

Destaques Principais
Análise de Texto para Imagem: O Qwen2.5-VL se destaca na extração e análise de texto, gráficos, ícones e layouts a partir de imagens.
Capacidades de Agente: Atua como um agente visual, suportando tarefas como gerenciamento de smartphones e computadores.
Compreensão de Vídeo: Processa vídeos longos (mais de 1 hora) com localização precisa de eventos.
Acesso Eficiente: A Novita AI oferece uma opção de API acessível para evitar altos custos de hardware.
O Qwen2.5-VL é o mais recente modelo de visão-linguagem flagship da série Qwen, representando um salto significativo em relação ao seu predecessor, o Qwen2-VL. O modelo Qwen2.5-VL-72B-Instruct é uma versão ajustada por instruções com 72 bilhões de parâmetros, projetado para ser um modelo de visão-linguagem mais eficaz e prático, com base em valiosos feedbacks de desenvolvedores.
O que é o Qwen2.5-VL-72B-Instruct?
O Qwen2.5-VL-72B-Instruct é um modelo de visão-linguagem de grande escala (LVLM) com 72 bilhões de parâmetros, ajustado para tarefas baseadas em instruções. Ele é capaz de compreender e analisar entradas visuais (imagens/vídeos) e textuais para realizar uma ampla gama de tarefas. As principais melhorias em relação ao Qwen2-VL incluem:
- Compreensão Visual Aprimorada: Proficiente em reconhecer objetos comuns, analisar texto, gráficos, ícones, imagens e layouts dentro de imagens.
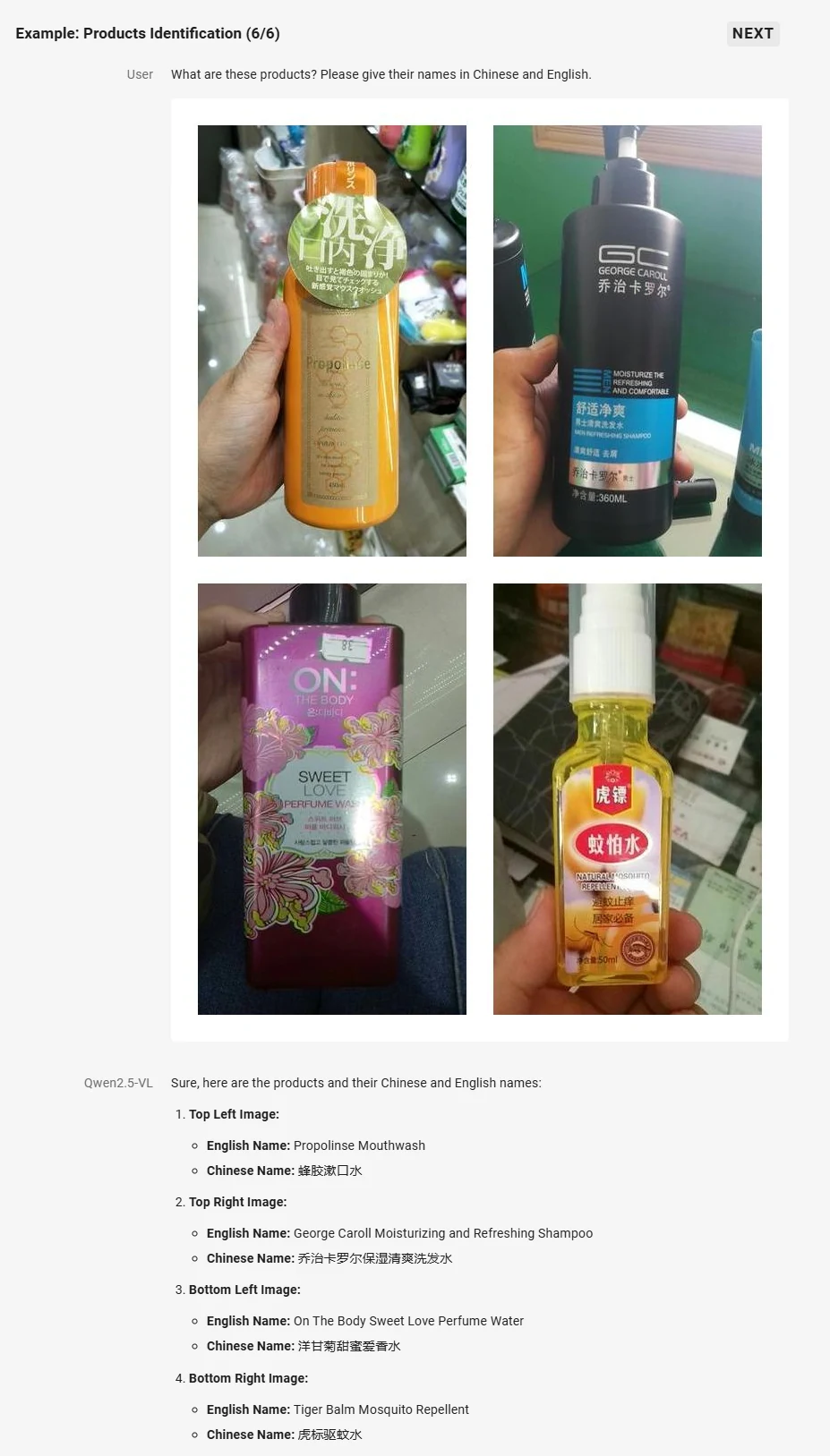
Fonte: Qwen
- Capacidades de Agente: Atua como um agente visual capaz de raciocinar e direcionar dinamicamente ferramentas para uso em computadores e celulares.
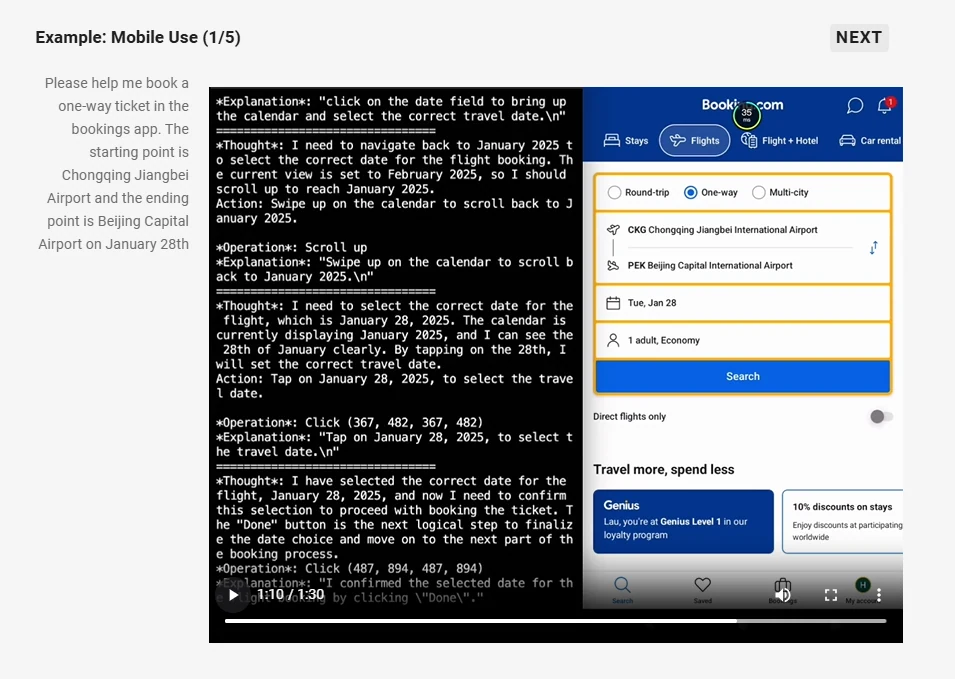
Fonte: Qwen
- Compreensão de Vídeo Aprimorada: Consegue compreender vídeos com mais de uma hora, localizar segmentos de vídeo relevantes e suporta treinamento dinâmico de FPS e codificação absoluta de tempo para melhor compreensão temporal.

