

Vous voulez un contrôle total sur le modèle IA qui alimente votre assistant de codage ? Ce guide complet vous montre comment déployer votre propre modèle personnalisé sur l’infrastructure GPU de Novita AI et l’intégrer de manière transparente à l’IDE Cursor. Contrairement à l’utilisation de points de terminaison API préconfigurés, le déploiement de votre propre instance vous donne un contrôle total sur la sélection des modèles, la configuration et l’optimisation des performances.
Exemple pratique : DeepSeek-R1-Distill-Qwen-1.5B
Étape 1 : Identifier l’architecture de base de votre modèle
Rendez-vous sur https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B. Copiez le nom du modèle pour une utilisation ultérieure.
Étape 2 : Trouver l’analyseur correspondant
Consultez la documentation sur l’appel d’outils vLLM. Pour les modèles de la famille Qwen-2.5, utilisez l’analyseur hermes.
Pourquoi l’appel d’outils est essentiel pour les agents de codage
Cursor n’envoie pas seulement des prompts et ne reçoit pas seulement des réponses textuelles. Il a besoin de modèles capables d’interagir avec votre environnement de développement, de comprendre le contexte sur plusieurs fichiers et d’exécuter des actions spécifiques. L’appel d’outils est le pont qui permet ces fonctionnalités.
