

Points clés
Analyse texte-image : Qwen2.5-VL excelle dans l’extraction et l’analyse de texte, graphiques, icônes et mises en page à partir d’images.
Capacités d’agent : Agit comme un agent visuel, prenant en charge des tâches telles que la gestion de smartphones et d’ordinateurs.
Compréhension vidéo : Traite de longues vidéos (1 heure ou plus) avec un repérage précis des événements.
Accès économique : Novita AI propose une option API abordable pour éviter les coûts matériels élevés.
Qwen2.5-VL est le dernier modèle phare de vision-langage de la série Qwen, marquant une avancée significative par rapport à son prédécesseur, Qwen2-VL. Le modèle Qwen2.5-VL-72B-Instruct est une version affinée pour les instructions avec 72 milliards de paramètres, conçue pour être un modèle de vision-langage plus efficace et pratique, basé sur les précieux retours des développeurs.
Qu’est-ce que Qwen2.5-VL-72B-Instruct ?
Qwen2.5-VL-72B-Instruct est un grand modèle de vision-langage (LVLM) avec 72 milliards de paramètres, affiné pour les tâches basées sur des instructions. Il est capable de comprendre et d’analyser des entrées visuelles (images/vidéos) et textuelles pour effectuer un large éventail de tâches. Les principales améliorations par rapport à Qwen2-VL incluent :
- Compréhension visuelle améliorée : Compétent pour reconnaître des objets courants, analyser du texte, des graphiques, des icônes, des dessins et des mises en page dans les images.
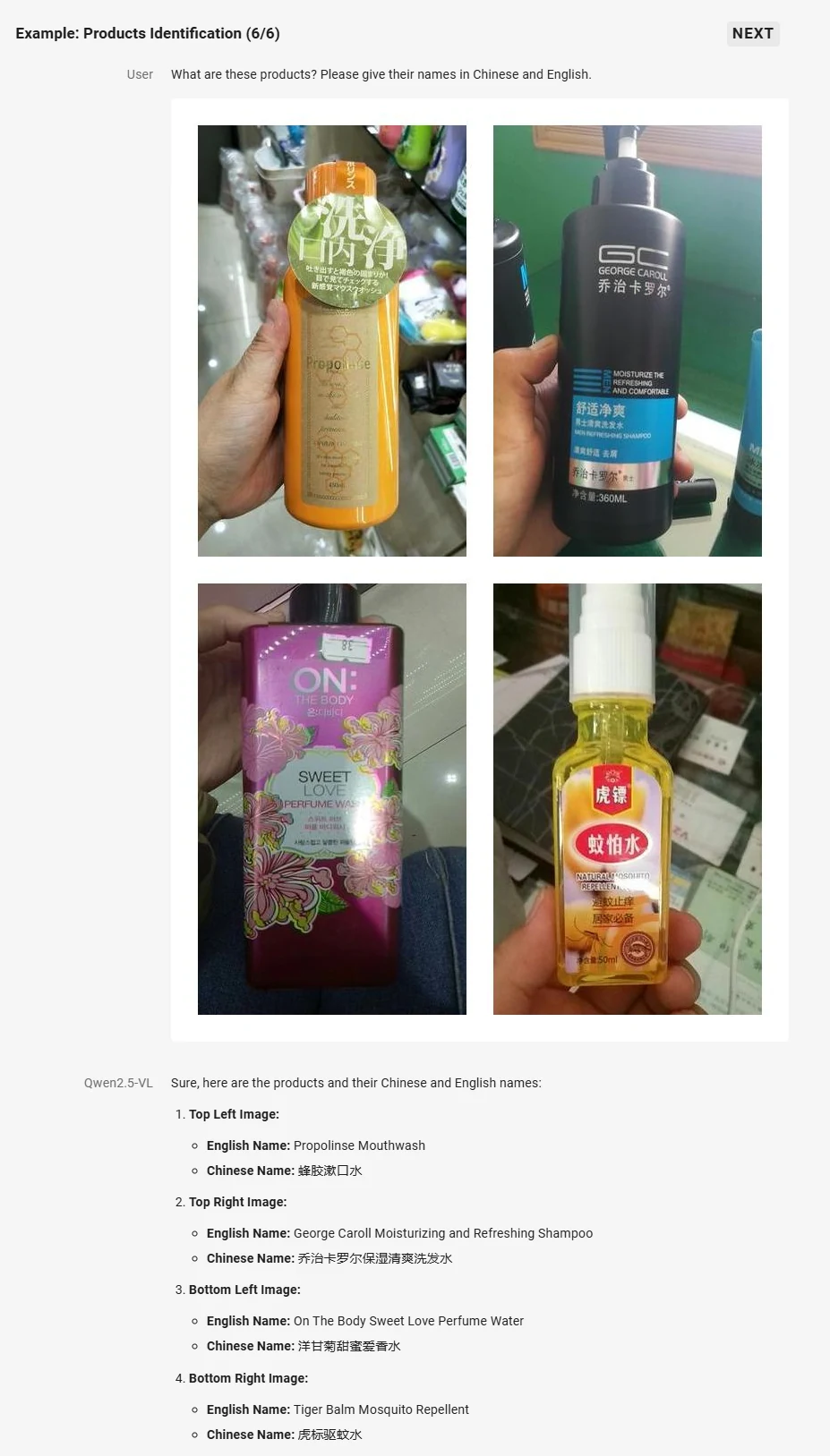
Source : Qwen
- Capacités d’agent : Agit comme un agent visuel capable de raisonner et de diriger dynamiquement des outils pour une utilisation sur ordinateur et téléphone.
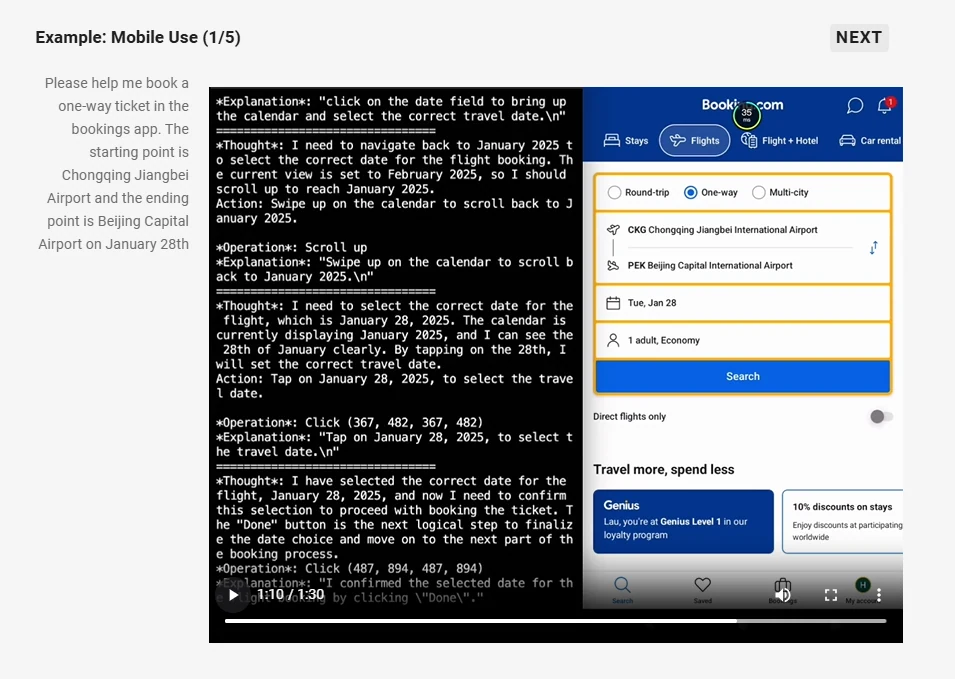
Source : Qwen
- Compréhension vidéo améliorée : Peut comprendre des vidéos de plus d’une heure, repérer les segments vidéo pertinents et prend en charge l’entraînement FPS dynamique et le codage temporel absolu pour une meilleure compréhension temporelle.

Source : Qwen
- Localisation précise des objets : Détecte avec précision les objets dans une image à l’aide de boîtes englobantes/points et fournit des sorties JSON stables pour les coordonnées et les attributs.
