

¿Quieres tener control total sobre qué modelo de IA impulsa tu asistente de codificación? Esta guía completa te muestra cómo implementar tu propio modelo personalizado en la infraestructura de GPU de Novita AI e integrarlo sin problemas con el IDE Cursor. A diferencia de usar endpoints de API preconfigurados, implementar tu propia instancia te da control total sobre la selección del modelo, la configuración y la optimización del rendimiento.
Ejemplo práctico: DeepSeek-R1-Distill-Qwen-1.5B
Paso 1: Identifica la arquitectura base de tu modelo
Visita https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B. Copia el nombre del modelo para usarlo más tarde.
Paso 2: Encuentra el analizador (parser) correspondiente
Consulta la documentación de vLLM tool calling. Para los modelos de la familia Qwen-2.5, usa el analizador hermes.
Por qué es importante el Tool Calling para los agentes de codificación
Cursor no solo envía indicaciones y recibe respuestas de texto. Necesita modelos que puedan interactuar con tu entorno de desarrollo, entender el contexto a través de múltiples archivos y ejecutar acciones específicas. El tool calling es el puente que permite estas capacidades.
Diferentes familias de modelos requieren diferentes analizadores. Consulta la documentación de vLLM sobre tool calling para elegir el analizador correcto para tu modelo.
Paso 3: Crea tu cuenta en Novita AI
- Visita Plataforma Novita AI
- Haz clic en “Registrarse” para acceso instantáneo
- Obtén $1 en créditos gratis automáticamente al registrarte
Paso 4: Selección de plantilla
Selecciona el modelo DeepSeek-R1-Distill-Qwen-1.5B de la biblioteca de modelos o crea tu propia plantilla.
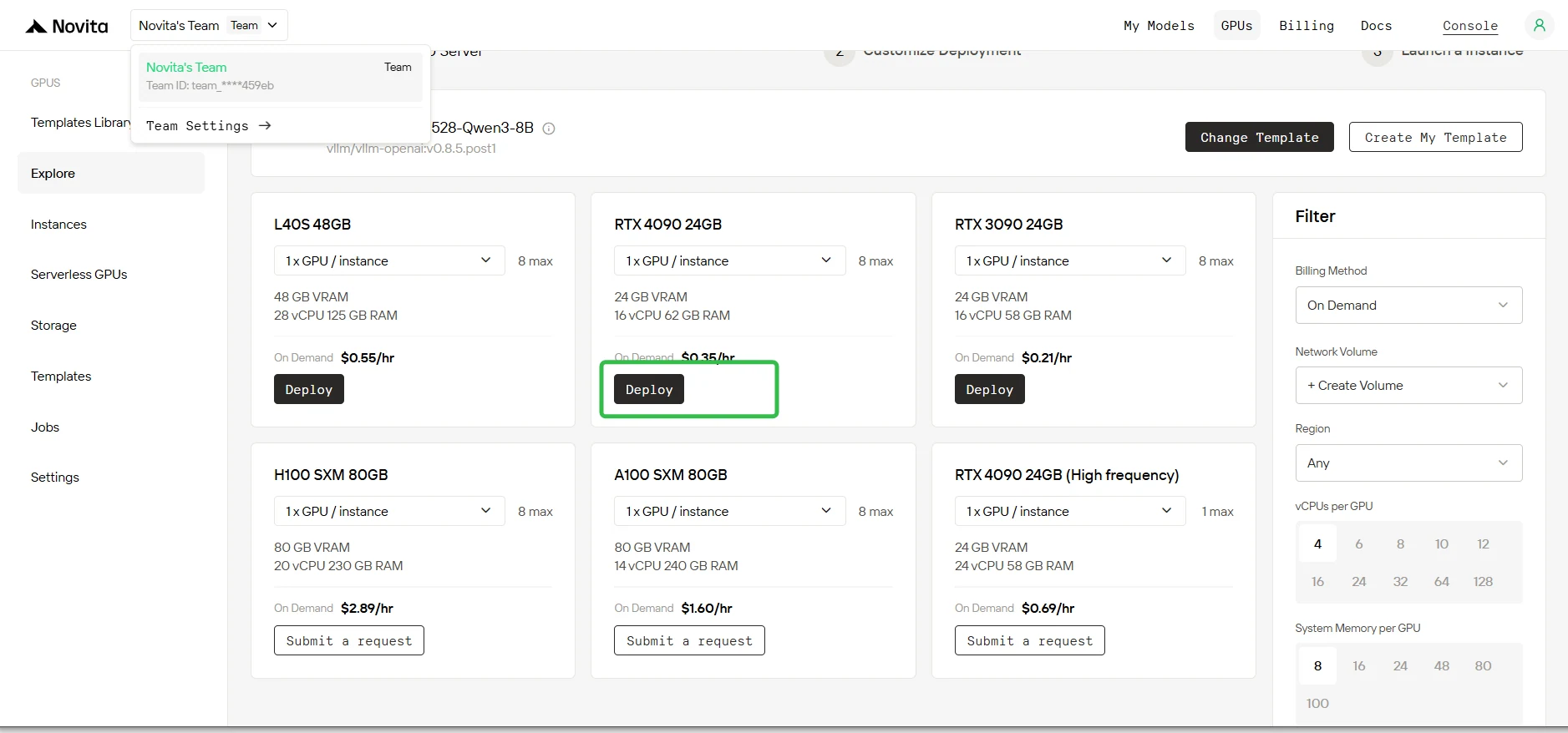
Paso 5: Confirmación de parámetros
Revisa los parámetros de implementación que se muestran en la pantalla de configuración. Verifica que todos los ajustes sean correctos y haz clic en Siguiente para continuar.
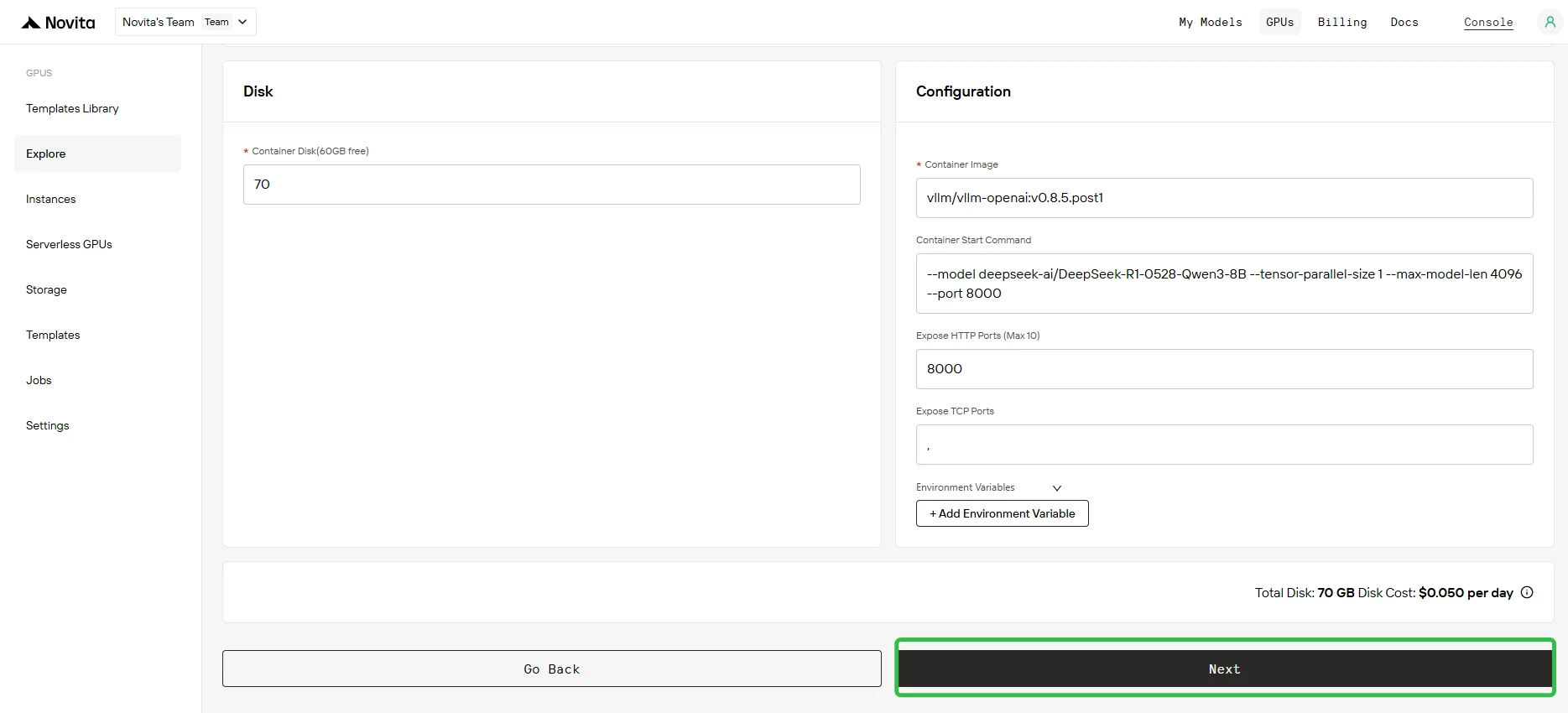
En el campo Parámetros de inicio del contenedor, agrega:
--enable-auto-tool-choice --tool-call-parser hermes
Importante: El analizador debe coincidir con la familia de tu modelo. Consulta la documentación de vLLM para el analizador correcto.