Fonte: Qwen
- Localização Precisa de Objetos: Detecta objetos com precisão em uma imagem usando caixas delimitadoras/pontos e fornece saídas JSON estáveis para coordenadas e atributos.
- Geração de Saída Estruturada: Suporta saídas estruturadas para faturas e tabelas digitalizadas, beneficiando aplicações em finanças e comércio.

Fonte: Qwen
Benchmark do Qwen2-VL-72B-Instruct
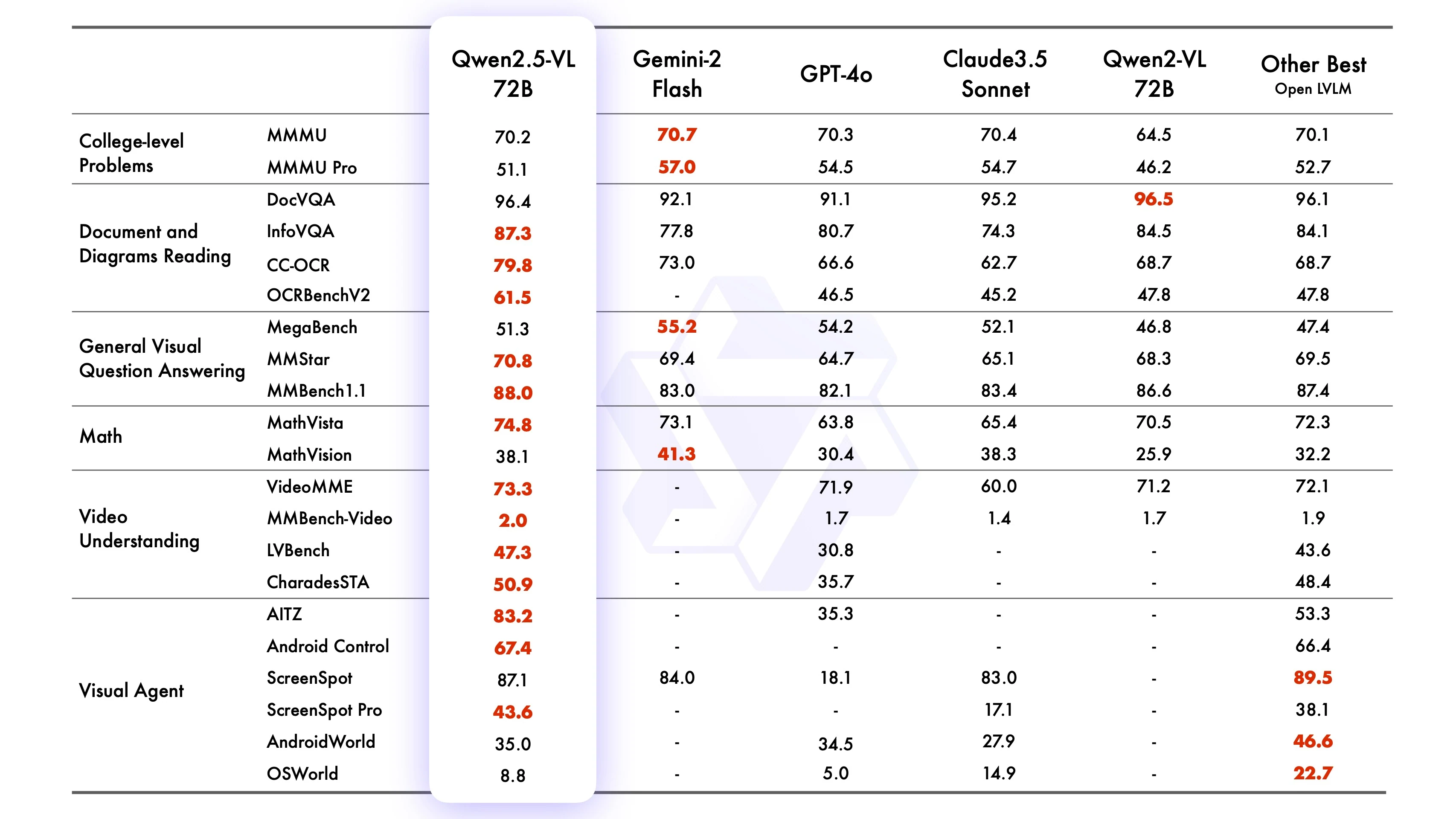
Fonte: Qwen
O Qwen2.5-VL-72B-Instruct demonstrou desempenho competitivo ou superior em diversos benchmarks, destacando-se em tarefas de imagem (ex.: MMMUval, MathVista_MINI, DocVQA_VAL), tarefas de vídeo (ex.: VideoMME, MVBench, EgoSchema) e tarefas baseadas em agentes (ex.: ScreenSpot, Android Control, MobileMiniWob++_SR). Frequentemente supera o Qwen2-VL-72B e rivaliza com modelos líderes como GPT4o, Claude3.5 Sonnet e Gemini 2.0. Além disso, o Qwen2.5-VL-7B supera o GPT-4o-mini em várias tarefas, enquanto o Qwen2.5-VL-3B supera a versão de 7B do Qwen2-VL.