Différentes familles de modèles nécessitent des analyseurs différents. Associez votre modèle au type d’analyseur correct en consultant la documentation sur l’appel d’outils vLLM.
Étape 3 : Créer votre compte Novita AI
- Rendez-vous sur la plateforme Novita AI
- Cliquez sur “S’inscrire” pour un accès instantané
- Obtenez 1 $ de crédits gratuits automatiquement lors de l’inscription
Étape 4 : Sélection du modèle
Sélectionnez le DeepSeek-R1-Distill-Qwen-1.5B dans la bibliothèque de modèles ou créez votre propre modèle.
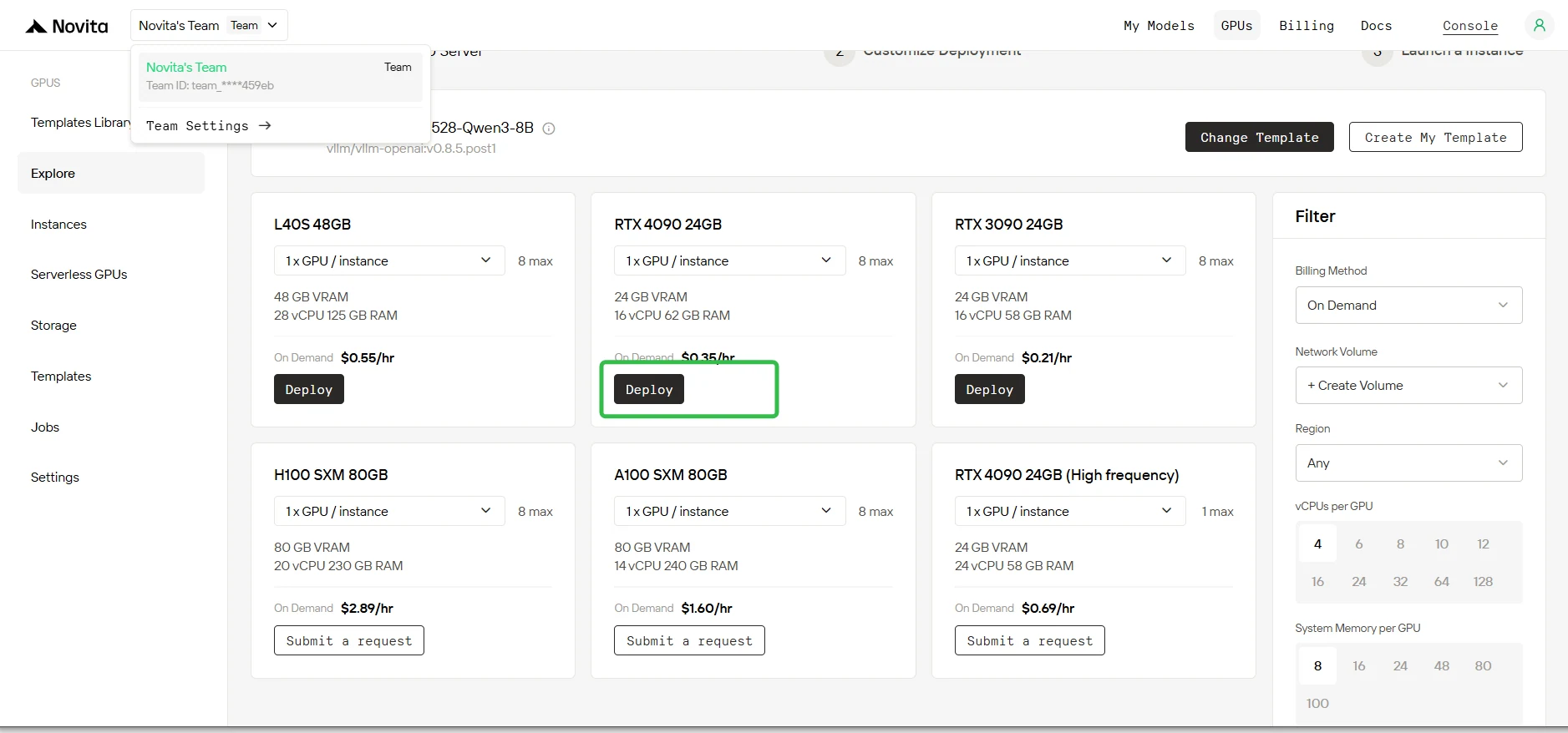
Étape 5 : Confirmation des paramètres
Vérifiez les paramètres de déploiement affichés sur l’écran de configuration. Assurez-vous que tous les réglages sont corrects et cliquez sur Suivant pour continuer.
Dans le champ Paramètres de démarrage du conteneur, ajoutez :
--enable-auto-tool-choice --tool-call-parser hermes
Important : l’analyseur doit correspondre à la famille de votre modèle. Consultez la documentation vLLM pour trouver l’analyseur correct.
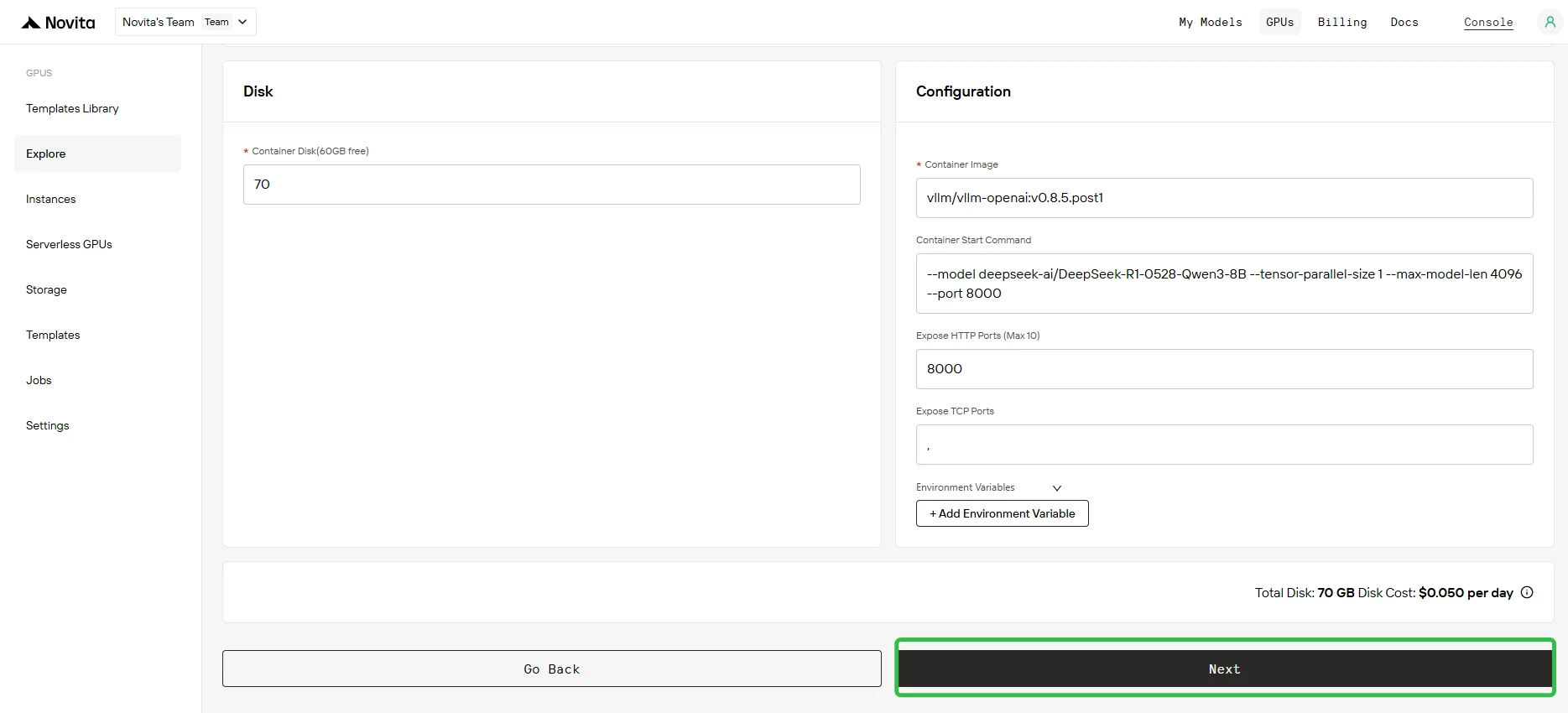
Étape 6 : Déploiement de l’instance
Cliquez sur Déployer pour lancer le processus de création de l’instance. Le système commencera à approvisionner votre instance GPU.