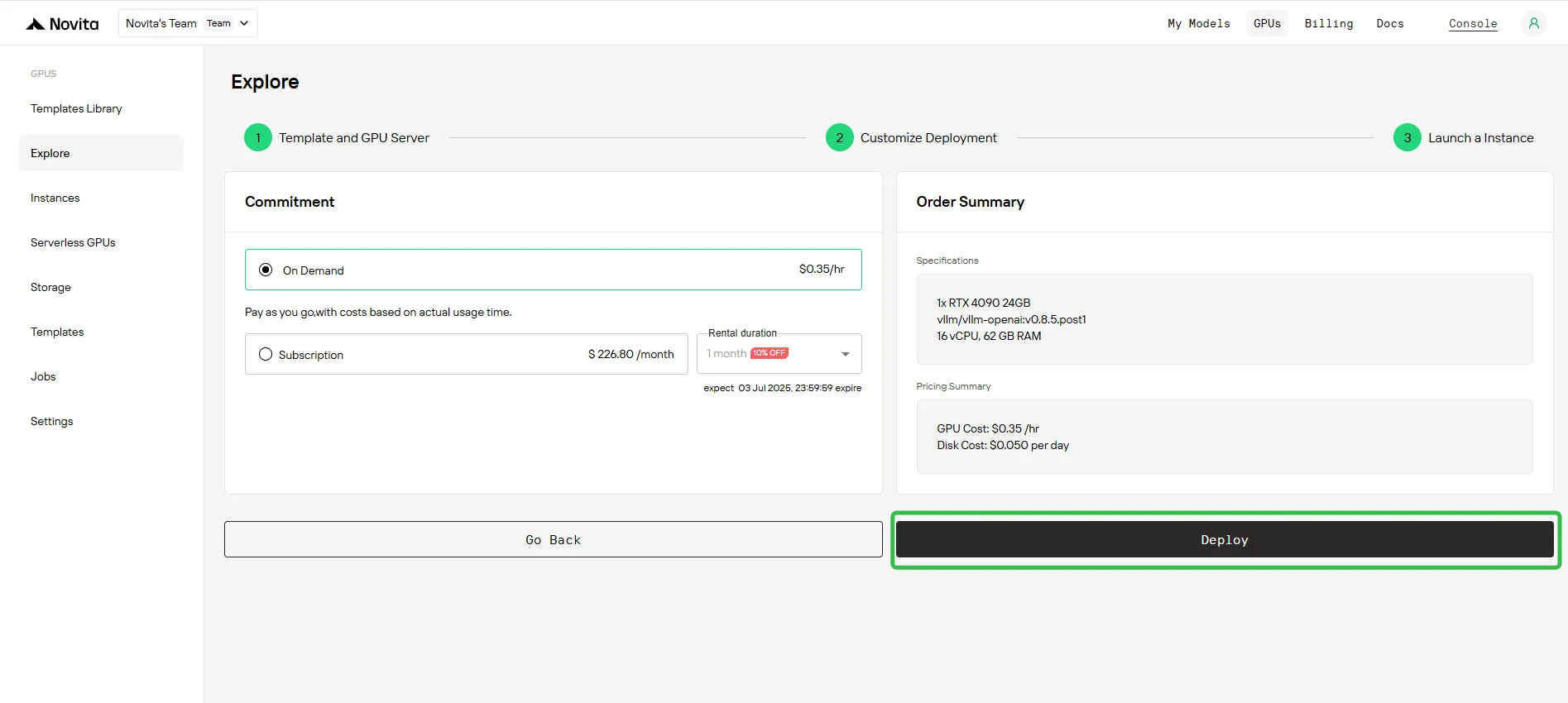
Paso 6: Implementación de la instancia
Haz clic en Implementar para iniciar el proceso de creación de la instancia. El sistema comenzará a aprovisionar tu instancia de GPU.
