

Introduction
Face à la multitude de modèles de langage de grande taille (LLM) disponibles, trouver celui qui correspond à vos besoins spécifiques peut sembler une tâche ardue. Le paysage évolue constamment, avec de nouveaux modèles et des versions affinées qui émergent presque chaque semaine. Par conséquent, toute tentative de cataloguer les LLM et leurs attributs est vouée à devenir rapidement obsolète.
Au lieu d’essayer de décrire chaque meilleur LLM et de détailler leurs forces et faiblesses, cet article vise à fournir un ensemble de critères pour évaluer les modèles. En offrant un cadre d’analyse, les lecteurs pourront évaluer les modèles nouvellement publiés par rapport à leurs caractéristiques principales et les comparer efficacement. Les attributs principaux à considérer lors de l’évaluation d’un LLM sont les suivants :
- taille
- type d’architecture
- performances sur les benchmarks
- processus d’entraînement et biais
- licence/disponibilité
Quelle est la taille d’un LLM ?
Votre première considération lors du choix d’un LLM est votre contrainte budgétaire. Exploiter des LLM peut entraîner des coûts substantiels, soulignant l’importance d’opter pour un modèle qui reste dans les limites budgétaires. Un indicateur du coût est le nombre de paramètres d’un LLM.
Quel est le nombre de paramètres d’un modèle ?
La quantité de paramètres correspond au nombre de poids et de biais ajustés par le modèle lors de l’entraînement et utilisés pour calculer sa sortie. Pourquoi cette quantité est-elle importante ? Elle donne une approximation approximative des performances et de la vitesse d’inférence d’un modèle. En général, ces facteurs sont directement liés : plus le nombre de paramètres augmente, plus le coût associé à la génération d’une sortie est élevé.
Quelle est la vitesse d’inférence d’un modèle ?
La vitesse d’inférence d’un modèle de langage fait référence au temps nécessaire pour traiter une entrée, mesurant essentiellement sa vitesse de sortie. Il est important de reconnaître que la vitesse d’inférence et les performances globales d’un modèle sont complexes et multifactorielles, et ne sont pas uniquement déterminées par le nombre de paramètres. Cependant, dans le cadre de cet article, le nombre de paramètres fournit une estimation approximative des performances potentielles d’un modèle. Heureusement, il existe plusieurs méthodes établies pour réduire le temps d’inférence des modèles d’apprentissage automatique.