Requisitos de Hardware do Qwen2-VL-72B-Instruct
| Modelo de GPU | VRAM por GPU | GPUs Utilizadas | VRAM Total | Custo Estimado |
|---|---|---|---|---|
| Nvidia A100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Aproximadamente $205.496 |
| Nvidia H100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Aproximadamente $200.000 - $320.000 |
| Nvidia RTX 4090 | 24 GB | 24 GPUs | 576 GB | Aproximadamente $57.600 - $66.120 |
| Nvidia L40S | 48 GB | 8 GPUs | 384 GB | Aproximadamente $46.799,60 - $83.712,80 |
Para executar o Qwen2-VL-72B-Instruct, a Nvidia A100 (80 GB) é a melhor opção geral, equilibrando custo, VRAM e desempenho. A H100 (80 GB) é adequada para organizações que priorizam desempenho, enquanto a RTX 4090 e a L40S são viáveis para configurações com orçamento limitado, embora apresentem compensações em complexidade e VRAM.
Teste do Qwen2-VL-72B-Instruct
Entrada: Forneça a consulta: “o usuário está experimentando o recurso de geração de imagens”, quando o conteúdo descrito ocorre no vídeo? Use segundos para o formato de tempo.
Saída: O conteúdo descrito ocorre de 28 segundos a 50 segundos no vídeo. Durante este segmento, o usuário interage com o recurso de geração de imagens, solicitando e recebendo uma pintura artística de cena dupla de uma montanha durante o dia e a noite. O usuário então adiciona um pássaro à imagem gerada, demonstrando a funcionalidade da ferramenta de geração de imagens.
Como Acessar o Qwen2-VL-72B-Instruct?
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Experimente o Qwen2-VL-72B-Instruct Demo Agora!
Passo 2: Inicie seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 3: Obtenha sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Entrando na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 4: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O Qwen2.5-VL-72B-Instruct representa um grande avanço em modelos de visão-linguagem, melhorando a compreensão visual, compreensão de vídeo, capacidades de agente, localização e geração de saída estruturada. Com treinamento de resolução dinâmica e um codificador visual eficiente, ele alcança desempenho superior em benchmarks em tarefas de imagem, vídeo e agente.
Perguntas Frequentes
Como o Qwen2.5-VL-instruct melhora a compreensão visual?
Ele analisa texto (multilíngue, vertical), gráficos, ícones e layouts, extraindo informações importantes e convertendo documentos em formatos estruturados como HTML.
Quais são as novas capacidades de vídeo do Qwen2.5-VL-instruct?
Processa vídeos com mais de 1 hora, localiza eventos ao segundo, realiza ancoragem temporal, gera legendas estruturadas e resume conteúdo.
Qual é o hardware recomendado para executar o Qwen2.5-VL-instruct?
Para uso local, recomenda-se uma GPU com pelo menos 384 GB de VRAM. Ou você pode escolher uma API eficaz como a da Novita AI para usá-lo!
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