Paso 7: Supervisa el progreso de la implementación
Navega a Gestión de instancias para acceder a la consola de control. Este panel te permite seguir el estado de la implementación en tiempo real.
Paso 8: Ver el estado de descarga de la imagen
Haz clic en tu instancia específica para monitorear el progreso de la descarga de la imagen del contenedor. Este proceso puede tardar varios minutos dependiendo de las condiciones de la red.
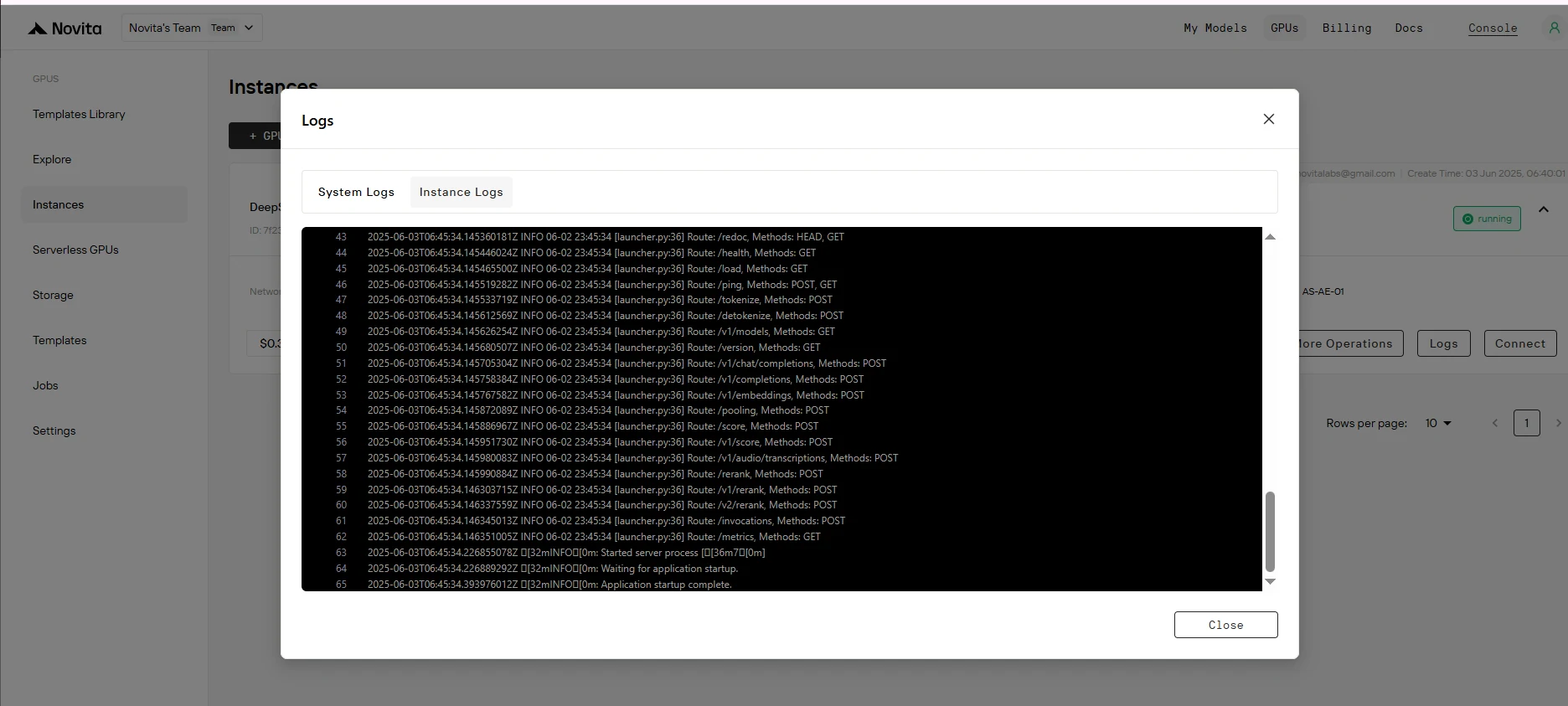
Paso 9: Verifica que la implementación se haya completado correctamente
Busca el mensaje "Application startup complete." en los registros de la instancia. Esto indica que el proceso de implementación ha finalizado con éxito.
