

Puntos clave
Análisis de texto a imagen: Qwen2.5-VL sobresale en la extracción y análisis de texto, gráficos, iconos y diseños desde imágenes.
Capacidades de agente: Actúa como un agente visual, admitiendo tareas como la gestión de teléfonos inteligentes y ordenadores.
Comprensión de video: Procesa videos largos (más de 1 hora) con una localización precisa de eventos.
Acceso eficiente: Novita AI ofrece una opción de API asequible para evitar los altos costos de hardware.
Qwen2.5-VL es el último modelo emblemático de visión-lenguaje de la serie Qwen, que representa un avance significativo respecto a su predecesor, Qwen2-VL. El modelo Qwen2.5-VL-72B-Instruct es una versión ajustada por instrucciones con 72 mil millones de parámetros, diseñado para ser un modelo de visión-lenguaje más eficaz y práctico basado en valiosos comentarios de los desarrolladores.
¿Qué es Qwen2.5-VL-72B-Instruct?
Qwen2.5-VL-72B-Instruct es un modelo grande de visión-lenguaje (LVLM) con 72 mil millones de parámetros, ajustado para tareas basadas en instrucciones. Es capaz de comprender y analizar entradas tanto visuales (imágenes/videos) como textuales para realizar una amplia variedad de tareas. Las mejoras clave respecto a Qwen2-VL incluyen:
