

Wichtige Highlights
Text-zu-Bild-Analyse: Qwen2.5-VL zeichnet sich durch die Extraktion und Analyse von Texten, Diagrammen, Symbolen und Layouts aus Bildern aus.
Agentenfähigkeiten: Fungiert als visueller Agent und unterstützt Aufgaben wie die Steuerung von Smartphones und Computern.
Videoverständnis: Verarbeitet lange Videos (1+ Stunde) mit präziser Ereignisortung.
Effizienter Zugriff: Novita AI bietet eine erschwingliche API-Option, um hohe Hardwarekosten zu vermeiden.
Qwen2.5-VL ist das neueste Flaggschiff-Modell für Vision und Sprache in der Qwen-Serie und stellt einen bedeutenden Fortschritt gegenüber seinem Vorgänger Qwen2-VL dar. Das Qwen2.5-VL-72B-Instruct-Modell ist eine instruktionsoptimierte Version mit 72 Milliarden Parametern, die auf der Grundlage wertvollen Feedbacks von Entwicklern als effektiveres und praktischeres Vision-Language-Modell konzipiert wurde.
Was ist Qwen2.5-VL-72B-Instruct?
Qwen2.5-VL-72B-Instruct ist ein großes Vision-Language-Modell (LVLM) mit 72 Milliarden Parametern, das für instruktionsbasierte Aufgaben feinabgestimmt wurde. Es ist in der Lage, sowohl visuelle (Bilder/Videos) als auch textuelle Eingaben zu verstehen und zu analysieren, um eine breite Palette von Aufgaben auszuführen. Wichtige Verbesserungen gegenüber Qwen2-VL umfassen:
- Verbessertes visuelles Verständnis: Kann alltägliche Objekte erkennen, Texte, Diagramme, Symbole, Grafiken und Layouts in Bildern analysieren.
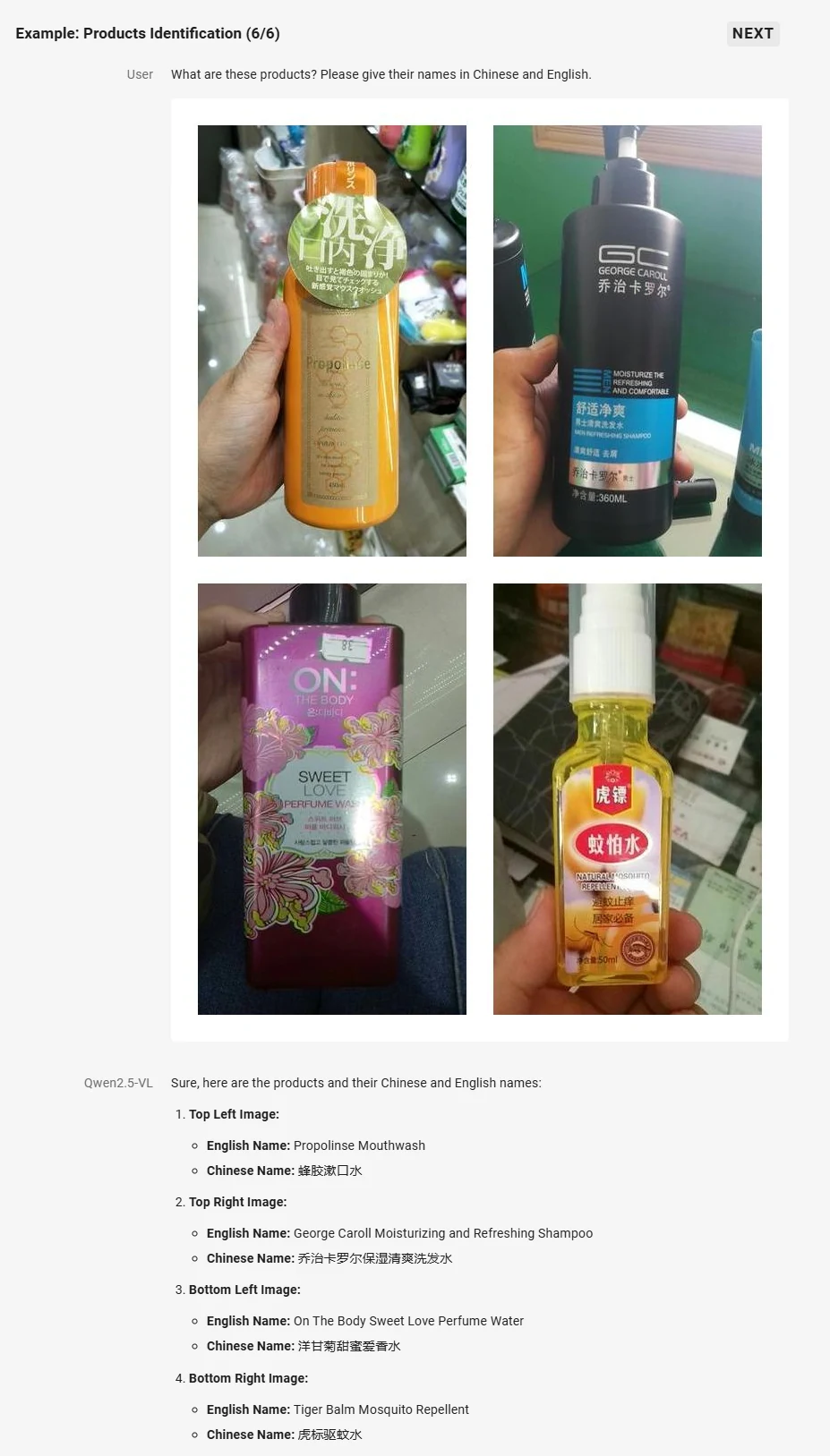
Von Qwen
- Agentenfähigkeiten: Fungiert als visueller Agent, der in der Lage ist, zu argumentieren und Werkzeuge dynamisch für die Computer- und Telefonnutzung zu steuern.
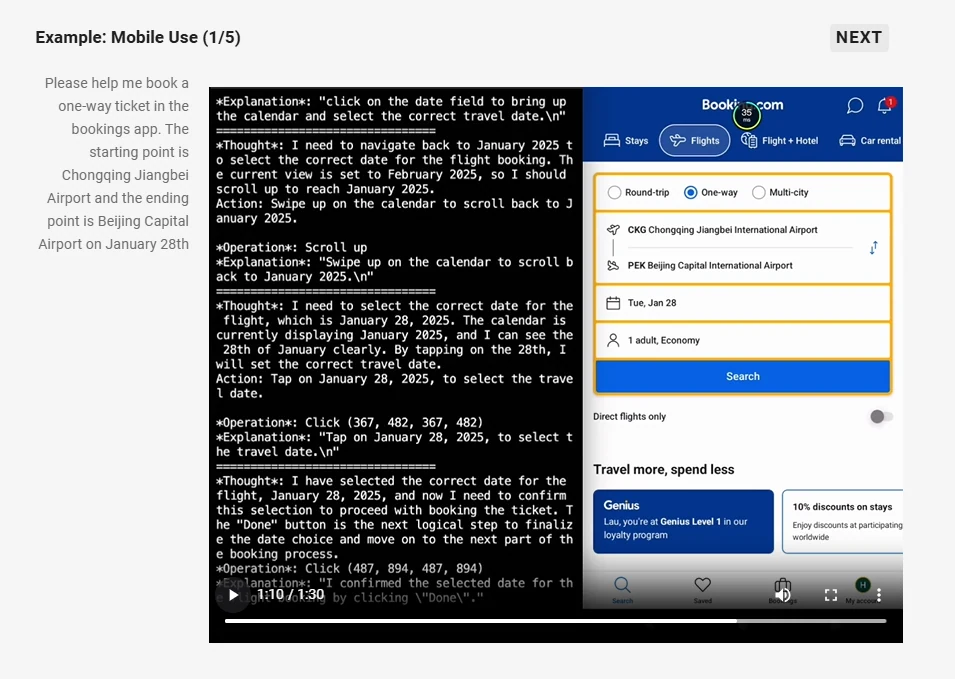
Von Qwen
- Verbessertes Videoverständnis: Kann Videos von über einer Stunde Länge verstehen, relevante Videosegmente lokalisieren und unterstützt dynamisches FPS-Training und absolute Zeitkodierung für ein besseres zeitliches Verständnis.

Von Qwen
- Präzise Objektlokalisierung: Erkennt Objekte in einem Bild mithilfe von Begrenzungsrahmen/Punkten genau und liefert stabile JSON-Ausgaben für Koordinaten und Attribute.
