

主な特長
テキストから画像への分析:Qwen2.5-VLは、画像内のテキスト、グラフ、アイコン、レイアウトの抽出と分析に優れています。
エージェント機能:視覚エージェントとして機能し、スマートフォンやコンピュータの操作などのタスクをサポートします。
動画理解:長時間(1時間以上)の動画を処理し、正確なイベント位置を特定します。
効率的なアクセス:Novita AI は、高額なハードウェアコストを回避できる手頃なAPIオプションを提供します。
Qwen2.5-VLは、Qwenシリーズの最新フラッグシップ視覚言語モデルであり、前世代のQwen2-VLから大幅に進化しています。Qwen2.5-VL-72B-Instruct モデルは、開発者からの有益なフィードバックに基づいて設計された、より効果的で実用的な視覚言語モデルであり、720億のパラメータを持つ指示調整版です。
Qwen2.5-VL-72B-Instructとは?
Qwen2.5-VL-72B-Instructは、大規模視覚言語モデル(LVLM) であり、720億のパラメータを持ち、指示ベースのタスク向けに微調整されています。視覚(画像/動画)とテキストの両方の入力を理解・分析し、幅広いタスクを実行できます。Qwen2-VLからの主な強化点は次のとおりです。
- 強化された視覚理解:画像内の一般的なオブジェクトの認識、テキスト、グラフ、アイコン、図形、レイアウトの分析に長けています。
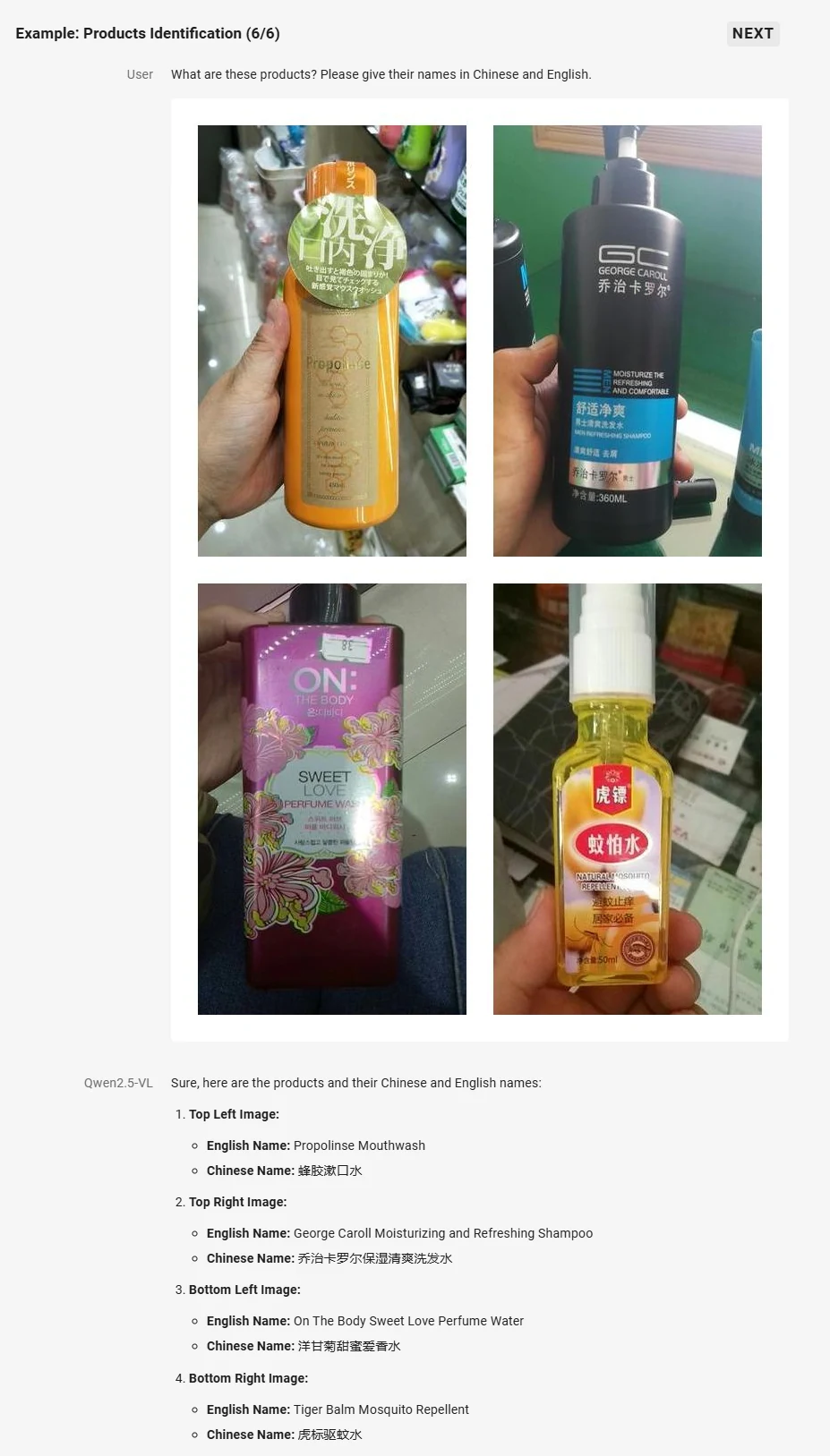
Qwen より
- エージェント機能:推論とツールの動的指示が可能な視覚エージェントとして機能し、コンピュータやスマートフォンの操作を行います。
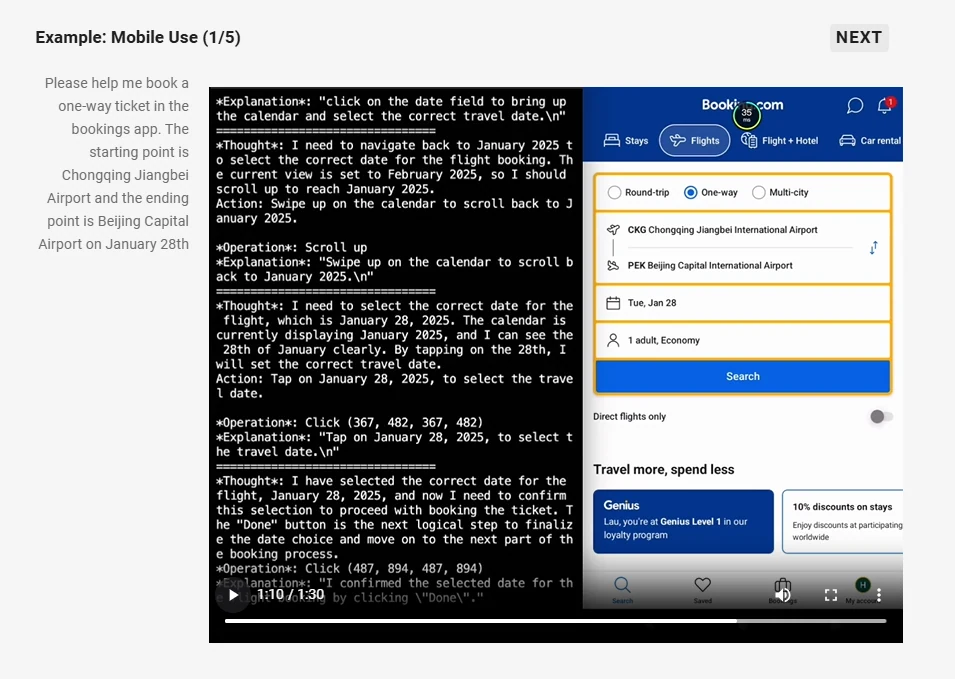
Qwen より
