

Ключевые особенности
Анализ текста в изображениях: Qwen2.5-VL отлично справляется с извлечением и анализом текста, диаграмм, иконок и макетов из изображений.
Агентские возможности: Работает как визуальный агент, поддерживая такие задачи, как управление смартфонами и компьютерами.
Понимание видео: Обрабатывает длинные видео (более 1 часа) с точным определением событий.
Эффективный доступ: Novita AI предоставляет доступный вариант API, позволяющий избежать высоких затрат на оборудование.
Qwen2.5-VL — это новейшая флагманская модель зрения-языка в серии Qwen, представляющая собой значительный шаг вперед по сравнению с предшественником Qwen2-VL. Модель Qwen2.5-VL-72B-Instruct — это версия, настроенная на выполнение инструкций, с 72 миллиардами параметров, разработанная как более эффективная и практичная модель зрения-языка на основе ценных отзывов разработчиков.
Что такое Qwen2.5-VL-72B-Instruct?
Qwen2.5-VL-72B-Instruct — это большая модель зрения-языка (LVLM) с 72 миллиардами параметров, доработанная для задач, основанных на инструкциях. Она способна понимать и анализировать как визуальные (изображения/видео), так и текстовые входные данные для выполнения широкого круга задач. Ключевые улучшения по сравнению с Qwen2-VL:
- Улучшенное визуальное понимание: Умеет распознавать обычные объекты, анализировать текст, диаграммы, иконки, графику и макеты внутри изображений.
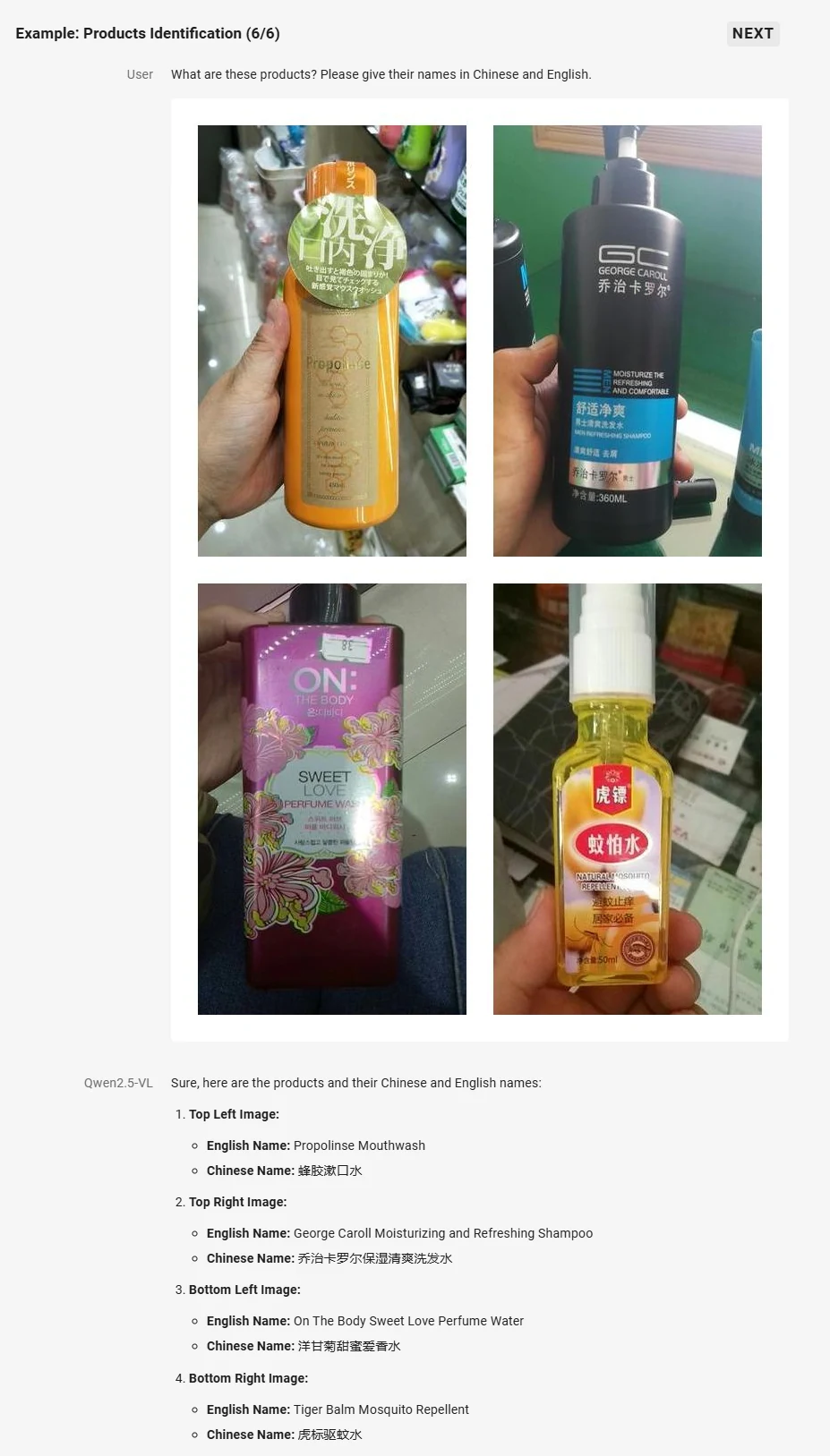
Источник: Qwen
- Агентские возможности: Действует как визуальный агент, способный рассуждать и динамически управлять инструментами для работы с компьютером и телефоном.
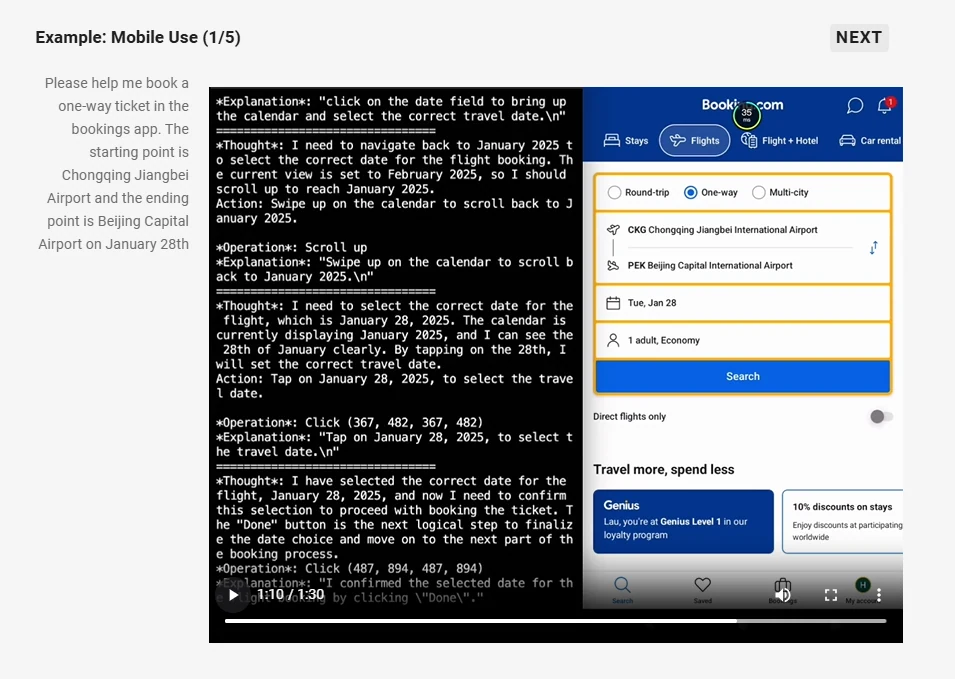
Источник: Qwen
- Улучшенное понимание видео: Может понимать видео длительностью более часа, определять релевантные видеосегменты, поддерживает динамическое обучение FPS и кодирование абсолютного времени для лучшего временного понимания.

Источник: Qwen
- Точная локализация объектов: Точно обнаруживает объекты на изображении с помощью ограничивающих рамок/точек и обеспечивает стабильный вывод JSON для координат и атрибутов.
- Генерация структурированного вывода: Поддерживает структурированный вывод для отсканированных счетов и таблиц, что полезно в финансах и коммерции.