- Génération de sortie structurée : Prend en charge les sorties structurées pour les factures scannées et les tableaux, bénéficiant aux applications financières et commerciales.

Source : Qwen
Benchmark Qwen2-VL-72B-Instruct
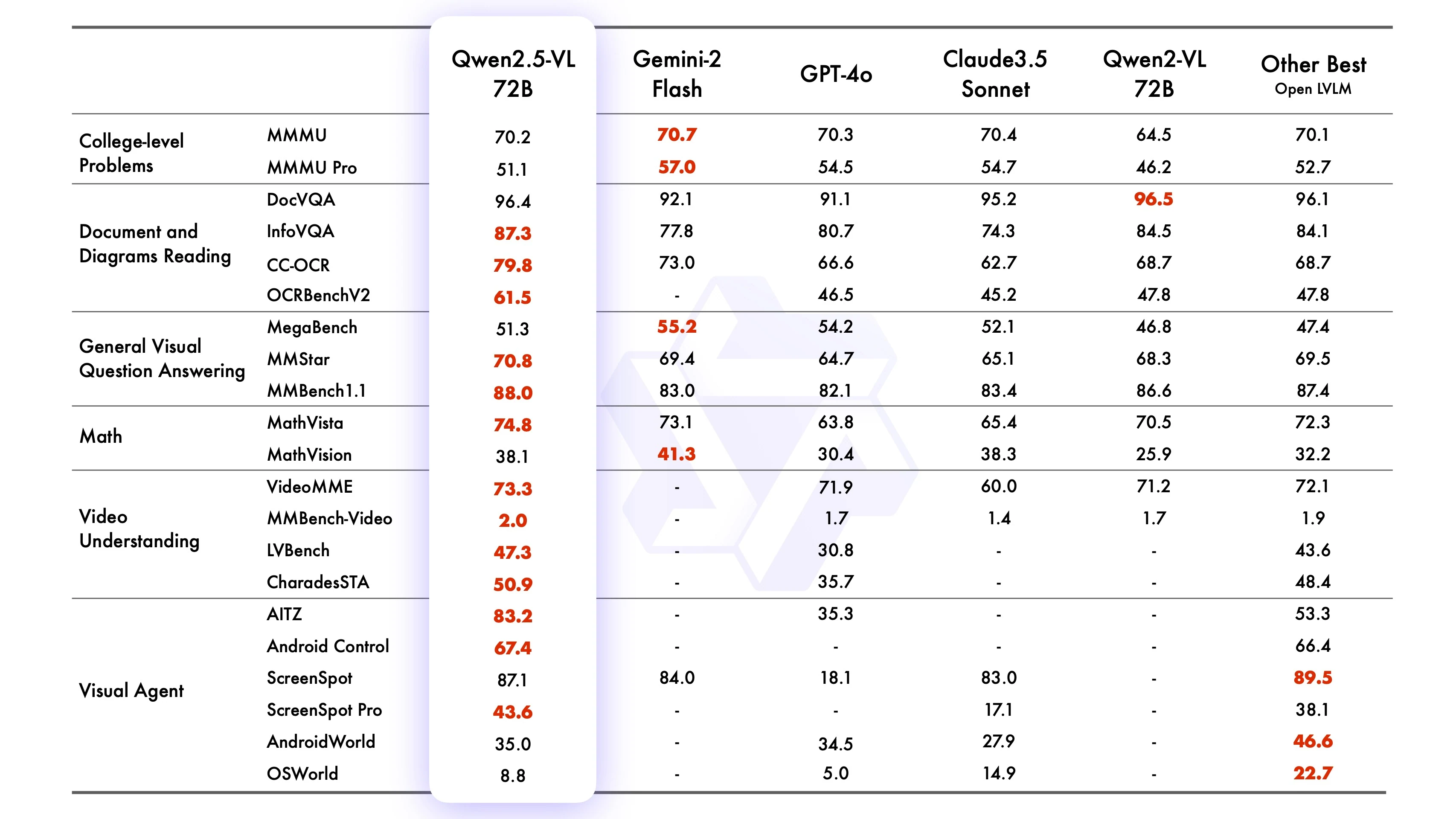
Source : Qwen
Qwen2.5-VL-72B-Instruct a démontré des performances compétitives ou supérieures sur de nombreux benchmarks, excellant dans les tâches d’image (par exemple, MMMUval, MathVista_MINI, DocVQA_VAL), les tâches vidéo (par exemple, VideoMME, MVBench, EgoSchema) et les tâches basées sur des agents (par exemple, ScreenSpot, Android Control, MobileMiniWob++_SR). Il surpasse souvent Qwen2-VL-72B et rivalise avec des modèles de premier plan comme GPT4o, Claude3.5 Sonnet et Gemini 2.0. De plus, Qwen2.5-VL-7B surpasse GPT-4o-mini dans plusieurs tâches, tandis que Qwen2.5-VL-3B dépasse la version 7B de Qwen2-VL.