- 改善された動画理解 :1時間以上の動画を理解し、関連する動画セグメントを特定可能。また、 動的FPSトレーニング と 絶対時間エンコーディングをサポートし、時間的把握が向上しています。

Qwen より
- 正確なオブジェクト位置特定:バウンディングボックスやポイントを用いて画像内のオブジェクトを正確に検出し、座標や属性の安定したJSON出力を提供します。
- 構造化出力生成:スキャンされた請求書や表に対して構造化出力をサポートし、金融やコマースのアプリケーションに役立ちます。

Qwen より
Qwen2-VL-72B-Instruct ベンチマーク
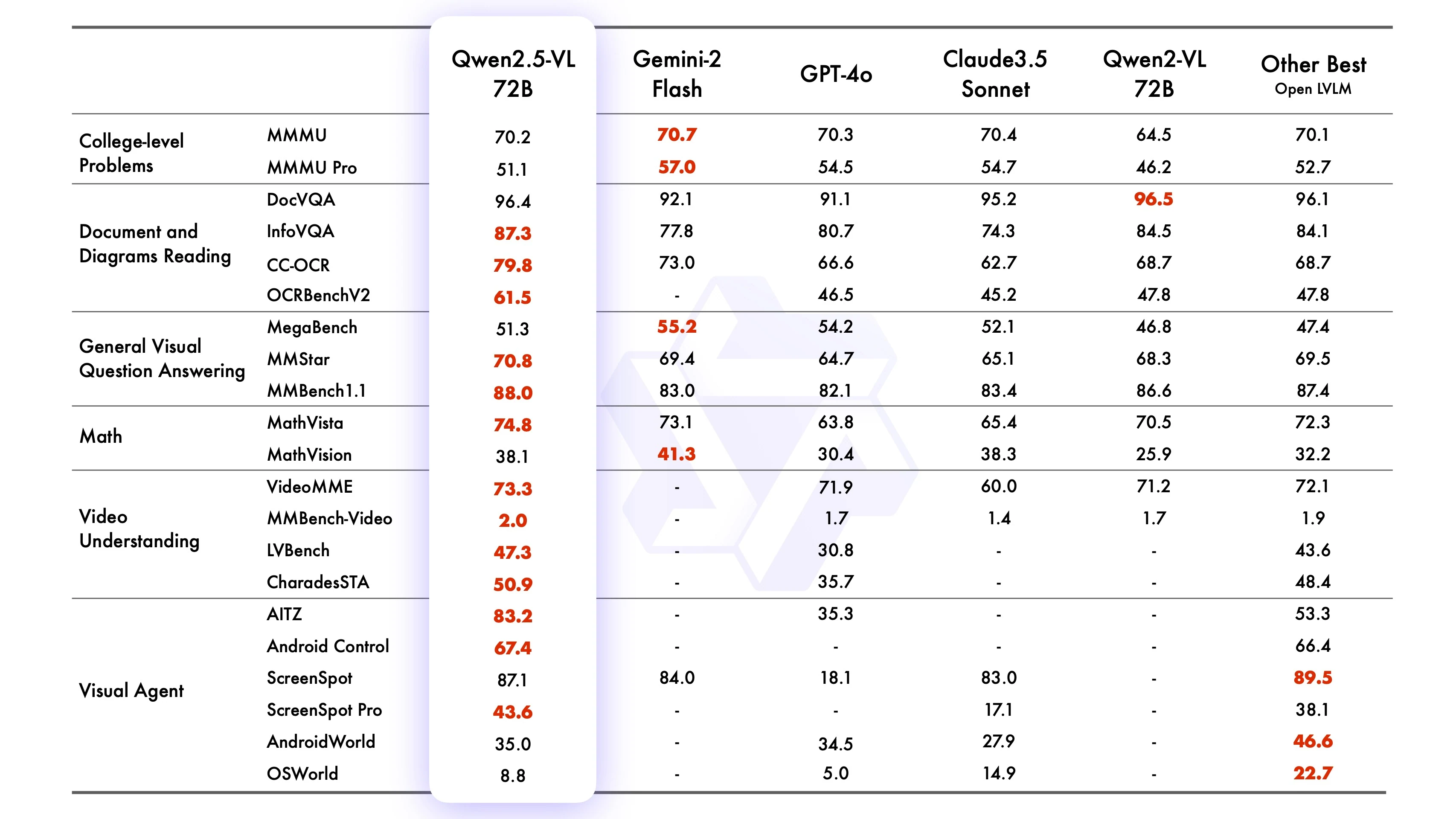
Qwen より
Qwen2.5-VL-72B-Instructは、数多くのベンチマークで競争力のある、または優れたパフォーマンスを示しています。画像タスク(MMMUval、MathVista_MINI、DocVQA_VALなど)、動画タスク(VideoMME、MVBench、EgoSchemaなど)、エージェントベースのタスク(ScreenSpot、Android Control、MobileMiniWob++_SRなど)で優れた結果を出しています。Qwen2-VL-72Bを凌駕することが多く、GPT4o、Claude3.5 Sonnet、Gemini 2.0といった主要モデルに匹敵します。さらに、Qwen2.5-VL-7BはいくつかのタスクでGPT-4o-miniを上回り、Qwen2.5-VL-3BはQwen2-VLの7Bバージョンを凌駕しています。
Qwen2-VL-72B-Instruct ハードウェア要件
| **GPUモデル ** | GPUあたりのVRAM | ** 使用GPU数 ** | ** 合計VRAM** | ** 推定コスト** |
|---|---|---|---|---|