- Comprensión visual mejorada: Experto en reconocer objetos comunes, analizar texto, gráficos, iconos, imágenes y diseños dentro de las imágenes.
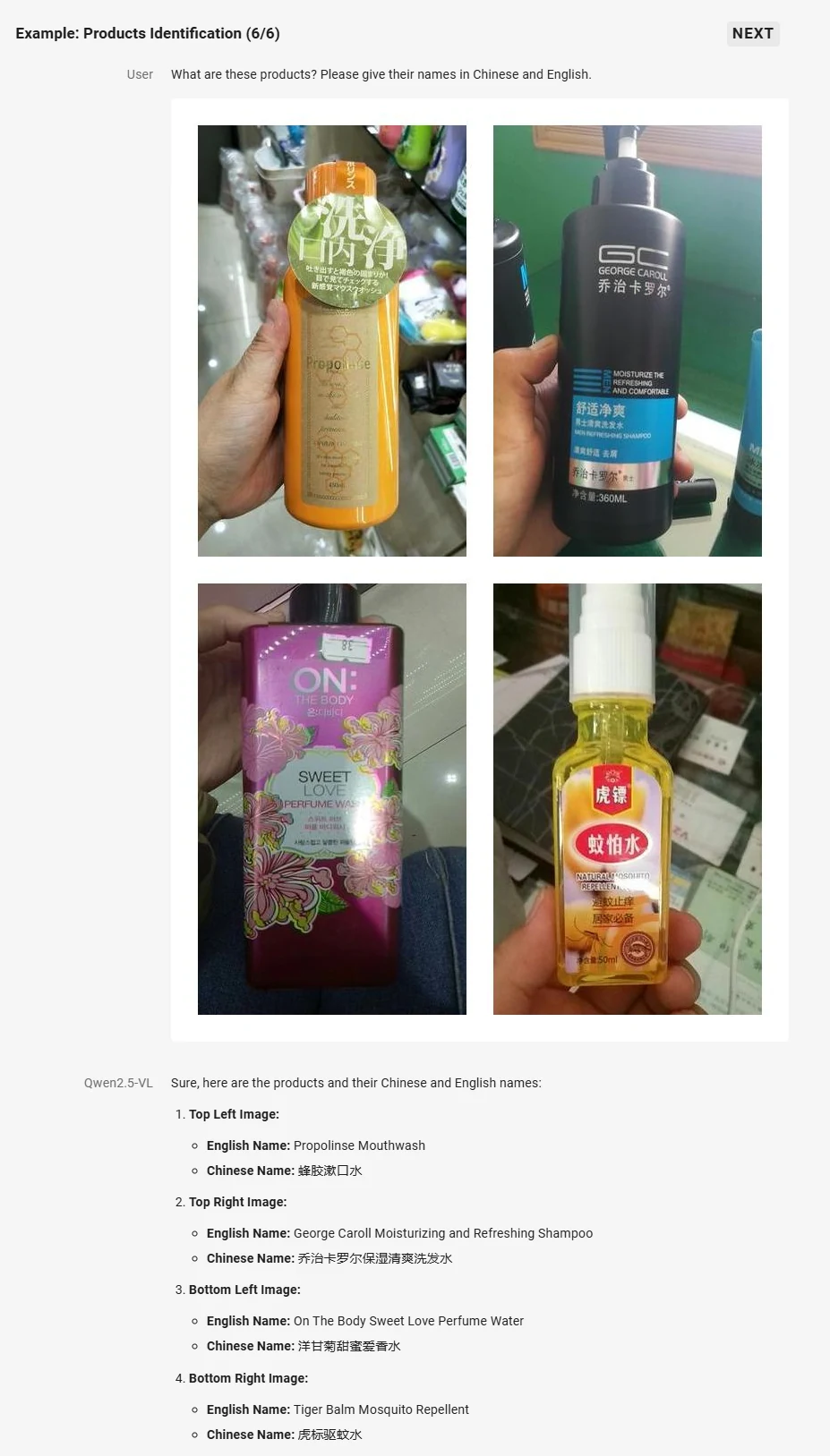
Fuente: Qwen
- Capacidades de agente: Actúa como un agente visual capaz de razonar y dirigir dinámicamente herramientas para el uso de ordenadores y teléfonos.
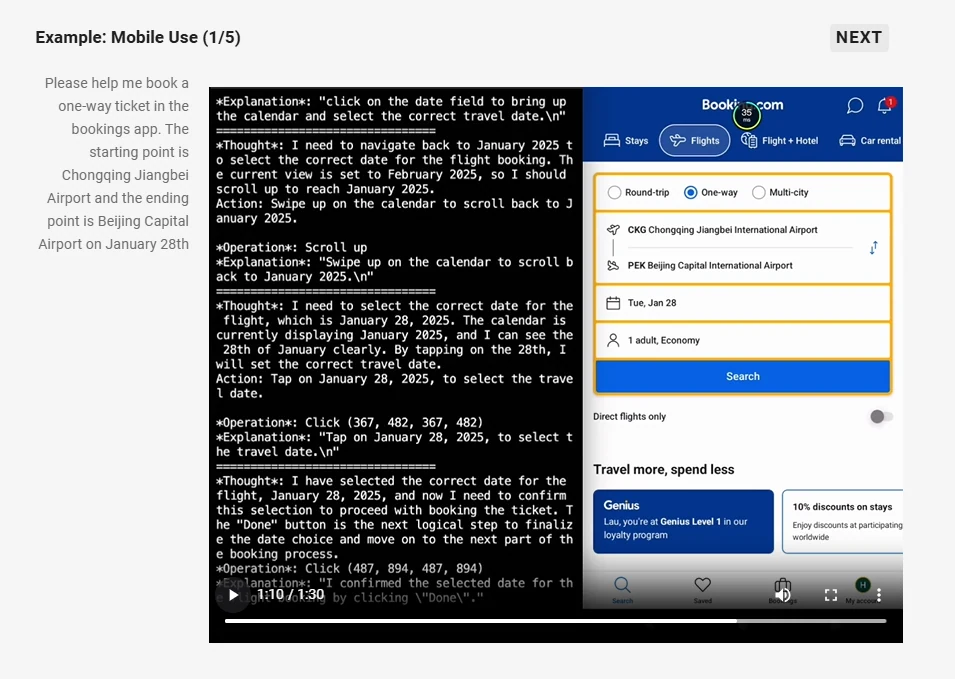
Fuente: Qwen
- Comprensión de video mejorada: Puede comprender videos de más de una hora, localizar segmentos relevantes del video y admite entrenamiento de FPS dinámico y codificación de tiempo absoluto para una mejor comprensión temporal.

Fuente: Qwen
- Localización precisa de objetos: Detecta con precisión objetos en una imagen usando cuadros delimitadores/puntos y proporciona salidas JSON estables para coordenadas y atributos.
- Generación de salidas estructuradas: Admite salidas estructuradas para facturas escaneadas y tablas, beneficiando aplicaciones en finanzas y comercio.