- Strukturierte Ausgabeerzeugung: Unterstützt strukturierte Ausgaben für gescannte Rechnungen und Tabellen, was Anwendungen in den Bereichen Finanzen und Handel zugutekommt.

Von Qwen
Qwen2-VL-72B-Instruct Benchmark
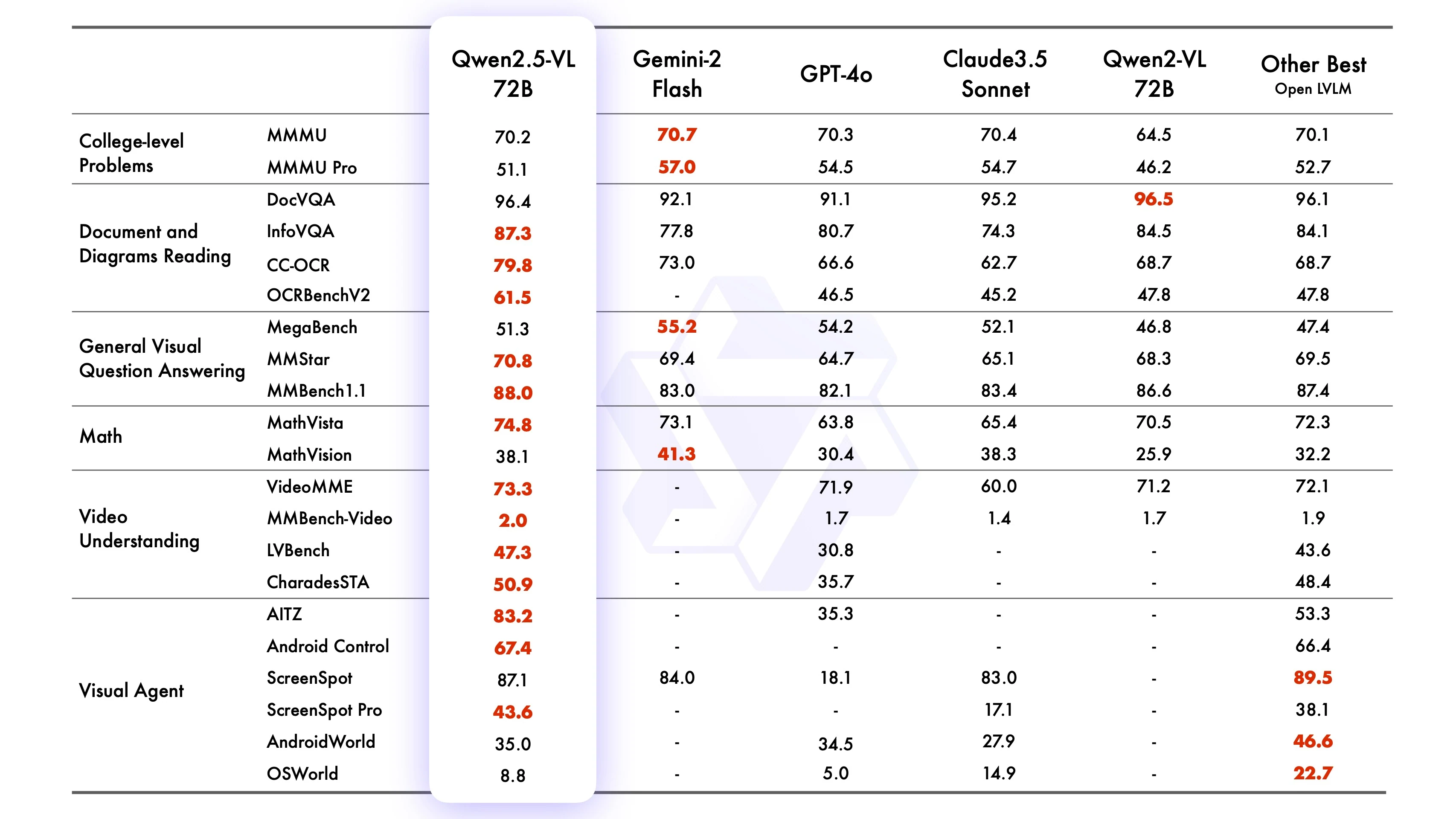
Von Qwen
Qwen2.5-VL-72B-Instruct hat in zahlreichen Benchmarks wettbewerbsfähige oder überlegene Leistungen gezeigt, insbesondere bei Bildaufgaben (z. B. MMMUval, MathVista_MINI, DocVQA_VAL), Videoaufgaben (z. B. VideoMME, MVBench, EgoSchema) und agentenbasierten Aufgaben (z. B. ScreenSpot, Android Control, MobileMiniWob++_SR). Es übertrifft oft Qwen2-VL-72B und konkurriert mit führenden Modellen wie GPT4o, Claude3.5 Sonnet und Gemini 2.0. Darüber hinaus übertrifft Qwen2.5-VL-7B GPT-4o-mini in mehreren Aufgaben, während Qwen2.5-VL-3B die 7B-Version von Qwen2-VL übertrifft.