Nombre de paramètres pour chaque LLM.
Un modèle de taille moyenne contient généralement moins de 10 milliards de paramètres, tandis que les modèles plus abordables peuvent en avoir moins d’un milliard. Cependant, les modèles de moins d’un milliard de paramètres sont souvent plus anciens ou ne sont pas spécifiquement conçus pour des tâches de génération de texte. À l’autre extrémité du spectre, les modèles coûteux possèdent plus de 100 milliards de paramètres, à l’exemple de GPT-4 avec un nombre impressionnant de 1,76 billion de paramètres. De nombreuses séries de modèles, notamment LLaMa 2, Mistral, Falcon et GPT, proposent à la fois des versions plus petites, avec moins de 10 milliards de paramètres, et des versions plus grandes allant de 10 à 100 milliards de paramètres.
Quels sont les différents types de LLM ?
En termes généraux, les LLM basés sur Transformer peuvent être classés en trois groupes selon leur architecture : encodeur uniquement, encodeur-décodeur et décodeur uniquement. Cette catégorisation permet de comprendre l’objectif visé du modèle et ses performances dans les tâches de génération de texte.
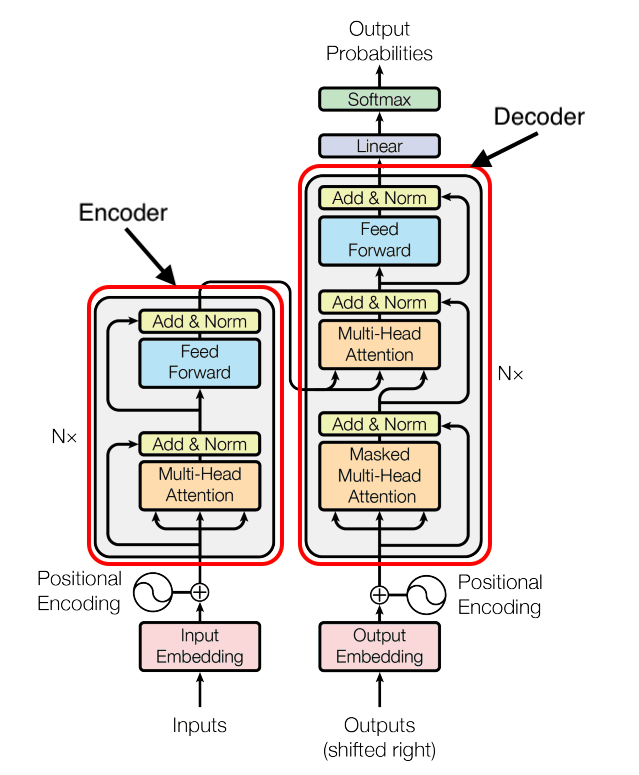
Qu’est-ce qu’un modèle encodeur uniquement ?
Les modèles encodeurs uniquements utilisent uniquement un composant encodeur, chargé d’encoder et de catégoriser le texte d’entrée. Ces modèles sont utiles pour attribuer du texte à des catégories spécifiques. BERT, le modèle encodeur uniquement prédominant, a été entraîné en tant que modèle de langage masqué (MLM) et pour la prédiction de phrases suivantes (NSP). Ces deux objectifs d’entraînement impliquent de discerner les éléments essentiels d’une phrase.
Qu’est-ce qu’un modèle encodeur-décodeur ?
Les modèles encodeur-décodeur encodent d’abord le texte d’entrée, à l’instar des modèles encodeurs uniquements, avant de générer ou décoder une réponse basée sur les entrées encodées. Un exemple d’architecture encodeur-décodeur est BART. Ces modèles sont polyvalents, adaptés à la fois aux tâches de génération et de compréhension de texte, ce qui les rend particulièrement utiles pour la traduction. BART, par exemple, excelle dans le résumé de textes longs, tels que des articles, en sorties cohérentes. Par exemple, BART-Large-CNN est une variante affinée spécialisée dans la génération de résumés de texte, ayant été entraînée sur une gamme diversifiée d’articles de presse. Dans l’ensemble, les modèles encodeur-décodeur servent un double objectif, répondant à la fois à la compréhension et à la génération de texte.
Qu’est-ce qu’un modèle décodeur uniquement ?
Les modèles décodeurs uniquement se spécialisent dans la génération du mot ou du token suivant en fonction d’une invite donnée, se concentrant exclusivement sur les tâches de génération de texte. Ils offrent une simplicité d’entraînement et sont particulièrement efficaces pour des besoins de génération de texte pur. Les séries de modèles comme GPT, Mistral et LLaMa appartiennent à la catégorie des décodeurs uniquements. Si votre besoin principal est la génération de texte, les modèles décodeurs uniquements sont le choix privilégié.
Cependant, il convient de noter que le Mistral 8x7B (également connu sous le nom de Mixtral) utilise une architecture unique appelée « mixture d’experts », qui le distingue des modèles décodeurs uniquements conventionnels. De même, des indications suggèrent que GPT-4 pourrait utiliser une technique similaire. Par conséquent, ces modèles ne rentrent pas parfaitement dans la catégorie des décodeurs uniquements. De plus, des techniques architecturales émergentes comme la génération augmentée de récupération (RAG) échappent à la classification dans ces catégories établies.
Vous pouvez approfondir le sujet dans notre article dédié à la technologie RAG : Qu’est-ce que le RAG : Une introduction complète à la génération augmentée de récupération

Comment mesurer la qualité des performances d’un LLM
Diverses métriques sont utilisées pour évaluer la capacité d’un modèle de langage à comprendre, interpréter et fournir des réponses précises à diverses invites. Ces méthodes d’évaluation diffèrent selon l’utilisation prévue du modèle de langage. Par exemple, BERT, un modèle encodeur uniquement principalement conçu pour des tâches comme la classification, n’est pas évalué selon les mêmes critères que GPT-3, un modèle décodeur uniquement conçu pour la génération de texte. Dans les sections suivantes, nous expliquerons quelques-unes des méthodologies utilisées pour évaluer les LLM de génération de texte.
Mesurer la qualité d’un LLM à l’aide d’examens académiques
Une méthode courante pour évaluer l’efficacité d’un modèle langagier génératif consiste à le soumettre à des examens. Par exemple, GPT-4 a été évalué par rapport à GPT-3.5 sur une série de tests académiques. Grâce à ce processus, les performances du modèle sont comparées à la fois aux scores humains et à ceux des modèles précédents, fournissant des informations sur ses capacités de raisonnement dans un contexte académique. Voici une brève compilation de certains des examens administrés à GPT-4, ainsi que ses scores comparatifs par rapport à GPT-3.5 et à la performance humaine moyenne :