Fuente: Qwen
Puntos de referencia de Qwen2-VL-72B-Instruct
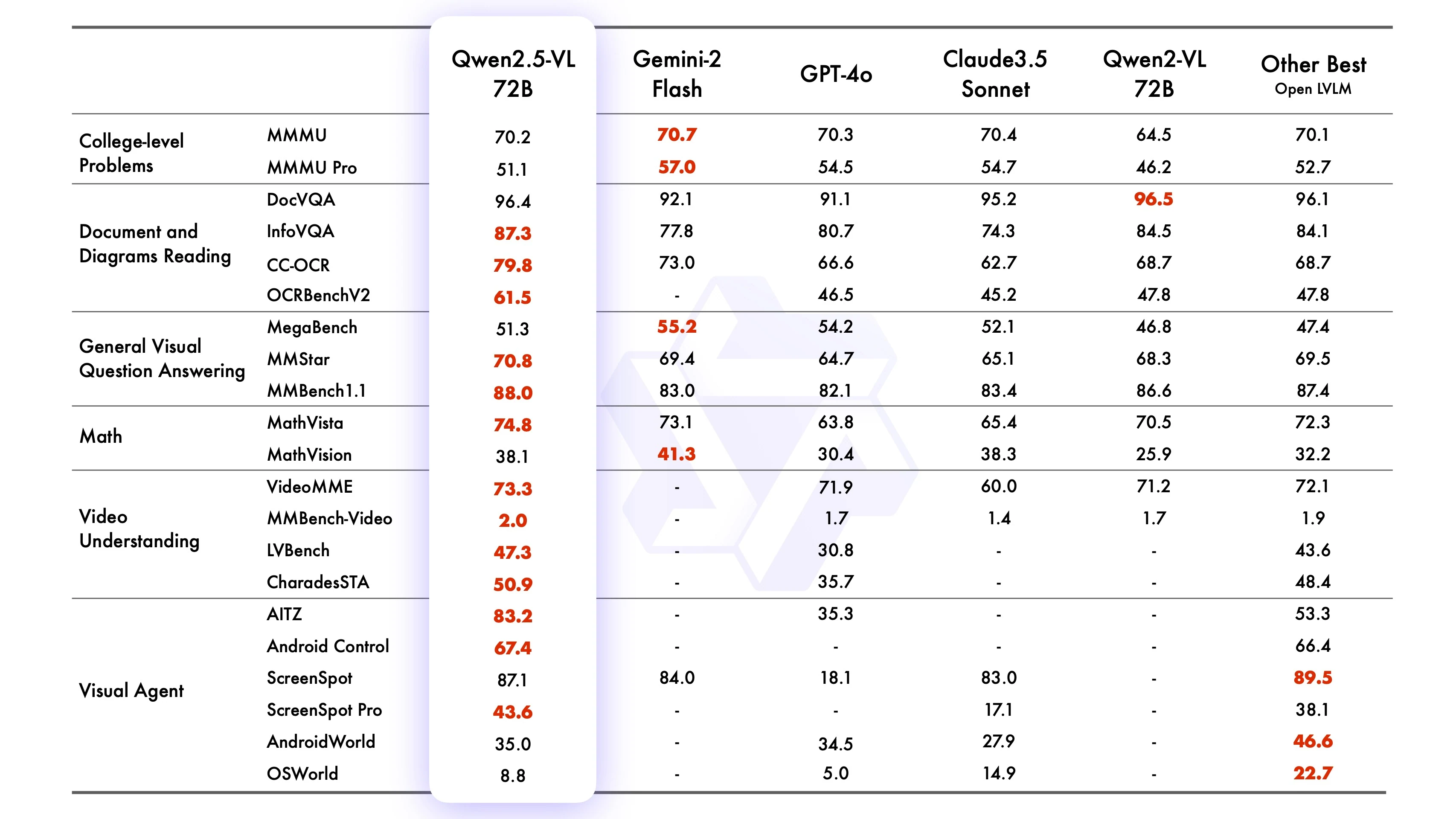
Fuente: Qwen
Qwen2.5-VL-72B-Instruct ha demostrado un rendimiento competitivo o superior en numerosos puntos de referencia, sobresaliendo en tareas de imagen (p. ej., MMMUval, MathVista_MINI, DocVQA_VAL), tareas de video (p. ej., VideoMME, MVBench, EgoSchema) y tareas basadas en agentes (p. ej., ScreenSpot, Android Control, MobileMiniWob++_SR). A menudo supera a Qwen2-VL-72B y rivaliza con modelos líderes como GPT4o, Claude3.5 Sonnet y Gemini 2.0. Además, Qwen2.5-VL-7B supera a GPT-4o-mini en varias tareas, mientras que Qwen2.5-VL-3B supera a la versión de 7B de Qwen2-VL.