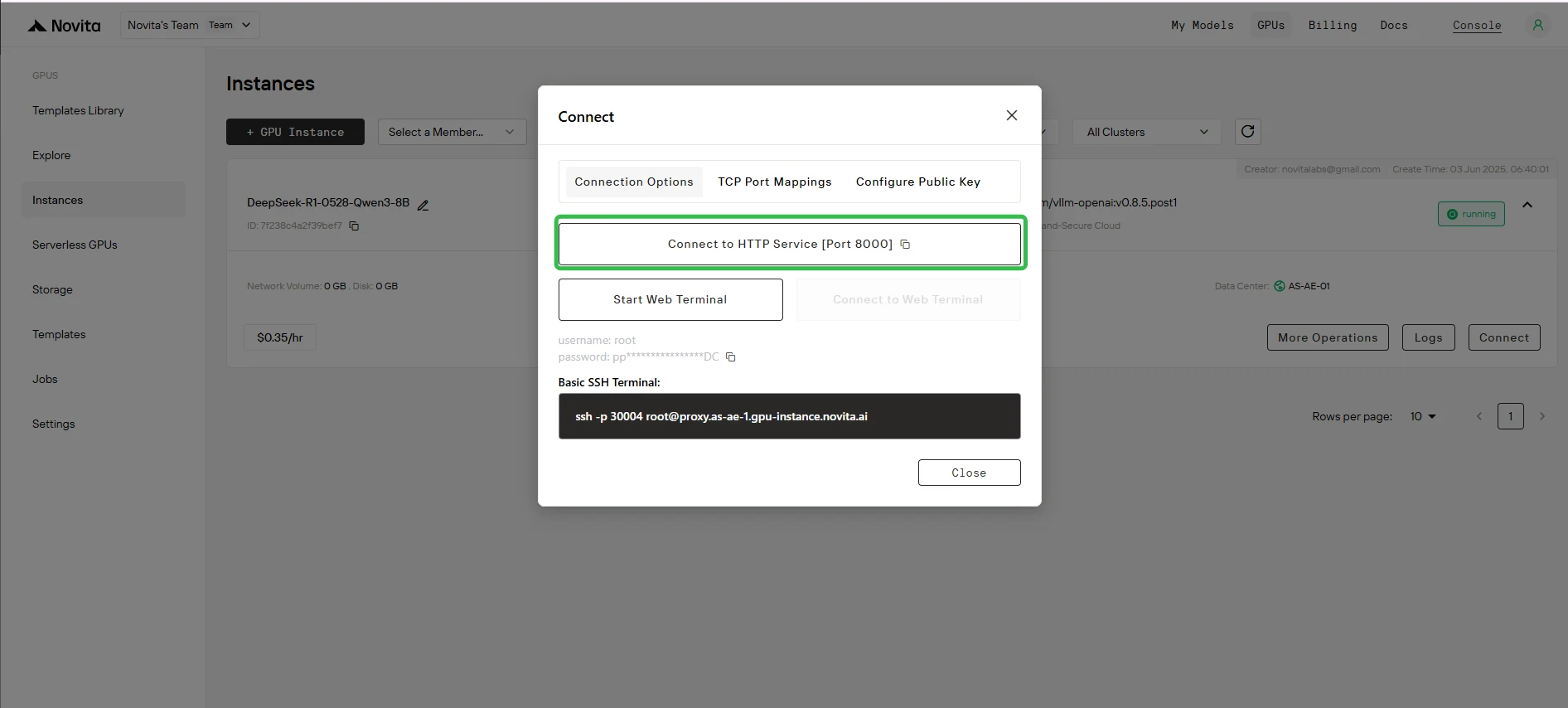
Paso 10: Obtén la URL de acceso
Haz clic en “Conectar”, luego haz clic en –> “Conectar al servicio HTTP [Puerto 8000]”. Como se trata de un servicio API, deberás copiar la dirección.