Performances de GPT-4 et GPT-3.5 aux examens standardisés par rapport à la moyenne humaine.
Une autre métrique de performance similaire aux examens académiques consiste à présenter au modèle divers ensembles de questions-réponses (QnA). Cette approche est utilisée dans le Hugging Face Open LLM Leaderboard, offrant une ressource précieuse pour comparer différents LLM en fonction de leurs performances sur des ensembles de données QnA. Ces ensembles fournissent un moyen simple de benchmarker un LLM, permettant d’évaluer son intelligence globale et ses capacités logiques.
Tableau comparatif de la qualité entre LLM
Il est essentiel de noter que comparer un score en 0-shot à un score en 25-shot a peu de valeur. Idéalement, pour des comparaisons de qualité, vous devez maintenir une cohérence dans le type de sollicitation utilisé. Même en comparant deux points de données avec la même méthode de sollicitation, des différences dans les procédures de test peuvent encore entraîner des inexactitudes. Néanmoins, ce qui suit devrait fournir une comparaison approximative de la qualité :

Tableau comparatif de la qualité entre LLM sur les tests ARC, MMLU et WinoGrande en utilisant des sollicitations few-shot et zero-shot.
Quel est le meilleur LLM actuel à utiliser comme chatbot ?
En examinant ce tableau, tout en tenant compte des avertissements mentionnés précédemment, il est évident que GPT-4 se distingue comme le LLM le plus performant en termes de qualité globale. Cependant, pour un rapport qualité-prix optimal, les modèles Mistral offrent le meilleur choix. En particulier, la version Mistral 8x7B utilise une technique unique qui combine plusieurs modèles Mistral 7b, résultant en des sorties de meilleure qualité. Cette approche crée un modèle très efficace qui excelle également dans les évaluations de référence.
Comment les données d’entraînement peuvent affecter les LLM
La sélection des ensembles de données d’entraînement pour un modèle soulève des considérations importantes. Quel type de données a été utilisé ? L’ensemble de données est-il spécifiquement adapté à certaines applications ? Y a-t-il des biais inhérents dans l’ensemble de données qui pourraient affecter le modèle ?
Comment les biais des modèles émergent, en prenant BERT comme exemple
Pour la plupart des LLM, les données d’entraînement sont généralement étendues, visant à fournir au modèle une compréhension fondamentale du langage. BERT, par exemple, a été pré-entraîné en utilisant Wikipédia (2 500 millions de mots) et BookCorpus (800 millions de mots). Cependant, dans certains cas, comme avec les modèles de Mistral, l’ensemble de données d’entraînement reste indisponible au public.
Examiner ces ensembles de données peut offrir un aperçu des biais potentiels inhérents au modèle. Considérez BERT, qui repose fortement sur l’ensemble de données Wikipédia en anglais pour l’entraînement. Bien que Wikipédia soit souvent considéré comme une source neutre et impartiale, cela n’est pas toujours vrai. Par exemple, The Guardian a rapporté que seulement 16 % des éditeurs de Wikipédia sont des femmes, et seulement 17 % des articles sur des personnalités notables concernent des femmes. De plus, le contenu sur l’Afrique subsaharienne est principalement rédigé par des personnes extérieures à la région. Étant donné la dépendance de BERT à Wikipédia en anglais, il est plausible que les biais présents sur la plateforme puissent être hérités par le modèle. En effet, des preuves suggèrent que BERT présente des biais de genre et de race dans ses sorties. En résumé, les biais dans les ensembles de données d’entraînement des modèles pré-entraînés peuvent influencer leurs capacités de génération de texte. Par conséquent, il est essentiel de prendre en compte ces biais car ils impactent l’expérience de l’utilisateur final.
Qu’est-ce qu’un modèle affiné ?
L’affinage consiste à ré-entraîner un modèle déjà entraîné sur de nouvelles données, conduisant souvent à la création de modèles dérivés spécialisés pour des objectifs spécifiques. Le choix des données utilisées pour l’affinage est crucial lors de l’évaluation des applications potentielles d’un modèle. Par exemple, FinBERT, un dérivé de BERT, a été affiné sur un vaste ensemble de données financières, ce qui le rend particulièrement utile pour analyser le sentiment financier d’un texte. Si vous souhaitez en savoir plus sur l’affinage, lisez notre article : Comment affiner les grands modèles de langage ?
Bien que certains modèles soient conçus dans l’intention de permettre un affinage ultérieur, d’autres sont déjà affinés pour remplir des objectifs spécifiques. Par exemple, les modèles comme Falcon peuvent avoir des versions chat affinées pour fonctionner efficacement comme chatbots. Diverses méthodes sont employées pour l’affinage des modèles, bien que les détails de ces techniques dépassent le cadre de cet article. En général, un modèle affiné fournit généralement des informations sur ses objectifs visés et les techniques d’affinage spécifiques appliquées.
Quel ensemble de données chaque modèle de langage utilise-t-il ?
Étant donné l’impact significatif des données d’entraînement sur les performances d’un modèle, les développeurs ont conçu diverses méthodes de scraping web pour acquérir des ensembles de données de haute qualité. Par exemple, l’outil Webtext d’OpenAI scrape « tous les liens sortants de Reddit qui ont reçu au moins 3 karma ». Vous trouverez ci-dessous une compilation des ensembles de données utilisés par certains des modèles les plus notables à ce jour, en gardant à l’esprit que de nombreux développeurs ne divulguent pas les ensembles de données qu’ils utilisent.