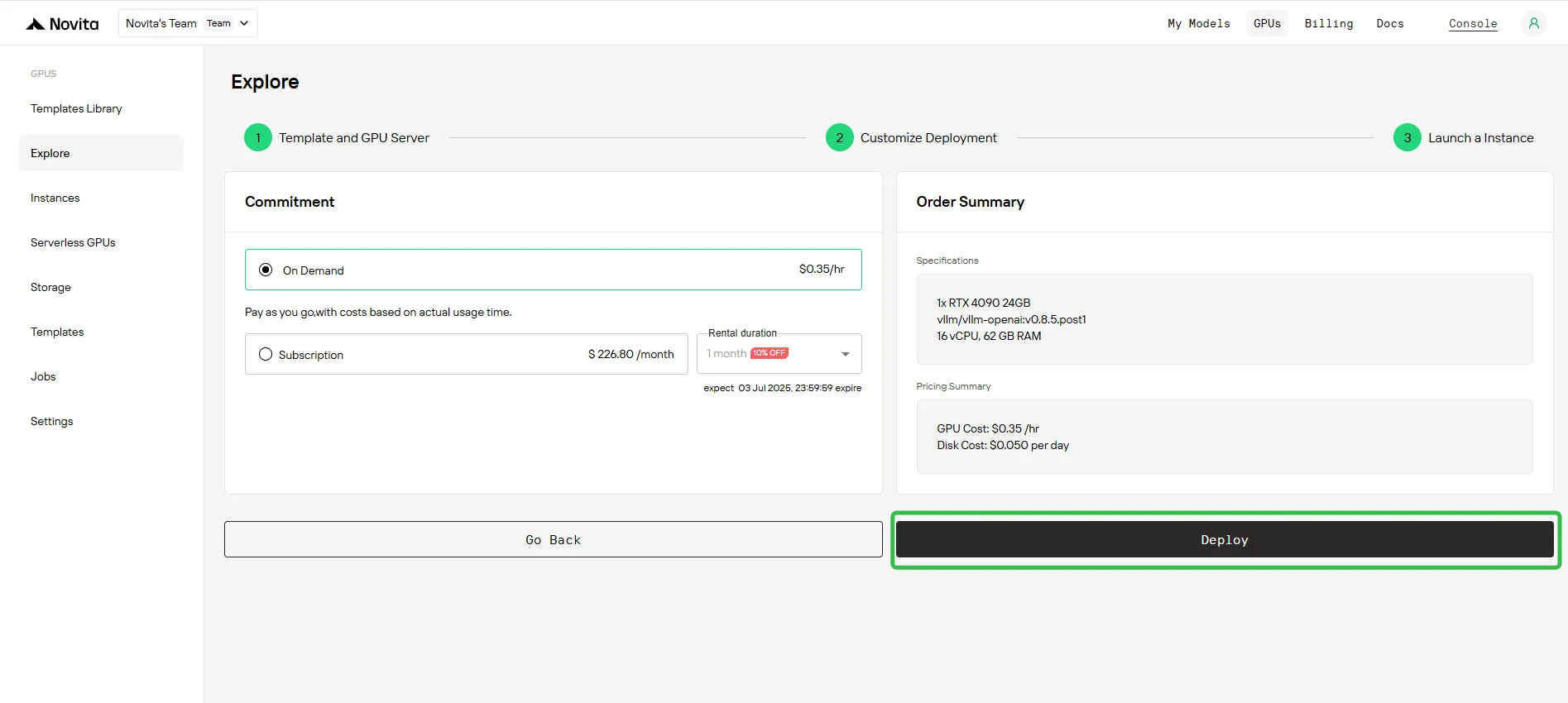
Étape 7 : Surveiller l’avancement du déploiement
Accédez à la Gestion des instances pour ouvrir la console de contrôle. Ce tableau de bord vous permet de suivre l’état du déploiement en temps réel.