Requisitos de hardware de Qwen2-VL-72B-Instruct
| Modelo de GPU | VRAM por GPU | GPUs utilizadas | VRAM total | Costo estimado |
|---|---|---|---|---|
| Nvidia A100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Aproximadamente $205,496 |
| Nvidia H100 (80 GB) | 80 GB | 8 GPUs | 640 GB | Aproximadamente $200,000 - $320,000 |
| Nvidia RTX 4090 | 24 GB | 24 GPUs | 576 GB | Aproximadamente $57,600 - $66,120 |
| Nvidia L40S | 48 GB | 8 GPUs | 384 GB | Aproximadamente $46,799.60 - $83,712.80 |
Para ejecutar Qwen2-VL-72B-Instruct, la Nvidia A100 (80 GB) es la mejor opción general, equilibrando costo, VRAM y rendimiento. La H100 (80 GB) es adecuada para organizaciones que priorizan el rendimiento, mientras que la RTX 4090 y la L40S son viables para configuraciones con presupuesto ajustado, aunque conllevan concesiones en complejidad y VRAM.
Prueba de Qwen2-VL-72B-Instruct
Entrada: Proporcione la consulta: “el usuario está experimentando la función de generación de imágenes”, ¿cuándo ocurre el contenido descrito en el video? Usa segundos para el formato de tiempo.
Salida: El contenido descrito ocurre desde los 28 segundos hasta los 50 segundos en el video. Durante este segmento, el usuario interactúa con la función de generación de imágenes, solicitando y recibiendo una pintura artística de doble escena de una montaña durante el día y la noche. Luego, el usuario agrega un pájaro a la imagen generada, lo que demuestra la funcionalidad de la herramienta de generación de imágenes.
¿Cómo acceder a Qwen2-VL-72B-Instruct?
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.
Paso 1: Iniciar sesión y acceder a la biblioteca de modelos
Inicie sesión en su cuenta y haga clic en el botón Biblioteca de modelos.

¡Prueba la demo de Qwen2-VL-72B-Instruct ahora!
Paso 2: Comience su prueba gratuita
Comience su prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 3: Obtenga su clave de API
Para autenticarse con la API, le proporcionaremos una nueva clave de API. Al ingresar a la página “Configuración”, puede copiar la clave de API como se indica en la imagen.

Paso 4: Instale la API
Instale la API usando el administrador de paquetes específico de su lenguaje de programación.

Después de la instalación, importe las bibliotecas necesarias en su entorno de desarrollo. Inicialice la API con su clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU clave de API de Novita AI>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B-Instruct representa un avance importante en los modelos de visión-lenguaje, mejorando la comprensión visual, la comprensión de video, las capacidades de agente, la localización y la generación de salidas estructuradas. Con entrenamiento de resolución dinámica y un codificador visual eficiente, logra un rendimiento superior en puntos de referencia en tareas de imagen, video y agente.
Preguntas frecuentes
¿Cómo mejora Qwen2.5-VL-instruct la comprensión visual?
Analiza texto (multilingüe, vertical), gráficos, iconos y diseños, mientras extrae información clave y convierte documentos en formatos estructurados como HTML.
¿Cuáles son las nuevas capacidades de video de Qwen2.5-VL-instruct?
Procesa videos de más de 1 hora, localiza eventos al segundo, realiza anclaje temporal, genera descripciones estructuradas y resume contenido.
¿Cuál es el hardware recomendado para ejecutar Qwen2.5-VL-instruct?
Para uso local, se recomienda una GPU con al menos 384 GB de VRAM. ¡O puede elegir una API efectiva como Novita AI para usarlo!
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