Hardware-Anforderungen für Qwen2-VL-72B-Instruct
| GPU-Modell | VRAM pro GPU | Verwendete GPUs | Gesamt-VRAM | Geschätzte Kosten |
|---|---|---|---|---|
| Nvidia A100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Etwa 205.496 $ |
| Nvidia H100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Etwa 200.000 $ – 320.000 $ |
| Nvidia RTX 4090 | 24 GB | 24 GPUs | 576 GB | Etwa 57.600 $ – 66.120 $ |
| Nvidia L40S | 48 GB | 8 GPUs | 384 GB | Etwa 46.799,60 $ – 83.712,80 $ |
Für den Betrieb von Qwen2-VL-72B-Instruct ist die Nvidia A100 (80 GB) die beste Allround-Option, die Kosten, VRAM und Leistung in Einklang bringt. Die H100 (80 GB) eignet sich für Organisationen, die Leistung priorisieren, während die RTX 4090 und L40S für budgetbewusste Setups geeignet sind, jedoch mit Abstrichen bei Komplexität und VRAM verbunden sind.
Qwen2-VL-72B-Instruct Test
Eingabe: Geben Sie die Abfrage ein: „Der Benutzer nutzt die Bildgenerierungsfunktion“. Wann tritt der beschriebene Inhalt im Video auf? Verwenden Sie Sekunden als Zeitformat.
Ausgabe: Der beschriebene Inhalt tritt im Video von Sekunde 28 bis Sekunde 50 auf. In diesem Abschnitt interagiert der Benutzer mit der Bildgenerierungsfunktion, fordert ein künstlerisches Doppelszenenbild eines Berges bei Tag und Nacht an und erhält es. Der Benutzer fügt dem generierten Bild dann einen Vogel hinzu, was die Funktionalität des Bildgenerierungstools demonstriert.
Wie erhalte ich Zugriff auf Qwen2-VL-72B-Instruct?
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Entwicklung und Skalierung bereitstellt.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Jetzt die Qwen2-VL-72B-Instruct Demo testen!
Schritt 2: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 3: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 4: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B-Instruct stellt einen bedeutenden Fortschritt bei Vision-Language-Modellen dar und verbessert das visuelle Verständnis, das Videoverständnis, die Agentenfähigkeiten, die Lokalisierung und die strukturierte Ausgabeerzeugung. Mit dynamischem Auflösungstraining und einem effizienten visuellen Encoder erzielt es eine überragende Benchmark-Leistung bei Bild-, Video- und Agentenaufgaben.
Häufig gestellte Fragen
Wie verbessert Qwen2.5-VL-Instruct das visuelle Verständnis?
Es analysiert Texte (mehrsprachig, vertikal), Diagramme, Symbole und Layouts, extrahiert Schlüsselinformationen und wandelt Dokumente in strukturierte Formate wie HTML um.
Welche neuen Videofähigkeiten bietet Qwen2.5-VL-Instruct?
Es verarbeitet Videos über 1 Stunde, lokalisiert Ereignisse sekundengenau, führt zeitliche Verankerung durch, generiert strukturierte Bildunterschriften und fasst Inhalte zusammen.
Welche Hardware wird für den Betrieb von Qwen2.5-VL-Instruct empfohlen?
Für die lokale Nutzung wird eine GPU mit mindestens 384 GB VRAM empfohlen. Oder Sie können eine effektive API wie Novita AI nutzen!
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Entwicklung und Skalierung bereitstellt.