Configuration matérielle requise pour Qwen2-VL-72B-Instruct
| Modèle de GPU | VRAM par GPU | GPUs utilisés | VRAM totale | Coût estimé |
|---|---|---|---|---|
| Nvidia A100 (80 Go) | 80 Go | 8 GPUs | 640 Go | Environ 205 496 $ |
| Nvidia H100 (80 Go) | 80 Go | 8 GPUs | 640 Go | Environ 200 000 $ - 320 000 $ |
| Nvidia RTX 4090 | 24 Go | 24 GPUs | 576 Go | Environ 57 600 $ - 66 120 $ |
| Nvidia L40S | 48 Go | 8 GPUs | 384 Go | Environ 46 799,60 $ - 83 712,80 $ |
Pour exécuter Qwen2-VL-72B-Instruct, le Nvidia A100 (80 Go) est la meilleure option polyvalente, équilibrant coût, VRAM et performances. Le H100 (80 Go) convient aux organisations priorisant les performances, tandis que le RTX 4090 et le L40S sont viables pour des configurations budgétaires, bien qu’ils comportent des compromis en termes de complexité et de VRAM.
Test de Qwen2-VL-72B-Instruct
Entrée : Donnez la requête : « l’utilisateur utilise la fonction de génération d’images », quand le contenu décrit se produit-il dans la vidéo ? Utilisez les secondes pour le format temporel.
Sortie : Le contenu décrit se produit de la 28e à la 50e seconde dans la vidéo. Pendant ce segment, l’utilisateur interagit avec la fonction de génération d’images, demandant et recevant une peinture de scène double artistique d’une montagne de jour et de nuit. L’utilisateur ajoute ensuite un oiseau à l’image générée, démontrant ainsi la fonctionnalité de l’outil de génération d’images.
Comment accéder à Qwen2-VL-72B-Instruct ?
Novita AI est une plateforme cloud AI qui offre aux développeurs un moyen facile de déployer des modèles AI via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez la démo de Qwen2-VL-72B-Instruct maintenant !
Étape 2 : Commencez votre essai gratuit
Débutez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B-Instruct représente une avancée majeure dans les modèles de vision-langage, améliorant la compréhension visuelle, la compréhension vidéo, les capacités d’agent, la localisation et la génération de sortie structurée. Grâce à un entraînement à résolution dynamique et à un encodeur visuel efficace, il atteint des performances de benchmark supérieures dans les tâches d’image, de vidéo et d’agent.
Questions fréquemment posées
Comment Qwen2.5-VL-instruct améliore-t-il la compréhension visuelle ?
Il analyse le texte (multilingue, vertical), les graphiques, les icônes et les mises en page tout en extrayant les informations clés et en convertissant les documents dans des formats structurés comme HTML.
Quelles sont les nouvelles capacités vidéo de Qwen2.5-VL-instruct ?
Il traite des vidéos de plus d’une heure, repère les événements à la seconde près, effectue un ancrage temporel, génère des légendes structurées et résume le contenu.
Quel matériel est recommandé pour exécuter Qwen2.5-VL-instruct ?
Pour une utilisation locale, un GPU avec au moins 384 Go de VRAM est recommandé. Ou vous pouvez choisir une API efficace comme Novita AI pour l’utiliser !
Novita AI est une plateforme cloud AI qui offre aux développeurs un moyen facile de déployer des modèles AI via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer.