Étape 8 : Voir l’état de téléchargement de l’image
Cliquez sur votre instance spécifique pour suivre l’avancement du téléchargement de l’image du conteneur. Ce processus peut prendre plusieurs minutes selon les conditions du réseau.
Étape 9 : Vérifier le succès du déploiement
Recherchez le message "Application startup complete." dans les journaux de l’instance. Cela indique que le processus de déploiement s’est terminé avec succès.
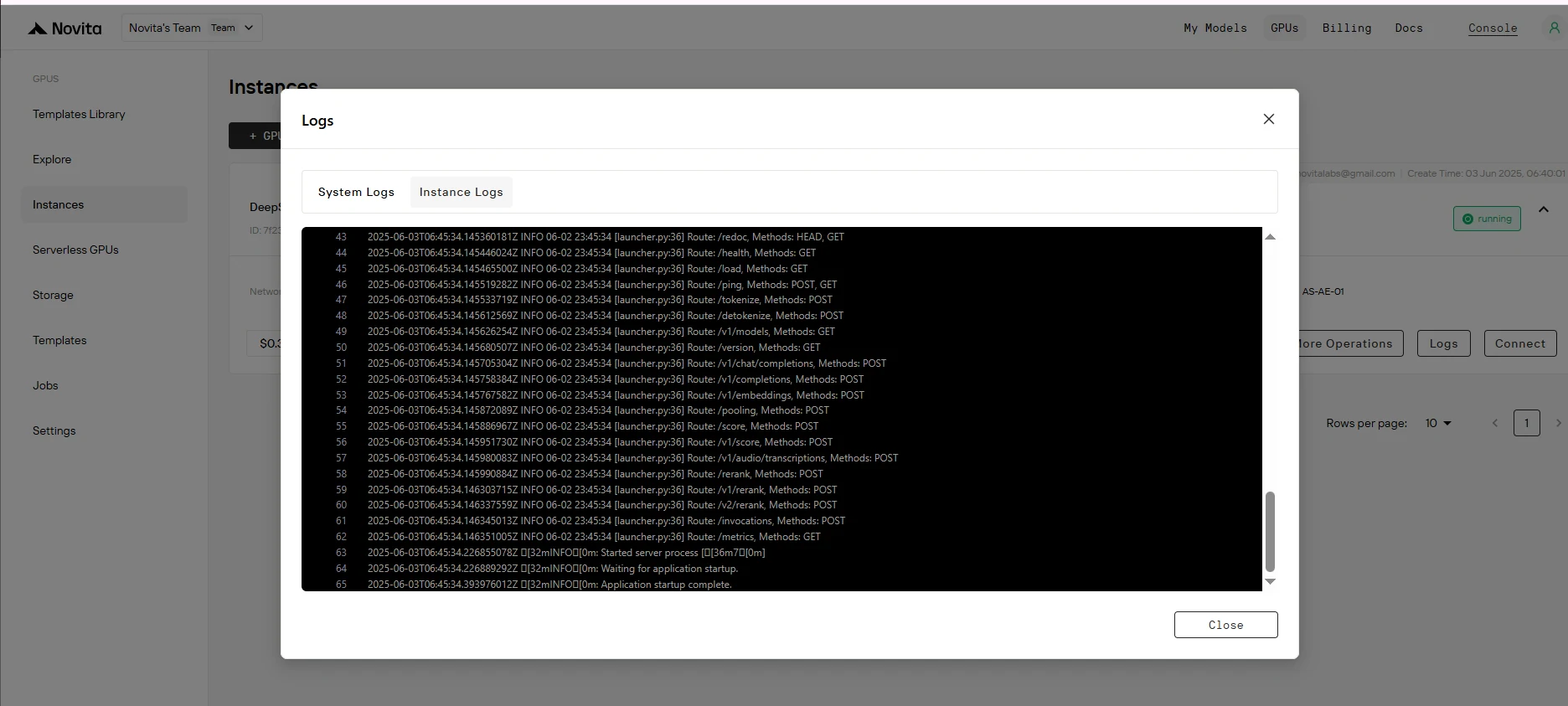
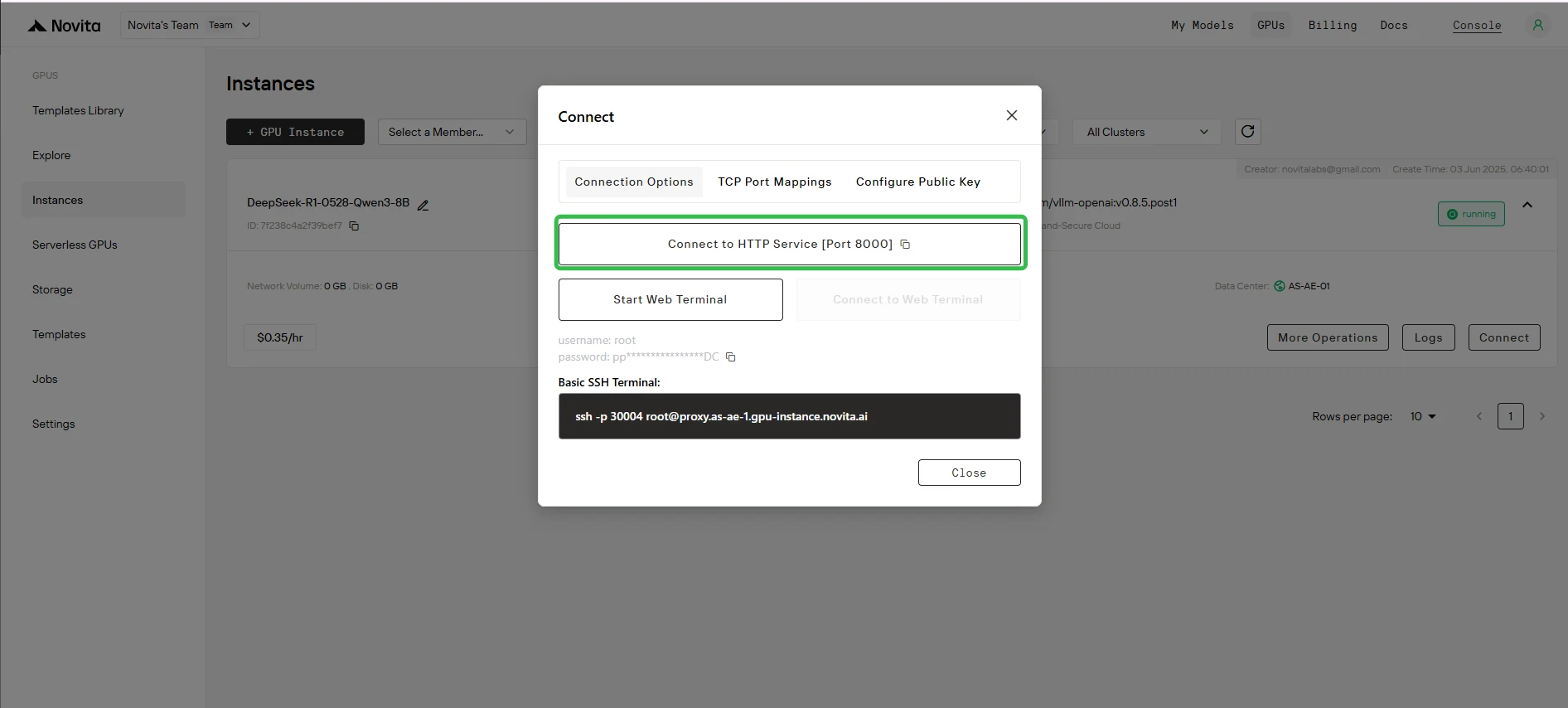
Étape 10 : Obtenir l’URL d’accès
Cliquez sur « Se connecter », puis sur « Se connecter au service HTTP [Port 8000] ». Comme il s’agit d’un service API, vous devrez copier l’adresse.