Guía completa de configuración del IDE Cursor
Paso 1: Instala y suscríbete a Cursor
- Descarga el IDE Cursor desde cursor.com
- Completa la compra del plan Pro ($20/mes)
- Inicia la aplicación
Importante: El modo Agente y la funcionalidad de Edición requieren una suscripción a Cursor Pro ($20/mes).
Paso 2: Accede a la configuración del modelo
- Abre Configuración de Cursor (Ctrl+, o Cmd+,)
- Navega a la sección “Modelos”
- Localiza el área “Configuración de API”
Paso 3: Configura tu instancia personalizada
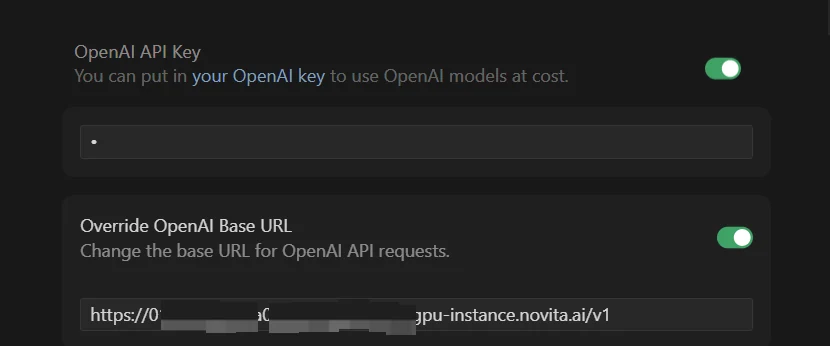
- ✅ Activa la opción “Clave de API de OpenAI”
- ✅ Activa la opción “Anular URL base de OpenAI”
Paso 4: Ingresa las credenciales de tu instancia
En el campo “Clave de API de OpenAI”: Ingresa cualquier valor (no puede estar vacío)
En el campo “Anular URL base de OpenAI”: Pega tu URL con el sufijo /v1:
https://tu-id-de-instancia.novita.ai/v1
⚠️ Crítico: El sufijo /v1 es obligatorio. Sin él, Cursor no puede comunicarse con tu instancia.
Paso 5: Añade tu modelo personalizado
- Haz clic en “+ Agregar modelo personalizado”
- Ingresa el nombre exacto del modelo en Huggingface
- Importante: El nombre del modelo debe coincidir exactamente, distingue mayúsculas y minúsculas
Paso 6: Guarda y selecciona tu modelo
- Guarda tu configuración
- Selecciona tu modelo personalizado en el menú desplegable de Cursor
Pruebas y verificación
Prueba en modo Pregunta (Ask Mode)
- Inicia un nuevo chat en modo Pregunta
- Envía una pregunta de codificación simple
- Verifica que recibes una respuesta
Prueba en modo Agente (Agent Mode)
- Cambia a modo Agente
- Solicita una tarea de codificación de varios pasos
- Verifica que la funcionalidad de tool calling funciona correctamente
Errores comunes de configuración y soluciones
❌ El modelo no responde
Soluciones:
- ✅ Verifica que ambas opciones de API estén activadas
- ✅ Comprueba que la URL base incluya el sufijo
/v1 - ✅ Confirma que el estado de la instancia muestre “En ejecución”
- ✅ Verifica que tengas créditos suficientes
❌ Conexión rechazada
Soluciones:
- ✅ Comprueba que la URL base no tenga barra inclinada al final después de
/v1 - ✅ Asegúrate de que no haya espacios adicionales en la URL
- ✅ Verifica la conexión a internet
❌ Nombre de modelo no encontrado
Soluciones:
- ✅ Copia el nombre exacto del modelo desde el panel de control
- ✅ Verifica mayúsculas y minúsculas
- ✅ Asegúrate de que no haya espacios adicionales
❌ Funcionalidad limitada
Soluciones:
- ✅ Verifica que los parámetros de tool calling se hayan añadido durante la implementación
- ✅ Comprueba que se haya seleccionado el analizador correcto
- ✅ Reinicia la aplicación Cursor
Conclusión
Implementar tu propio modelo en Novita AI para Cursor te proporciona un control total sobre tu asistente de codificación de IA.
Siguiendo esta guía y prestando especial atención a la configuración de tool calling y los parámetros de conexión, podrás integrar con éxito modelos de IA personalizados con Cursor y tomar el control total de tu asistente de codificación.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona GPU en la nube asequible y confiable para construir y escalar.



