thermal efficiency, and tightly controlled error correction for mission-critical workloads.- Maximized Cluster Efficiency
NVLink and fifth-gen NVSwitch support high-bandwidth interconnect across multiple GPUs, ideal for distributed training and scaling LLMs.- FP8 & Transformer Engine Optimization
Accelerates state-of-the-art generative AI, enabling outstanding training and inference throughput in optimized frameworks (NVIDIA NIM, TensorRT-LLM).
Takeaway
- RTX 5090 → Best for individuals or small teams prioritizing speed, flexibility, and cost-effectiveness in local workflows—ideal for rapid prototyping and creative AI.
- H200 SXM → Best for enterprise AI environments needing scalability, massive memory, and ultra-reliable compute for large-scale deployments and 24/7 stability.
Which One Should You Choose?
Choosing between the RTX 5090 and H200 SXM ultimately depends on your deployment environment, budget, and the scale of your models — not just performance scores on paper.
How large are the models you plan to run locally?
If your model weights (plus KV cache and activations) can fit within 32GB VRAM (or can be quantized to do so), the RTX 5090 is an excellent local solution.
If they exceed that limit or require high-throughput distributed compute, the H200 SXM is purpose-built for that scale.
🔍 Quick Decision Guide
| Your Need / Use Case | Recommended GPU | Why |
|---|---|---|
| Fast iteration, local AI prototyping, creative workloads | RTX 5090 | Strong price-performance + broad workload support |
| 7B–14B models in FP16, or 30B quantized | RTX 5090 | 32GB VRAM is sufficient for most medium-scale LLMs |
| ≥70B LLMs, long-context inference | H200 SXM | 141GB HBM3e ensures full model + KV cache residency |
| Mission-critical production deployments | H200 SXM | Enterprise-grade reliability, ECC memory, thermal control |
| NVLink multi-GPU scaling & clusters | H200 SXM | Designed for parallel training & distributed workloads |
| High concurrency and throughput | H200 SXM | Optimized for data center workloads |
H200 vs 5090: Pricing
| GPU | Typical Price | Notes |
|---|---|---|
| RTX 5090 | ~ US$1,999 (MSRP) | Consumer-grade graphics card, 32 GB GDDR7 memory, aimed at gamers & creators. |
| H200 SXM (single GPU) | US$30,000 ~ US$40,000 per unit | Data centre-grade GPU, 141 GB HBM3e memory, built for large-scale AI deployment. |
| H200 Series (board/system) | 4-GPU board ≈ US$175,000, 8-GPU board ≈ US$308,000 ~ 315,000 | Entire multi-GPU system including multiple H200 units, NVLink/NVSwitch board, server infrastructure. |
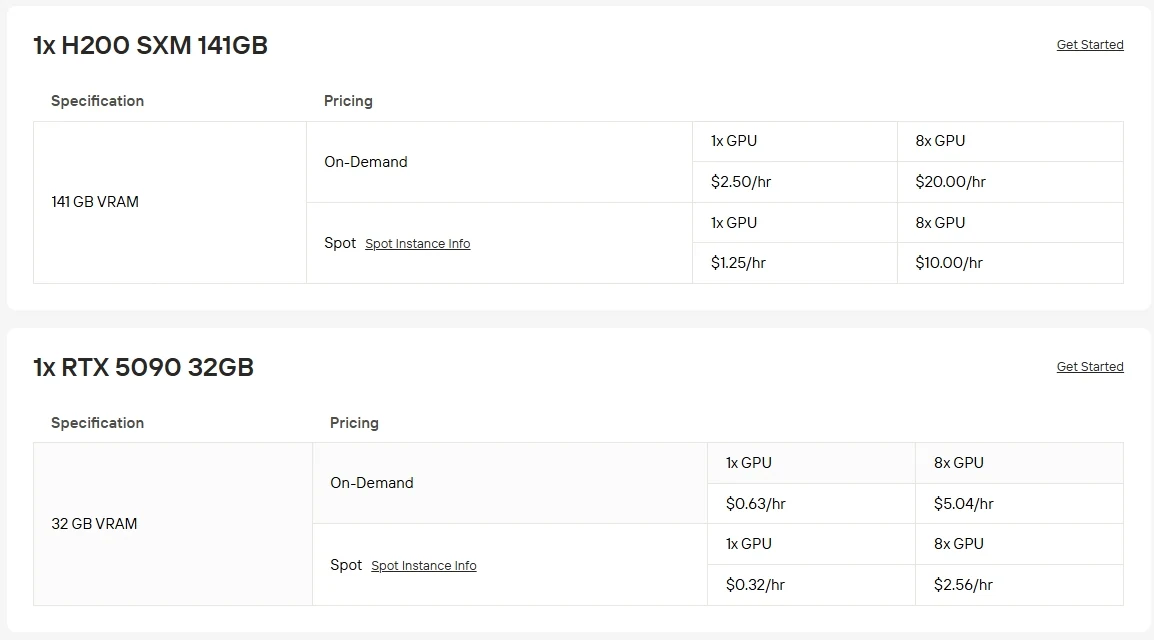
Running top-tier GPUs on your own hardware can be expensive and difficult to maintain. With Novita AI’s GPU Instance service, you can quickly spin up cloud access to an RTX 5090 for just $0.63/hr or an H200 SXM for $2.5/hr with no local setup required. You can also choose from multiple billing options: Spot instances offer lower prices with fluctuating availability, On-Demand lets you pay only when you use it, and Subscription plans provide consistent savings for stable, long-term workloads.
Get Started with Flexible GPU Instances on Novita AI
Novita AI offers scalable RTX 5090 and H200 GPU resources in the cloud, removing the need to purchase and manage costly hardware for intensive computing workloads.