Ensembles de données sur lesquels les LLM les plus populaires ont été entraînés.
La licence et la disponibilité des LLM
Pour une utilisation commerciale des LLM, il est impératif d’évaluer les conditions de licence associées à un modèle spécifique. De plus, la disponibilité peut être nuancée : certains modèles sont à source fermée, nécessitant un accès uniquement via leur API.
Qu’est-ce qu’un modèle de langage à source fermée ?
Un modèle à source fermée signifie que son code source n’est pas accessible publiquement. Les modèles comme GPT-3 et GPT-4 entrent dans cette catégorie, généralement accessibles uniquement via une API. Cependant, bien que l’intégration API puisse être simple, elle implique également des dépenses. En général, pour une intégration de plateforme, en fonction de l’échelle, il est plus rentable d’utiliser un modèle de langage open source et de l’entraîner ou de le déployer à l’aide d’une plateforme comme UbiOps.

API LLM de novita.ai
Qu’est-ce qu’un LLM open source ?
Un LLM open source fait référence à un modèle accessible publiquement et, sous réserve de sa licence, pouvant être utilisé à des fins commerciales. De plus, selon les termes de la licence, il peut être affiné, forké ou modifié selon les besoins. En général, pour une intégration de plateforme ou un affinage, il est conseillé d’opter pour un modèle open source.
De plus, l’exploitation des technologies open source est propice à l’avancement du domaine des LLM, car elle encourage les incitations à l’amélioration et à la personnalisation des modèles, bénéficiant finalement à l’ensemble de la communauté.
Licences commerciales
Un modèle possédant une licence commerciale est adapté à des fins professionnelles, permettant son intégration dans des plateformes commerciales.

Aperçu des LLM et de leurs licences.
Conclusion
Choisir un LLM qui correspond à vos besoins peut sembler écrasant, mais vous pouvez simplifier votre processus d’évaluation en comparant les caractéristiques clés à vos besoins. Celles-ci incluent la taille, le type, les benchmarks de qualité, les méthodologies d’entraînement, les biais et la licence. Bien que cette liste serve de point de départ, il existe de nombreux autres facteurs à considérer. Néanmoins, cet article vise à vous fournir les connaissances nécessaires pour évaluer un modèle d’IA nouvellement publié, vous permettant de déterminer son adéquation potentielle à vos besoins et de décider si une enquête plus approfondie est justifiée.
novita.ai, la plateforme tout-en-un pour une créativité illimitée qui vous donne accès à plus de 100 APIs. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, avec un paiement à l’utilisation économique, elle vous libère des tracas de maintenance GPU tout en construisant vos propres produits. Essayez-la gratuitement.
Lectures recommandées
Moteur d’inférence LLM Novita AI : le plus grand débit et l’inférence la moins chère disponibles



