

النقاط الرئيسية
تحليل النص من الصور: يتفوق Qwen2.5-VL في استخراج وتحليل النصوص والرسوم البيانية والأيقونات والتخطيطات من الصور.
قدرات وكيل: يعمل كعامل بصري، ويدعم مهام مثل إدارة الهواتف الذكية وأجهزة الكمبيوتر.
فهم الفيديو: يعالج مقاطع فيديو طويلة (أكثر من ساعة) مع تحديد دقيق للأحداث.
وصول فعال: توفر Novita AI خيار API اقتصادي لتجنب تكاليف الأجهزة المرتفعة.
Qwen2.5-VL هو أحدث نموذج رائد في سلسلة Qwen للرؤية واللغة، ويمثل قفزة كبيرة إلى الأمام مقارنة بسابقه Qwen2-VL. نموذج Qwen2.5-VL-72B-Instruct هو نسخة معدلة بالتعليمات تحتوي على 72 مليار معامل، ومصممة لتكون نموذج رؤية-لغة أكثر فعالية وعملية بناءً على ملاحظات قيمة من المطورين.
ما هو Qwen2.5-VL-72B-Instruct؟
Qwen2.5-VL-72B-Instruct هو نموذج رؤية-لغة كبير (LVLM) يحتوي على 72 مليار معامل، ومضبوط بدقة للمهام القائمة على التعليمات. وهو قادر على فهم وتحليل المدخلات البصرية (صور/فيديو) والنصية لأداء مجموعة واسعة من المهام. تشمل التحسينات الرئيسية مقارنة بـ Qwen2-VL:
- فهم بصري محسّن: بارع في التعرف على الأشياء الشائعة، وتحليل النصوص والرسوم البيانية والأيقونات والرسومات والتخطيطات داخل الصور.
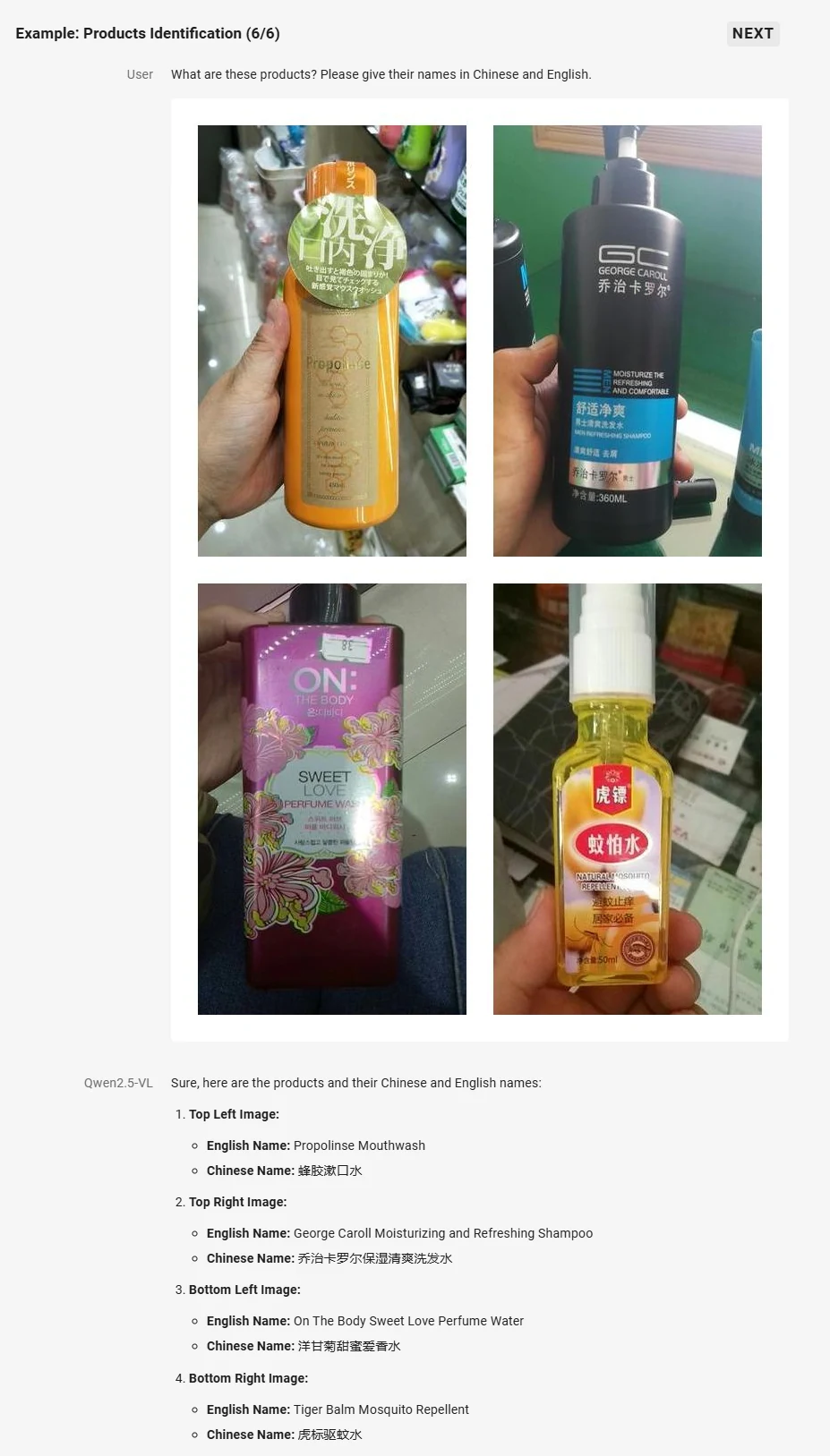
من Qwen
- قدرات وكيل: يعمل كعامل بصري قادر على التفكير وتوجيه الأدوات ديناميكياً لاستخدام الكمبيوتر والهاتف.
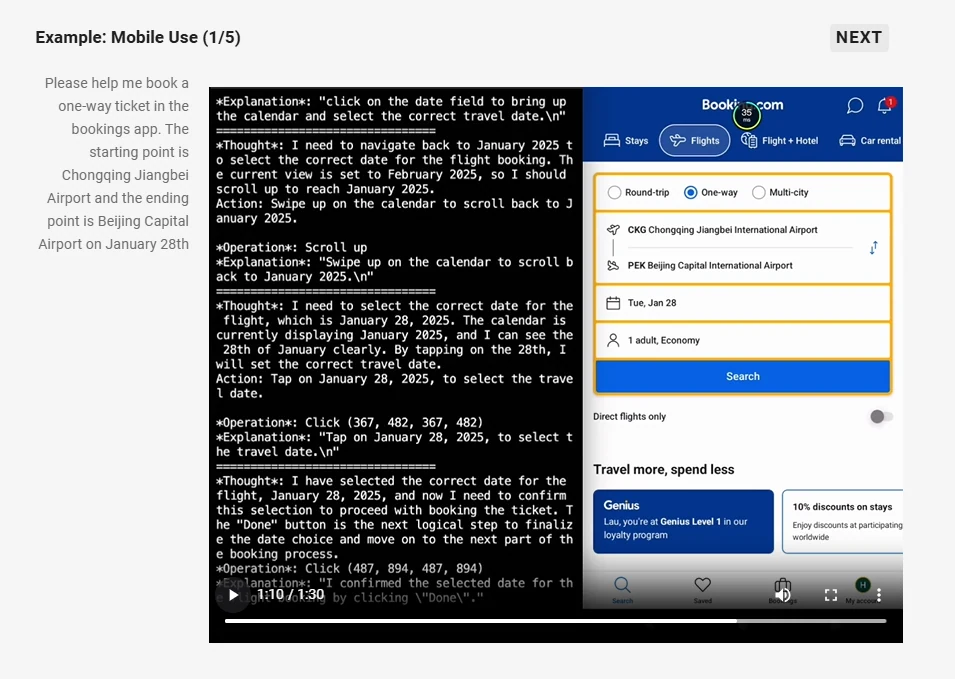
من Qwen
- فهم فيديو محسّن: يمكنه فهم مقاطع فيديو أطول من ساعة، وتحديد أجزاء الفيديو ذات الصلة، ويدعم التدريب الديناميكي لمعدل الإطارات و تشفير الوقت المطلق لفهم زمني أفضل.

من Qwen
- تحديد دقيق للأشياء: يكتشف بدقة الأشياء في الصورة باستخدام مربعات/نقاط حدود ويوفر مخرجات JSON مستقرة للإحداثيات والسمات.