Step1:Sign up for your account
Create your Novita AI account through our website. After registration, go to the “GPUs” tab to view available resources and begin your journey.
Step2:Select Your GPU
We offer multiple pre-configured templates to match diverse needs, while also giving you the flexibility to build custom ones. With access to powerful RTX 5090 and RTX 6000 Ada GPUs equipped with ample VRAM and RAM, our service enables efficient training even for highly complex AI models.
Pre-configured Template Library
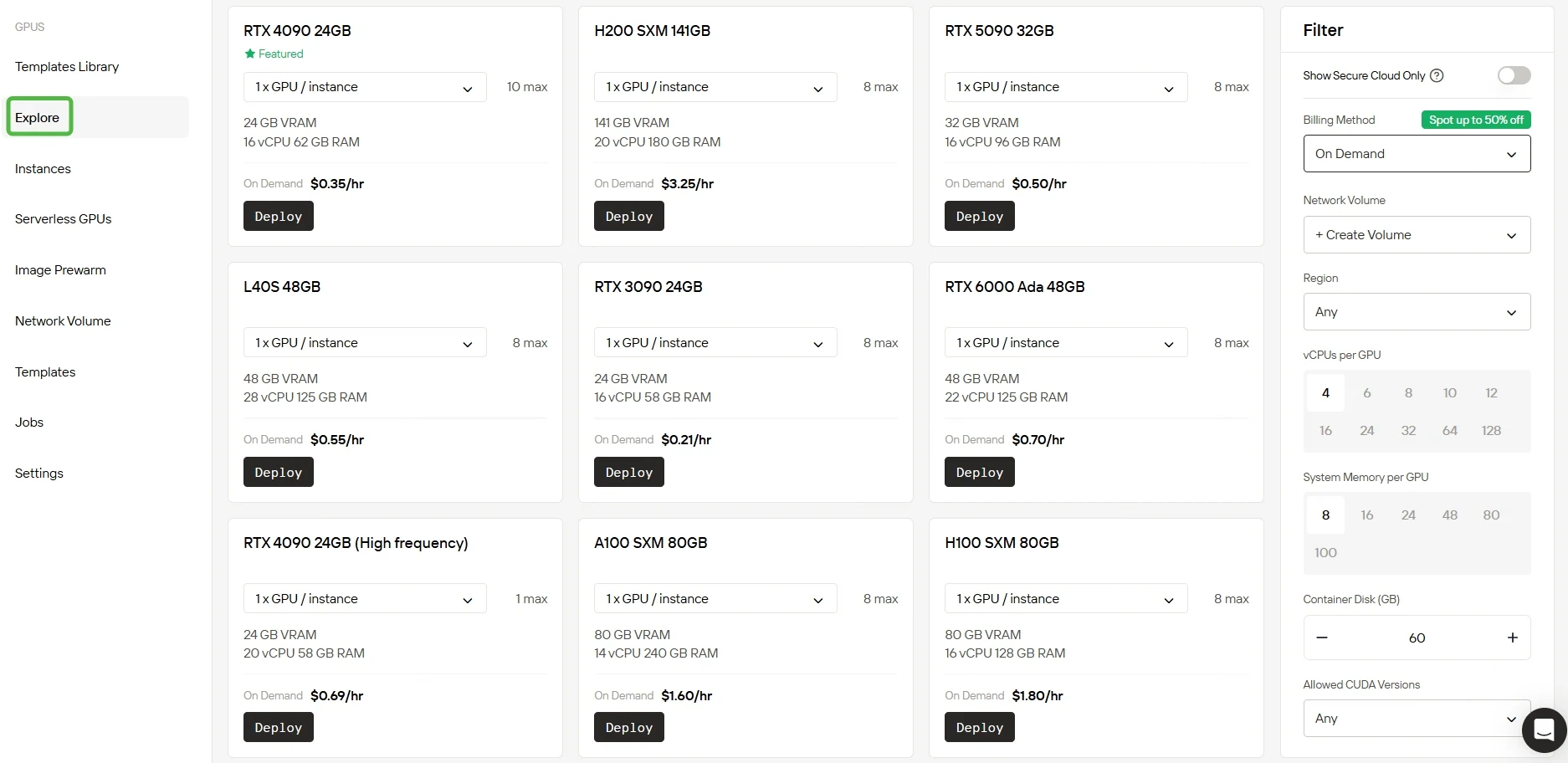
Explore Diverse GPU Options
Step3:Customize Your Deployment
Set up your environment with the operating system and configuration that align with your compute requirements, optimizing throughput for AI workloads. You’ll receive 60GB of free container disk space at launch, with easy scaling to additional storage as your project footprint grows.
Step4:Launch Your Instance
Click “Deploy” to initiate your deployment. Within minutes, your high-performance GPU environment will be ready, enabling you to begin machine learning, rendering, or computational projects right away.
Frequently Asked Questions
What is the main difference between the RTX 5090 and the H200 SXM?
The RTX 5090 is a consumer-grade GPU designed for high-performance desktops; In contrast, the H200 SXM is a data-center-class GPU built for large-scale AI deployment, featuring enterprise-grade reliability, NVLink scalability, and massive HBM3e memory to support large models and high-throughput workloads.
What AI workloads actually require an H200 SXM?
Workloads involving 70B+ models, long context inference, distributed training, or high concurrency benefit significantly from the H200’s memory and interconnect bandwidth.
Is the RTX 5090 enough for running large language models locally?
Yes — as long as the model fits within 32GB VRAM or can be quantized. Models around 7B–14B parameters run smoothly; 30B may work with aggressive optimizations.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