Источник: Qwen
Бенчмарк Qwen2-VL-72B-Instruct
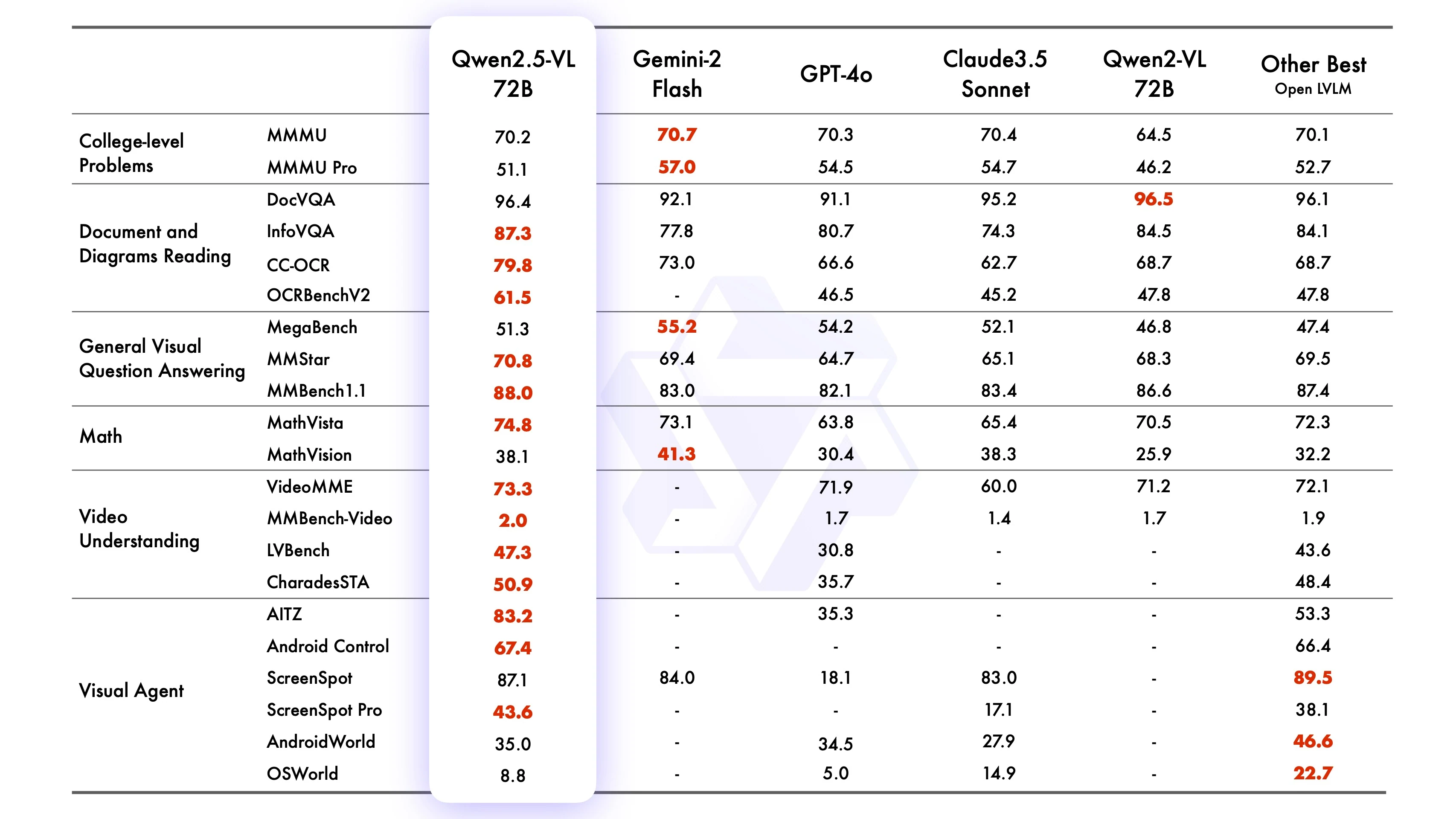
Источник: Qwen
Qwen2.5-VL-72B-Instruct демонстрирует конкурентоспособные или превосходные результаты по множеству бенчмарков, преуспевая в задачах с изображениями (например, MMMUval, MathVista_MINI, DocVQA_VAL), задачах с видео (например, VideoMME, MVBench, EgoSchema) и агентских задачах (например, ScreenSpot, Android Control, MobileMiniWob++_SR). Он часто превосходит Qwen2-VL-72B и конкурирует с ведущими моделями, такими как GPT4o, Claude3.5 Sonnet и Gemini 2.0. Кроме того, Qwen2.5-VL-7B превосходит GPT-4o-mini в нескольких задачах, а Qwen2.5-VL-3B превосходит версию Qwen2-VL на 7B.