Guide complet de configuration de l’IDE Cursor
Étape 1 : Installer et souscrire à Cursor
- Téléchargez l’IDE Cursor depuis cursor.com
- Effectuez l’achat du forfait Pro (20 $/mois)
- Lancez l’application
Important : le mode Agent et la fonctionnalité Édition nécessitent un abonnement Cursor Pro (20 $/mois).
Étape 2 : Accéder aux paramètres des modèles
- Ouvrez les paramètres de Cursor (Ctrl+, ou Cmd+,)
- Accédez à la section « Modèles »
- Repérez la zone « Configuration API »
Étape 3 : Configurer votre instance personnalisée
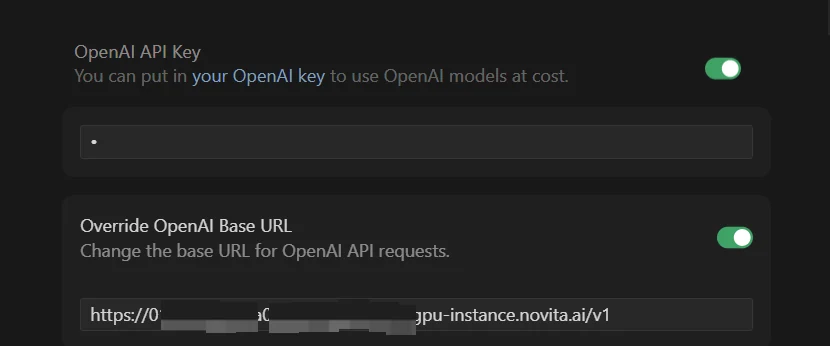
- ✅ Activez l’option « Clé API OpenAI »
- ✅ Activez l’option « Remplacer l’URL de base OpenAI »
Étape 4 : Saisir les identifiants de votre instance
Dans le champ « Clé API OpenAI » : saisissez n’importe quelle valeur (elle ne peut pas être vide)
Dans le champ « Remplacer l’URL de base OpenAI » : collez votre URL avec le suffixe /v1 :
https://your-instance-id.novita.ai/v1
⚠️ Critique : le suffixe /v1 est obligatoire. Sans lui, Cursor ne peut pas communiquer avec votre instance.
Étape 5 : Ajouter votre modèle personnalisé
- Cliquez sur « + Ajouter un modèle personnalisé »
- Saisissez le nom exact du modèle sur Huggingface
- Important : le nom du modèle doit correspondre exactement, la casse est prise en compte
Étape 6 : Enregistrer et sélectionner votre modèle
- Enregistrez votre configuration
- Sélectionnez votre modèle personnalisé dans le menu déroulant de Cursor
Tests et vérification
Test en mode Ask
- Démarrez une nouvelle discussion en mode Ask
- Envoyez une question de codage simple
- Vérifiez que vous recevez une réponse
Test en mode Agent
- Passez en mode Agent
- Demandez une tâche de codage en plusieurs étapes
- Vérifiez que la fonctionnalité d’appel d’outils fonctionne
Erreurs de configuration courantes et solutions
❌ Le modèle ne répond pas
Solutions :
- ✅ Vérifiez que les deux options API sont activées
- ✅ Vérifiez que l’URL de base inclut le suffixe
/v1 - ✅ Confirmez que l’état de l’instance indique « En cours d’exécution »
- ✅ Vérifiez que vous disposez de crédits suffisants
❌ Connexion refusée
Solutions :
- ✅ Vérifiez que l’URL de base n’a pas de barre oblique finale après
/v1 - ✅ Assurez-vous qu’il n’y a pas d’espaces en trop dans l’URL
- ✅ Vérifiez votre connexion internet
❌ Nom de modèle introuvable
Solutions :
- ✅ Copiez le nom exact du modèle depuis le tableau de bord
- ✅ Vérifiez la sensibilité à la casse
- ✅ Vérifiez qu’il n’y a pas d’espaces en trop
❌ Fonctionnalités limitées
Solutions :
- ✅ Vérifiez que les paramètres d’appel d’outils ont été ajoutés lors du déploiement
- ✅ Vérifiez que l’analyseur correct a été sélectionné
- ✅ Redémarrez l’application Cursor
Conclusion
Déployer votre propre modèle sur Novita AI pour Cursor vous offre un contrôle total sur votre assistant de codage IA.
En suivant ce guide et en prêtant une attention particulière à la configuration de l’appel d’outils et aux paramètres de connexion, vous pourrez intégrer avec succès des modèles IA personnalisés à Cursor et prendre le contrôle total de votre assistant de codage.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