- توليد مخرجات منظمة: يدعم المخرجات المنظمة للفواتير والجداول الممسوحة ضوئياً، مما يفيد تطبيقات المالية والتجارة.

من Qwen
معايير Qwen2-VL-72B-Instruct
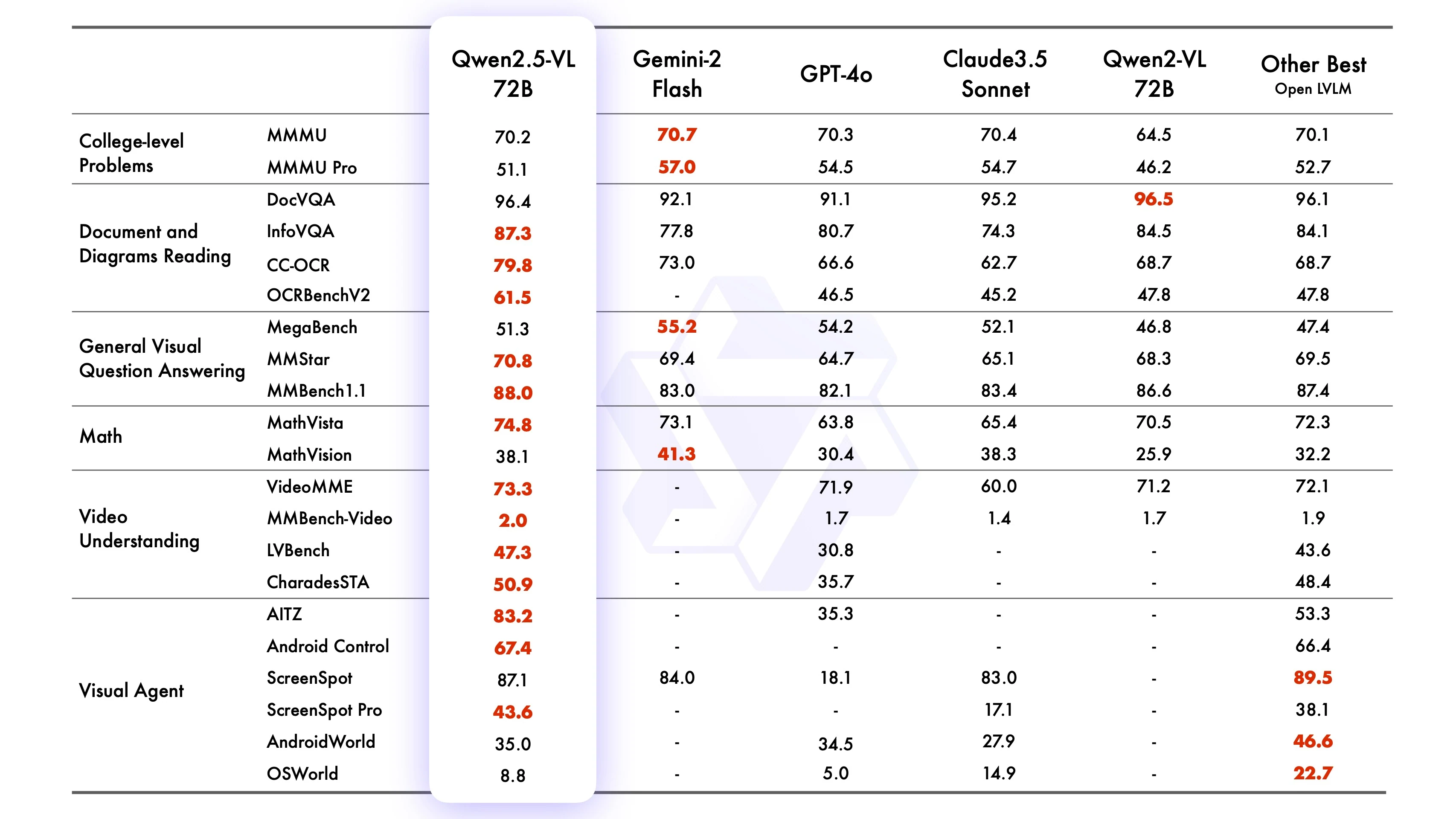
من Qwen
أظهر Qwen2.5-VL-72B-Instruct أداءً تنافسياً أو متفوقاً عبر العديد من المعايير، متفوقاً في مهام الصور (مثل MMMUval, MathVista_MINI, DocVQA_VAL)، ومهام الفيديو (مثل VideoMME, MVBench, EgoSchema)، والمهام القائمة على الوكيل (مثل ScreenSpot, Android Control, MobileMiniWob++_SR). غالباً ما يتفوق على Qwen2-VL-72B وينافس النماذج الرائدة مثل GPT4o وClaude3.5 Sonnet وGemini 2.0. بالإضافة إلى ذلك، يتفوق Qwen2.5-VL-7B على GPT-4o-mini في عدة مهام، بينما يتفوق Qwen2.5-VL-3B على إصدار 7B من Qwen2-VL.