Аппаратные требования Qwen2-VL-72B-Instruct
| Модель GPU | VRAM на GPU | Количество GPU | Общий объём VRAM | Примерная стоимость |
|---|---|---|---|---|
| Nvidia A100 (80 ГБ) | 80 ГБ | 8 GPU | 640 ГБ | Примерно $205 496 |
| Nvidia H100 (80 ГБ) | 80 ГБ | 8 GPU | 640 ГБ | Примерно $200 000 - $320 000 |
| Nvidia RTX 4090 | 24 ГБ | 24 GPU | 576 ГБ | Примерно $57 600 - $66 120 |
| Nvidia L40S | 48 ГБ | 8 GPU | 384 ГБ | Примерно $46 799,60 - $83 712,80 |
Для запуска Qwen2-VL-72B-Instruct лучшим универсальным вариантом является Nvidia A100 (80 ГБ), обеспечивающий баланс между стоимостью, объёмом VRAM и производительностью. H100 (80 ГБ) подходит для организаций, ориентированных на производительность, в то время как RTX 4090 и L40S являются жизнеспособными вариантами для ограниченного бюджета, хотя и имеют компромиссы в сложности и объёме VRAM.
Тестирование Qwen2-VL-72B-Instruct
Входные данные: Дайте запрос: «пользователь использует функцию генерации изображений», когда в видео происходит описанное содержимое? Используйте секунды для формата времени.
Выходные данные: Описанное содержимое происходит с 28-й по 50-ю секунду видео. В этом сегменте пользователь взаимодействует с функцией генерации изображений, запрашивая и получая художественную двойную сцену с изображением горы днём и ночью. Затем пользователь добавляет птицу на сгенерированное изображение, демонстрируя функциональность инструмента генерации изображений.
Как получить доступ к Qwen2-VL-72B-Instruct?
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предлагает доступное и надежное GPU-облако для создания и масштабирования.
Шаг 1: Войдите и откройте библиотеку моделей
Войдите в свою учетную запись и нажмите кнопку Библиотека моделей.

Попробуйте демо Qwen2-VL-72B-Instruct сейчас!
Шаг 2: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 3: Получите ваш API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу «Настройки», где вы можете скопировать API-ключ, как показано на изображении.

Шаг 4: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API чат-завершений для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<ВАШ API-КЛЮЧ Novita AI>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # или False
max_tokens = 2048
system_content = """Будьте полезным помощником"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Привет!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B-Instruct представляет собой значительный прогресс в моделях зрения-языка, улучшая визуальное понимание, понимание видео, агентские возможности, локализацию и генерацию структурированного вывода. Благодаря динамическому обучению разрешению и эффективному визуальному кодировщику он достигает превосходных показателей в бенчмарках по задачам с изображениями, видео и агентами.
Часто задаваемые вопросы
Как Qwen2.5-VL-instruct улучшает визуальное понимание?
Он анализирует текст (многоязычный, вертикальный), диаграммы, иконки и макеты, извлекая ключевую информацию и преобразуя документы в структурированные форматы, такие как HTML.
Каковы новые возможности Qwen2.5-VL-instruct в работе с видео?
Обрабатывает видео длительностью более 1 часа, определяет события с точностью до секунды, выполняет временную привязку, генерирует структурированные подписи и обобщает содержимое.
Какое рекомендуемое оборудование для запуска Qwen2.5-VL-instruct?
Для локального использования рекомендуется GPU с объёмом VRAM не менее 384 ГБ. Или вы можете выбрать эффективный API, например Novita AI, чтобы использовать его!
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предлагает доступное и надежное GPU-облако для создания и масштабирования.