| Nvidia A100 (80 GB) | 80 GB | 8 GPUs | 640 GB | 約 $205,496 |
| Nvidia H100 (80 GB) | 80 GB | 8 GPUs | 640 GB | 約 $200,000 - $320,000 |
| Nvidia RTX 4090 | 24 GB | 24 GPUs | 576 GB | 約 $57,600 - $66,120 |
| Nvidia L40S | 48 GB | 8 GPUs | 384 GB | 約 $46,799.60 - $83,712.80 |
Qwen2-VL-72B-Instruct を実行するには、Nvidia A100 (80 GB) がコスト、VRAM、パフォーマンスのバランスが最も優れたオールラウンドな選択肢です。H100 (80 GB) はパフォーマンスを重視する組織に適しており、RTX 4090 と L40S は予算重視の環境でも利用可能ですが、複雑さとVRAMのトレードオフがあります。
Qwen2-VL-72B-Instruct テスト
入力: クエリ: 「ユーザーが画像生成機能を体験している」という記述は動画内のいつ発生しますか? 時間は秒単位で答えてください。
出力: 記述された内容は動画の28秒から50秒の間に発生します。このセグメントでは、ユーザーが画像生成機能とやり取りし、昼と夜の山の芸術的な二重シーン絵画をリクエストして受け取ります。その後、ユーザーは生成された画像に鳥を追加し、画像生成ツールの機能を示しています。
Qwen2-VL-72B-Instruct へのアクセス方法
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、また、手頃で信頼性の高いGPUクラウドを構築とスケーリングのために提供しています。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

今すぐQwen2-VL-72B-Instructデモをお試しください!
ステップ2:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ3:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ4:APIのインストール
使用するプログラミング言語に適したパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B-Instructは、視覚言語モデルにおける大きな進歩を表しており、視覚理解、動画理解、エージェント機能、位置特定、構造化出力生成が強化されています。動的解像度トレーニングと効率的なビジュアルエンコーダにより、画像、動画、エージェントタスク全体で優れたベンチマークパフォーマンスを達成しています。
よくある質問
Qwen2.5-VL-instruct は視覚理解をどのように改善しますか?
テキスト(多言語、縦書き)、グラフ、アイコン、レイアウトを分析し、主要情報を抽出してドキュメントをHTMLのような構造化形式に変換します。
Qwen2.5-VL-instruct の新しい動画機能は何ですか?
1時間以上の動画を処理し、イベントを秒単位で特定し、時間的グラウンディングを実行し、構造化キャプションを生成し、コンテンツを要約します。
Qwen2.5-VL-instruct を実行するための推奨ハードウェアは?
ローカルで使用する場合は、少なくとも384GBのVRAMを備えたGPU が推奨されます。または、Novita AI のような効果的なAPIを選ぶこともできます!
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築とスケーリングのために提供しています。