متطلبات الأجهزة لـ Qwen2-VL-72B-Instruct
| طراز GPU | VRAM لكل GPU | عدد GPUs المستخدمة | إجمالي VRAM | التكلفة التقديرية |
|---|---|---|---|---|
| Nvidia A100 (80 GB) | 80 GB | 8 GPUs | 640 GB | حوالي $205,496 |
| Nvidia H100 (80 GB) | 80 GB | 8 GPUs | 640 GB | حوالي $200,000 - $320,000 |
| Nvidia RTX 4090 | 24 GB | 24 GPUs | 576 GB | حوالي $57,600 - $66,120 |
| Nvidia L40S | 48 GB | 8 GPUs | 384 GB | حوالي $46,799.60 - $83,712.80 |
لتشغيل Qwen2-VL-72B-Instruct، فإن Nvidia A100 (80 GB) هو الخيار الأفضل الشامل، موازناً بين التكلفة وVRAM والأداء. H100 (80 GB) مناسب للمؤسسات التي تعطي الأولوية للأداء، بينما RTX 4090 و L40S مناسبان للإعدادات المحدودة الميزانية، رغم أنها تأتي مع مقايضات في التعقيد وVRAM.
اختبار Qwen2-VL-72B-Instruct
المدخل: أعط الاستعلام: “المستخدم يختبر ميزة توليد الصور”، متى يحدث المحتوى الموصوف في الفيديو؟ استخدم الثواني كتنسيق للوقت.
المخرج: يحدث المحتوى الموصوف من الثانية 28 إلى الثانية 50 في الفيديو. خلال هذا المقطع، يتفاعل المستخدم مع ميزة توليد الصور، ويطلب ويستلم لوحة فنية مزدوجة المشهد لجبل خلال النهار والليل. ثم يضيف المستخدم طائراً إلى الصورة المولدة، مما يوضح وظيفة أداة توليد الصور.
كيفية الوصول إلى Qwen2-VL-72B-Instruct؟
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج AI باستخدام API بسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب نموذج Qwen2-VL-72B-Instruct الآن!
الخطوة 2: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 3: احصل على مفتاح API الخاص بك
لمصادقة API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 4: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغتك البرمجية.

بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API chat completions لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يمثل Qwen2.5-VL-72B-Instruct تقدماً كبيراً في نماذج الرؤية واللغة، مما يعزز الفهم البصري، وفهم الفيديو، وقدرات الوكيل، والتوطين، وتوليد المخرجات المنظمة. مع التدريب الديناميكي للدقة ومشفّر بصري فعال، يحقق أداءً فائقاً في المعايير عبر مهام الصور والفيديو والوكيل.
الأسئلة الشائعة
كيف يحسّن Qwen2.5-VL-instruct الفهم البصري؟
يحلل النصوص (متعددة اللغات، عمودية)، والرسوم البيانية، والأيقونات، والتخطيطات مع استخراج المعلومات الرئيسية وتحويل المستندات إلى تنسيقات منظمة مثل HTML.
ما هي قدرات الفيديو الجديدة لـ Qwen2.5-VL-instruct؟
يعالج مقاطع فيديو أطول من ساعة، ويحدد الأحداث بدقة الثانية، ويقوم بالتثبيت الزمني، ويولد تسميات توضيحية منظمة، ويلخص المحتوى.
ما هي الأجهزة الموصى بها لتشغيل Qwen2.5-VL-instruct؟
للاستخدام المحلي، يوصى باستخدام GPU بسعة VRAM لا تقل عن 384GB. أو يمكنك اختيار API فعال مثل Novita AI لاستخدامه!
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج AI باستخدام API بسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



